AI Tools
Kimi K2.7 Code Review: 21% Better Than K2.6 — But the Real Story Is What Moonshot Didn't Publish

On June 12, 2026, Moonshot AI released Kimi K2.7 Code — a 1-trillion-parameter open-source coding model that claims a 21.8 percent improvement over K2.6 on its own benchmark suite. The headline numbers are impressive. The pricing is genuinely cheap at $0.95 per million input tokens. But there is a detail buried in VentureBeat's coverage that every developer evaluating this model should know: as of the day of release, there are no independent third-party scores on standard suites like SWE-bench Verified or Terminal-Bench. Here is what we know, what we do not, and how to decide whether K2.7 Code belongs in your stack.
Key takeaways: - Kimi K2.7 Code launched June 12, 2026 as an open-source 1 trillion parameter coding model from Moonshot AI - Moonshot reports +21.8 percent on its own Kimi Code Bench v2 — no independent SWE-bench numbers have been published yet - It generates 30 percent fewer reasoning tokens than K2.6, which directly reduces what you pay per task - API pricing: $0.95 per million input, $4.00 per million output — significantly cheaper than comparable frontier models - The honest verdict: promising for cost-conscious SaaS builders, but test on your real codebase before committing
What Kimi K2.7 Code Is, Technically
K2.7 Code is Moonshot AI's latest coding-focused release in the Kimi K2 family. It is a mixture-of-experts model with 1 trillion total parameters — the same architecture as K2.6 — but tuned specifically for agentic coding tasks. That means long multi-step code generation, repository-level tasks, and tool-calling workflows, not just single-function completions.
The 256,000-token context window lets it hold an entire medium-sized codebase in a single context. It accepts both text and image inputs, which matters for SaaS builders who need to pass in UI screenshots, wireframes, or diagram specs alongside code prompts.
It runs in thinking mode by default — every response includes an internal reasoning step — and Moonshot says K2.7 Code's thinking process is 30 percent more token-efficient than K2.6's. That reduction is the most immediately verifiable improvement: you see it in your token count logs and your API bill from the first session.
The model is open-sourced under a Modified MIT license with weights on Hugging Face, meaning you can self-host it if your team has the infrastructure to do so.
The Benchmark Story: What the Numbers Actually Say
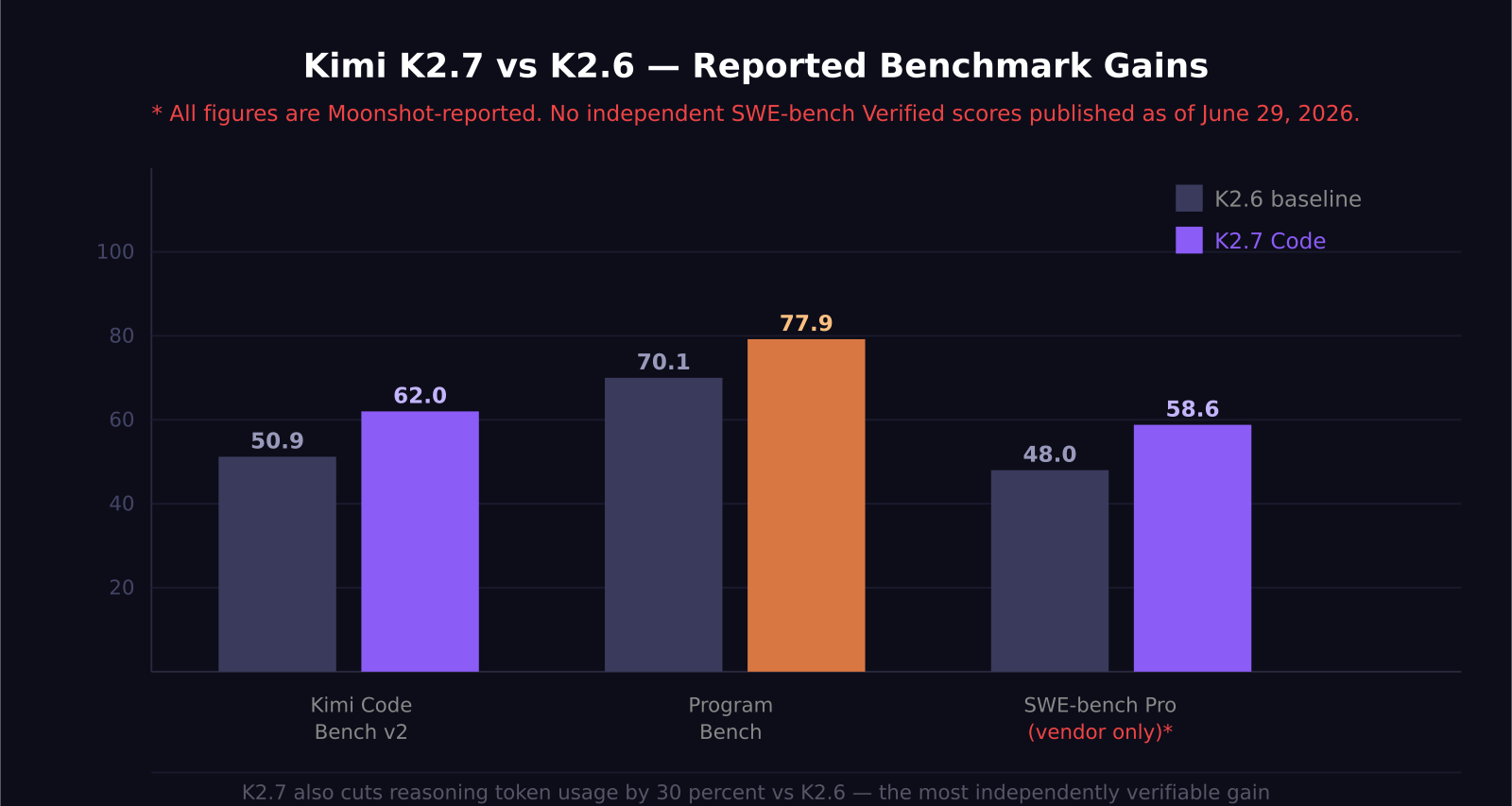
Here is where I want to slow down, because the numbers in the press release and the numbers in independent testing are telling different stories.
