AI & SaaS
Why Claude Fable 5 Sometimes Answers as Opus 4.8: The Safeguards Explained

If you use Claude Fable 5 and occasionally see a note that your answer came from Opus 4.8 instead, that's not a bug — it's the safety system working as designed. Fable 5 is so capable that Anthropic wrapped it in classifiers that detect high-risk requests and quietly hand them to its next-most-capable model. It happens in under 5% of sessions, and for the other 95%+ you're getting Fable's full, unrestricted power. Here's exactly how the system works and why it exists.
I think this is one of the more interesting parts of the launch, because it shows how a lab ships a dangerous-if-misused model to the public without holding it back entirely.
Key takeaways
- Fable 5 uses separate AI "classifiers" that watch for misuse and route flagged requests to Opus 4.8 instead of answering directly.
- Covered areas: cybersecurity, biology and chemistry, and distillation (copying the model to train rivals).
- You're always told when a fallback happens; it's a redirect, not a flat refusal.
- Safeguards trigger in under 5% of sessions; more than 95% of sessions never fall back at all.
- They're tuned conservatively on purpose, so they sometimes catch harmless requests — Anthropic plans to narrow them over time.
Why such a capable model needs a gate
Fable 5 is a Mythos-class model, the most powerful tier Anthropic makes. That power is the problem. Its cybersecurity skills are strong enough to make real cyberattacks easier and cheaper; its biology reasoning is good enough to assist with genuinely dangerous research. These are "dual-use" capabilities: the same query that helps a security professional or a biologist could help a malicious actor. The concept that matters here is uplift — giving someone the ability to cause serious harm that they couldn't have gotten from, say, a normal web search.
To release a model like this to everyone, Anthropic needed a way to deliver the benefits while blocking the harmful uplift. Their answer is classifiers plus fallback.
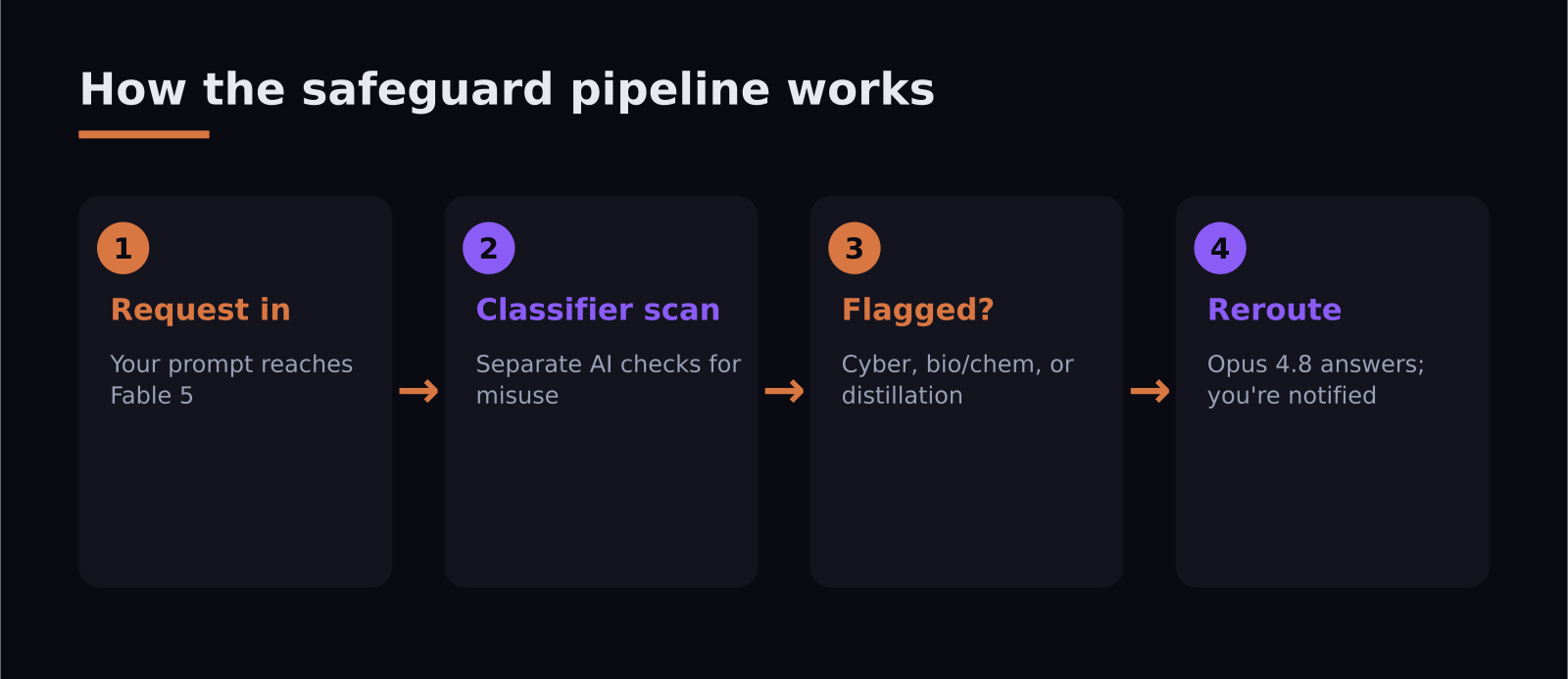
How the fallback actually works
Classifiers are separate AI systems whose only job is to detect potential misuse, including jailbreak attempts, before the main model responds. When Fable 5's classifiers flag a request as touching cybersecurity, biology/chemistry, or distillation, the request doesn't get refused — it gets answered by Opus 4.8 instead, and you're told that's what happened.
