AI Tools
Claude Fable 5 vs GPT-5.5 vs Gemini 3.5 Flash: Which AI Is Best for SaaS Teams in 2026?

Claude Fable 5 vs GPT-5.5 vs Gemini 3.5 Flash: three frontier AI models released within weeks of each other, each with radically different pricing and priorities. The short answer is that Gemini 3.5 Flash wins on cost, GPT-5.5 wins on reasoning and long-document tasks, and Claude Fable 5 would have led on coding — except it has been offline since June 13 under a US government export-control directive.
Key takeaways
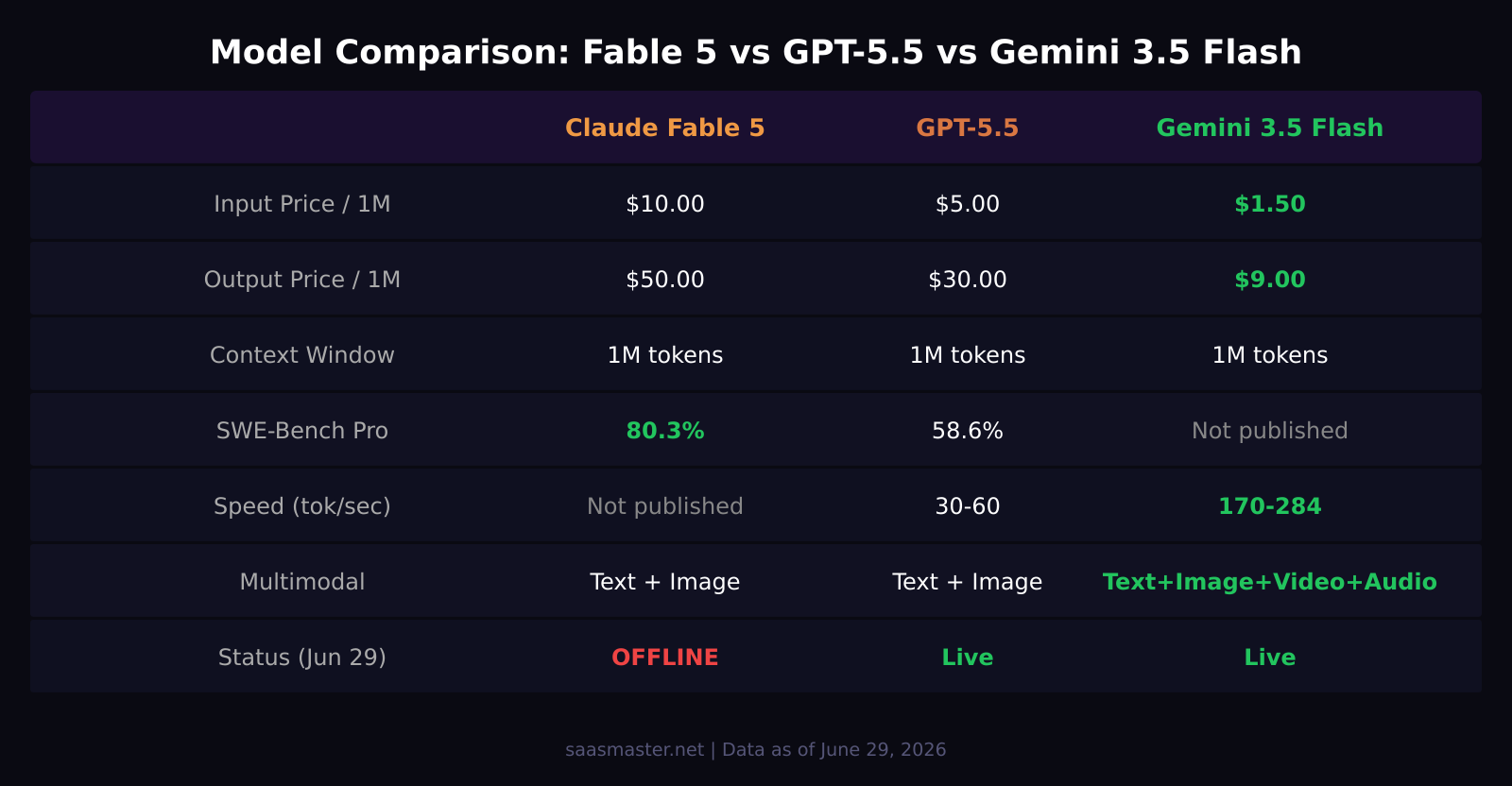
- Gemini 3.5 Flash is the cheapest frontier option at $1.50 per million input tokens — 3.3x less than GPT-5.5 and 6.7x less than Fable 5
- Claude Fable 5 scored 80.3 percent on SWE-Bench Pro, the highest in this group, but remains suspended as of June 29
- GPT-5.5 leads long-context retrieval at 74 percent on MRCR v2 and is the most capable live model right now
- Gemini 3.5 Flash is the only fully multimodal model here, processing images, video, speech, and text natively
- For SaaS teams building in production today, GPT-5.5 and Gemini 3.5 Flash are the only real choices
The three models at a glance
Claude Fable 5 launched on June 9, 2026, and was immediately the most capable model Anthropic had ever released publicly. Built on the Claude Mythos architecture, it scored 80.3 percent on SWE-Bench Pro. Its context window is 1 million tokens with up to 128k output tokens per request. API pricing is $10 per million input tokens and $50 per million output tokens.
