AI Tools
DeepSeek V4 vs Kimi K2.6 vs Qwen3.7 Max: Which Chinese AI Model Is Actually Worth Using in 2026
In short
DeepSeek V4 costs $0.435 per million tokens, Kimi K2.6 targets agentic coding, and Qwen3.7 Max ties Opus 4.6 on benchmarks. Here's the 2026 comparison.

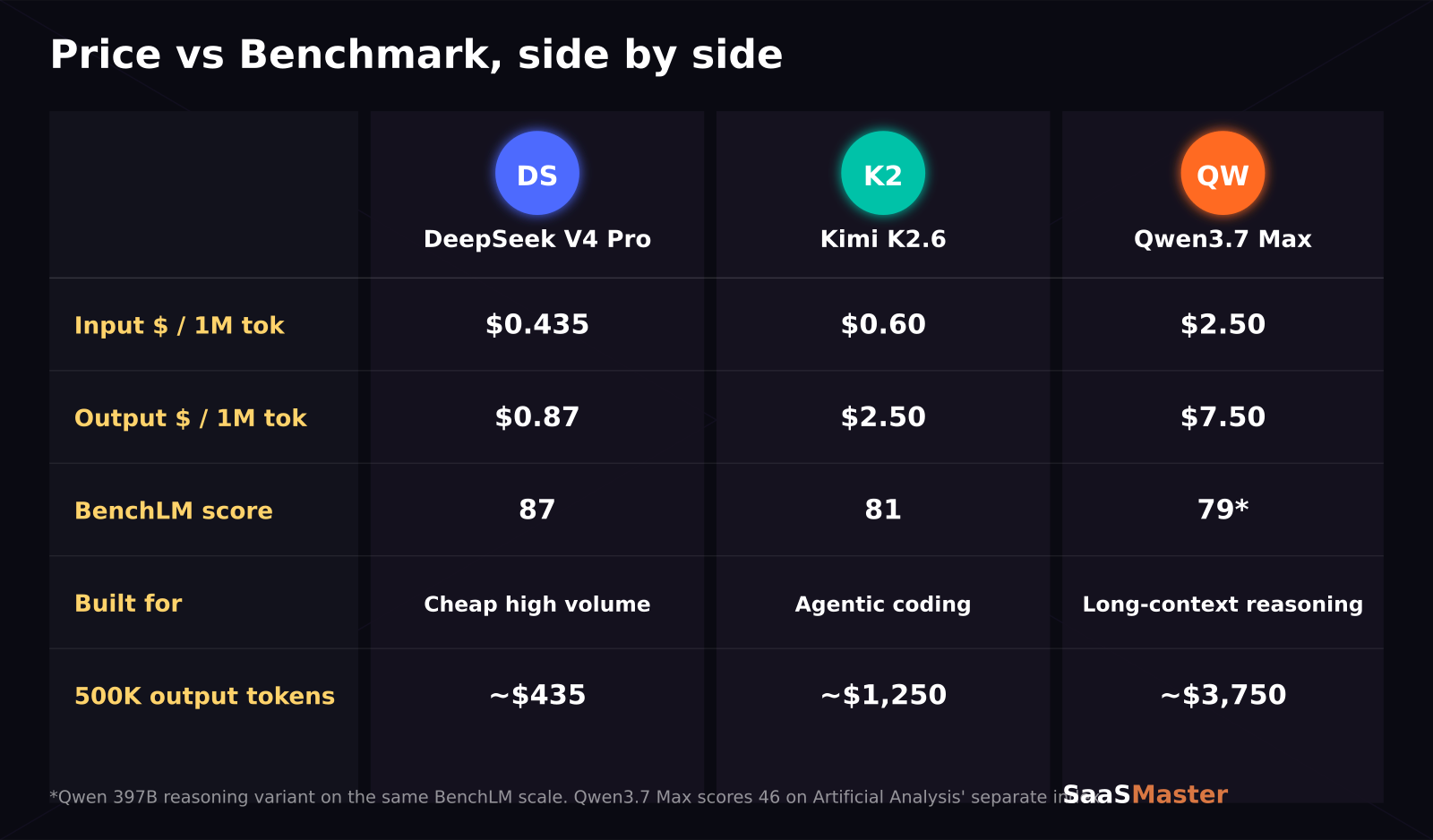
DeepSeek V4 Pro now costs $0.435 per million input tokens after a June 2026 price cut, Kimi K2.6 runs $0.60 in and $2.50 out, and Qwen3.7 Max charges $2.50 in and $7.50 out on Alibaba's own API. That's a nearly 6x spread in input pricing among three models that all claim to compete with the top closed-source labs. I've spent the past week running real tasks through all three, and the price tag is the least interesting part of this story.