Anthropic argues this is a much better experience than an outright "I can't help with that." Opus 4.8 is itself a highly capable model, so for most flagged requests you still get a useful answer, just from a model without Mythos-class risk. And because more than 95% of Fable sessions involve no fallback, the typical user never bumps into this at all — for them, Fable performs exactly like the unrestricted Mythos 5.

The honest trade-off: false positives
Anthropic was upfront that they tuned the safeguards conservatively to ship safely and fast, which means they're stricter than ideal. Sometimes a completely benign request — a security student's legitimate question, a biology homework problem — will trip a classifier and get routed to Opus. The company acknowledges this will frustrate some users and says reducing false positives is a priority as they refine the system after launch. There's also a separate trusted-access path planned so vetted researchers can get the unrestricted capability where it's justified.
How robust is it, really?
A safeguard is only as good as its resistance to jailbreaks — clever prompts that try to bypass it. Anthropic ran an external bug bounty that produced no universal jailbreaks in over 1,000 hours of testing, and external red-teamers failed to find universal jailbreaks on long-form agentic tasks (though the UK's AI Safety Institute made some early progress). One external partner found Fable 5's safeguards the most robust of any model tested, including Opus 4.8 and 4.7. No system is perfectly unbreakable, and Anthropic says as much — the goal is to make any remaining jailbreak slow and costly enough to catch before it's used at scale. To support that, Mythos-class traffic now carries a 30-day data retention policy used only for safety, not training.
Frequently asked questions
Why did Claude Fable 5 answer as Opus 4.8?
Your request touched one of Fable 5's guarded areas — cybersecurity, biology/chemistry, or distillation — so its classifiers routed the answer to Opus 4.8 for safety. You're always notified when this happens.
How often do Fable 5's safeguards trigger?
In under 5% of sessions. More than 95% of Fable sessions involve no fallback at all, meaning most users get Fable's full capability with no interruption.
Can the safeguards be jailbroken?
Anthropic found no universal jailbreaks in over 1,000 hours of external bug-bounty testing, and one partner rated Fable 5's safeguards the most robust tested. No system is perfectly secure, but the bar is deliberately high.
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