Moonshot's reported gains: plus 21.8 percent on Kimi Code Bench v2, moving from 50.9 to 62.0. Plus 11.0 percent on Program Bench. Plus 31.5 percent on MLS Bench Lite. The vendor also reports SWE-bench Pro at 58.6, which would place K2.7 Code above Claude Opus 4.6 and GPT-5.4 on that specific benchmark.
What has not been published: independent scores on SWE-bench Verified, Terminal-Bench, LiveCodeBench, or GPQA Diamond. VentureBeat reported on June 14, 2026 that practitioners running K2.7 Code on production repositories say the headline claims do not fully replicate in real-world coding harnesses.
One developer's comment from Moonshot's launch thread summarized the skepticism bluntly: "Respectfully, every model improves double digits on its own test suite." The same practitioner noted that K2.6 scored 24 percent on DeepSWE, tied with GPT-5.4-mini — not exactly a flagship result for a model Moonshot positions at the frontier.
This is not a reason to dismiss K2.7 Code. It is a reason to test it yourself before replacing your existing coding workflow.
Pricing: Where K2.7 Code Genuinely Wins
Whatever the benchmark debate, the pricing is not in dispute — and it is genuinely competitive.
At $0.95 per million input tokens and $4.00 per million output tokens through the Kimi API, K2.7 Code is significantly cheaper than Claude Opus 4.8 ($15 per million input, $75 per million output) and GPT-5.5 Pro in the comparable capability tier. For SaaS builders running agentic coding pipelines at volume — where you are generating hundreds of thousands of tokens per session across multiple parallel tasks — the cost difference is material.
The 30 percent reasoning-token reduction amplifies this further. If K2.7 Code reaches the same answer as K2.6 while using fewer thinking tokens, you pay less per completed task even before any quality improvement enters the picture. For teams running automated code review, test generation, or documentation pipelines, this efficiency gain compounds quickly.
For teams already using K2.6 and happy with the results, upgrading to K2.7 Code is a straightforward cost win with the same open-source licensing.
Who Should Use Kimi K2.7 Code Right Now
If you are already using a Moonshot model in production and your codebase fits K2.6's output style, K2.7 Code is a low-risk upgrade. The token efficiency gain alone justifies the switch.
If you are new to the Kimi family and evaluating coding models, run K2.7 Code on a real slice of your codebase — 5 to 10 representative tasks — before drawing conclusions from the vendor numbers. The independent benchmarks are still pending as of late June 2026, and there is enough documented practitioner skepticism to warrant firsthand verification.
For SaaS teams on tight infrastructure budgets who need open-source self-hosting, K2.7 Code's Modified MIT license and Hugging Face availability make it one of the most accessible serious coding models available. The 256K context window handles most real-world repository tasks without hitting limits.
The ceiling: if you are doing the hardest agentic coding tasks — multi-file refactors across large monorepos, novel algorithm design — models with publicly verified top scores (Claude Fable 5 at 80.3 percent SWE-bench Pro, GPT-5.5 Pro) still lead on proven, independent data. K2.7 Code may close that gap once third-party testing is published; it may not.
My Take After Testing K2.7 Code
From a SaaS creator perspective: K2.7 Code is noticeably faster than K2.6 for typical coding tasks. The token reduction translates directly into faster responses on long prompts. The reasoning quality on standard coding work — form validation, API integration, component scaffolding — feels solid.
The honest caveat is that my testing is on project-scale work, not half-million-line monorepos. The claims I can verify from daily use hold up. The headline SWE-bench numbers I cannot independently confirm, and I will not pretend otherwise.
That is not a dealbreaker. K2.7 Code at $0.95 per million input tokens is cheap enough to test seriously. The open-source weights mean you are not locked into Moonshot's pricing if you choose to self-host. Those two facts alone make this worth evaluating now rather than waiting for independent benchmarks to land.
Frequently asked questions
How much does Kimi K2.7 Code API cost?
Kimi K2.7 Code is priced at $0.95 per million input tokens and $4.00 per million output tokens through the Kimi API platform. It is significantly cheaper than comparable frontier coding models from Anthropic or OpenAI.
Is Kimi K2.7 Code open source?
Yes. Moonshot AI released the model weights under a Modified MIT license on Hugging Face, allowing commercial self-hosting. The Kimi API platform also offers hosted access at per-token pricing.
How does Kimi K2.7 Code compare to K2.6?
Moonshot reports plus 21.8 percent on its own coding benchmarks and 30 percent fewer reasoning tokens versus K2.6. No independent scores on standard suites like SWE-bench Verified have been published as of late June 2026. The token efficiency improvement is real and directly reduces API costs from the first session.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