Four days after launch, the US Commerce Department ordered Anthropic to suspend both Fable 5 and Mythos 5 under the Export Administration Regulations. The directive cited a discovered jailbreak that could expose Mythos capabilities in cybersecurity, biology, and chemistry. As of June 29 — Day 17 of the outage — both models remain offline for all general users. A partial restoration happened on June 27 for more than 100 critical infrastructure organizations in the US, but general API access has not returned.
GPT-5.5 launched on April 23, 2026, became the default ChatGPT model on May 5, and has run without incident since. Pricing is $5 per million input tokens and $30 per million output tokens. Its Batch API cuts rates in half: $2.50 input and $15 output per million. The 1 million token context window and 74 percent score on MRCR v2 make it the strongest live option for long-document workflows.
Gemini 3.5 Flash reached general availability on May 19 at Google I/O 2026. It is the fastest and cheapest model in this group: $1.50 input and $9 output per million tokens. It generates text at up to 284 tokens per second — roughly four times faster than other frontier models at their standard load — and supports a 1 million token context window. It is also the only fully multimodal option here, handling video, audio, images, and text in a single API call.
Which is cheaper, GPT-5.5 or Gemini 3.5 Flash?
At standard API pricing, Gemini 3.5 Flash is the clear winner at $1.50 per million input tokens. GPT-5.5 is $5. Claude Fable 5 was $10. For every dollar spent on Gemini 3.5 Flash, you would spend $3.33 on GPT-5.5 or $6.67 on Fable 5. At production scale — millions of tokens per day — the difference adds up fast.
GPT-5.5 partially closes the gap through the Batch API, where rates drop to $2.50 input and $15 output per million for non-real-time jobs. This makes GPT-5.5 competitive for batch processing, nightly analysis pipelines, or bulk content generation. Gemini 3.5 Flash does not have a comparable batch pricing tier.
How do the benchmarks compare?
Claude Fable 5 leads SWE-Bench Pro at 80.3 percent — a meaningful jump from GPT-5.5's 58.6 percent. That gap matters for teams building AI coding assistants or running software-engineering agents. GPT-5.5 counters with strong agentic performance: 83.4 percent on Terminal-Bench 2.1 and 78.7 percent on OSWorld-Verified. Gemini 3.5 Flash was benchmarked as beating Gemini 3.1 Pro on coding and agentic tasks despite being positioned as the speed-first model.
The catch is that Fable 5's 80.3 percent score is a benchmark, not a service you can ship against right now. GPT-5.5's numbers are lower, but they belong to a model that is actually running.
Where Gemini 3.5 Flash pulls ahead
Speed matters for user-facing SaaS features. At up to 284 tokens per second, Gemini 3.5 Flash is significantly faster than GPT-5.5 in real-time applications — chat interfaces, instant summaries, live analysis — where output latency is a user experience factor, not just an engineering metric.
The multimodal advantage is also real for certain product categories. If your SaaS tool needs to process screen recordings, analyze uploaded video, or handle audio from customer interviews, Gemini 3.5 Flash handles all of that natively in one API call. GPT-5.5 handles images alongside text; it does not natively process video or audio.
The Fable 5 factor
Building a production roadmap around a model suspended under export-control law is a risk worth pricing in explicitly. Anthropic is negotiating its return, and leaked code suggests preparation for a restricted consumer rollout. But no timeline has been announced, and the government's willingness to take a domestic commercial model offline for 17-plus days should inform how SaaS teams think about AI model dependency going forward.
The lesson this outage has reinforced for hundreds of product teams: build model-agnostic routing from day one. A thin abstraction layer that lets you swap providers without touching product logic is not over-engineering. It is table stakes after June 2026.
My take as a creator
I have worked with SaaS companies on AI-powered tutorials, product walkthroughs, and content pipelines, and the Fable 5 situation is the most disruptive AI event at the product layer that I have seen. Teams that over-indexed on a single model got burned fast. The good news is that the fallback options are genuinely strong: GPT-5.5 covers most workloads well, and Gemini 3.5 Flash is excellent for cost-sensitive or multimodal use cases.
When Fable 5 returns, it will be worth a rigorous evaluation for anything code-heavy or agent-driven. Until then, the two live models in this comparison are both worth their price.
Frequently asked questions
Is Claude Fable 5 available right now?
No. As of June 29, 2026, Claude Fable 5 remains offline for all general users following the US Commerce Department export-control directive issued on June 13. Anthropic has not announced a public return date. Check isfableback.org for live status updates.
What is the cheapest tier-one AI API in mid-2026?
Gemini 3.5 Flash at $1.50 per million input tokens is currently the most affordable frontier option. GPT-5.5 via the Batch API at $2.50 per million input tokens is a strong second for non-real-time workloads.
Should I use GPT-5.5 or Gemini 3.5 Flash for my SaaS product?
Choose GPT-5.5 if your use case is reasoning-heavy, document-based, or requires the highest live coding benchmark. Choose Gemini 3.5 Flash if cost is a constraint, your product needs multimodal processing, or you need the fastest real-time output speeds available today.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