Key takeaways
- DeepSeek V4 Pro tops the BenchLM Chinese-model leaderboard at a score of 87 and is the cheapest of the three by a wide margin.
- Kimi K2.6 is a 1 trillion-parameter MoE model built for agentic coding, running plan-write-test-debug loops that can stretch over days.
- Qwen3.7 Max, released May 19, 2026, wins or ties Claude Opus 4.6 on several of Alibaba's own benchmarks, particularly long-context retrieval and math.
- None of these models are "free" the way DeepSeek's chatbot is: production API pricing is real money at scale, and output tokens are where costs actually pile up.
- For most SaaS teams, the right pick depends on the job — cost-sensitive batch work, long autonomous coding sessions, or long-document reasoning each favor a different model.
I make video tutorials on AI tools for a living, which means I'm constantly swapping models mid-project to see what actually holds up outside a benchmark chart. This round of Chinese frontier models is the first time I've felt genuinely torn about which one to default to, instead of just picking whichever is cheapest.
What do DeepSeek V4, Kimi K2.6, and Qwen3.7 Max actually cost?
Here's the current API pricing, per million tokens, as of this week:
- DeepSeek V4 Pro: $0.435 input / $0.87 output (after DeepSeek's permanent June 2026 price cut)
- DeepSeek V4 Flash (the faster, lighter variant): $0.14 input / $0.28 output
- Kimi K2.6 (Moonshot AI): $0.60 input / $2.50 output
- Qwen3.7 Max (Alibaba, direct API): $2.50 input / $7.50 output — though third-party routers like OpenRouter list it closer to $1.25 / $3.75
That output-token gap matters more than people think. If you're running long agentic sessions where the model is generating pages of code, test output, and self-corrections, Qwen3.7 Max's $7.50 output rate can add up fast compared to DeepSeek's $0.87. On a 500,000-output-token coding sprint — not unusual for a multi-file refactor — that's roughly $435 on DeepSeek V4 Pro versus $3,750 on Qwen3.7 Max at list price. Kimi K2.6 lands in the middle at $1,250 for the same output volume.
Which model actually benchmarks best?
On BenchLM's Chinese-model leaderboard, DeepSeek V4 Pro currently leads at a score of 87, ahead of GLM-5.1 at 83, and Kimi K2.6 sitting at 81 alongside GLM-5's reasoning mode. Qwen's own reported numbers put its 397B reasoning variant at 79 on the same scale, though Qwen3.7 Max (the newer flagship) scores 46 on Artificial Analysis's separate Intelligence Index — a different scale entirely, which is exactly the kind of benchmark-shopping confusion that makes "just look at the score" bad advice in this category.
What I trust more than any single leaderboard number is task-specific behavior. Qwen has published internal comparisons claiming Qwen3.7 Max wins or ties Claude Opus 4.6 on long-context retrieval, math reasoning, and multilingual tasks — and in my own testing, its handling of long PDFs and multi-document research tasks was noticeably more consistent than the other two. Kimi K2.6, meanwhile, is explicitly built around agentic workflows: it's designed to run a plan-write-test-debug loop that can last for days and to instantiate hundreds of sub-agents collaborating on one task. That's a different product philosophy than "score high on a static benchmark" — it's built for autonomy over long horizons.
Which one should you actually use for coding?
If you're doing agentic, multi-step coding work — the kind where you hand off a feature request and expect the model to plan, write, run tests, and fix its own mistakes — Kimi K2.6 is the one built for that specific job. Independent write-ups have clocked it saving up to 88% on coding costs compared to closed-frontier alternatives when used through cheaper third-party hosting, because Moonshot AI licenses it more permissively than DeepSeek or Alibaba do for their top-tier models.
DeepSeek V4 Pro is still an excellent general coding model and, at under half a dollar per million input tokens, it's hard to beat for high-volume, lower-stakes tasks: linting sweeps, boilerplate generation, first-pass code review comments. I use DeepSeek as my default "cheap first pass" model precisely because a bad output costs almost nothing to throw away and retry.
Qwen3.7 Max is the one I'd reach for when the coding task is really a reasoning task in disguise — untangling a gnarly bug across a large, unfamiliar codebase where the model needs to actually hold a lot of context and reason carefully rather than iterate quickly.
Is a Chinese AI model actually good enough to replace GPT-5 or Claude for daily work?
For a lot of day-to-day SaaS work, yes — and that's the real story here, more than any single number. Six months ago, "Chinese model" meant "good enough for cheap batch work, not good enough to trust with anything important." That gap has mostly closed for reasoning and coding tasks. Where it hasn't fully closed is in the smaller stuff that matters for production software: instruction-following on edge cases, tool-calling reliability inside complex agent frameworks, and multilingual nuance outside of Mandarin and English.
My honest take after a week of daily use: I'd trust DeepSeek V4 or Kimi K2.6 with a meaningful chunk of a real SaaS company's engineering workflow today. I wouldn't yet hand either one the keys to a customer-facing agent without a human review step — not because the model is bad, but because the tooling ecosystem (evals, guardrails, observability) around the Western frontier labs is still more mature. That's an ecosystem gap, not a model-quality gap, and it's closing fast.
Which is cheaper, DeepSeek V4 or Kimi K2.6?
DeepSeek V4 Pro is cheaper on both input ($0.435 vs $0.60 per million tokens) and output ($0.87 vs $2.50 per million tokens). If your workload is high-volume and cost-sensitive, DeepSeek wins on price by a wide margin. Kimi K2.6's higher price reflects its agentic design — it's meant to run longer, more autonomous sessions where raw per-token cost matters less than task completion rate.
Where this leaves SaaS teams choosing a model this quarter
If I were picking a default model for a SaaS product's AI features today, I'd start with DeepSeek V4 Pro for cost-sensitive, high-volume features (support ticket triage, content tagging, first-draft generation), add Kimi K2.6 for any internal agentic coding or automation workflows, and keep Qwen3.7 Max on the shelf for the specific case of long-document or long-context reasoning tasks where its retrieval strength actually shows up. Running all three behind a router and picking per-task is more engineering overhead, but at these price points, testing all three on your actual workload before committing is cheap insurance.
Frequently asked questions
Is DeepSeek V4 free to use?
No. DeepSeek's consumer chat app has a free tier, but the API — which is what SaaS companies build on — costs $0.435 per million input tokens and $0.87 per million output tokens for the Pro model, or $0.14/$0.28 for the lighter Flash variant, as of the June 2026 price cut.
What makes Kimi K2.6 different from a normal chatbot model?
Kimi K2.6 is built specifically for agentic workloads. Instead of answering one prompt at a time, it's designed to run extended plan-write-test-debug loops that can continue for days and to coordinate multiple sub-agents working on pieces of the same task, which makes it better suited to autonomous coding and automation than single-turn chat.
Does Qwen3.7 Max really match Claude Opus 4.6?
On several of Alibaba's own published benchmarks — long-context retrieval, math reasoning, and multilingual tasks — Qwen3.7 Max wins or ties Opus 4.6. Independent third-party benchmarks are more mixed, and results vary a lot by task type, so it's worth testing on your specific use case rather than taking either lab's benchmark claims at face value.
Was this article helpful?
Jorge Aguilar
Founder & Creator, SaaS Master
Producing SaaS and AI product videos since 2019 — 800+ videos for 200+ brands, covering tutorials, demos, walkthroughs, and explainers. Writing here about the tools, trends, and tactics that actually move the needle. LinkedIn · About · Work with me
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
