AI Tools
Claude Sonnet 5 vs GPT-5.6 vs Gemini 3.5 Pro: Which AI Model Should You Actually Build On?
In short
Claude Sonnet 5, GPT-5.6 Sol, and Gemini 3.5 Pro compared on pricing, benchmarks, and real-world availability for SaaS teams shipping products in 2026.

Claude Sonnet 5 is the best all-around pick for most SaaS teams right now, mainly because it is the only one of these three you can fully access today. GPT-5.6 Sol posts the strongest raw benchmark numbers but is locked to roughly 20 approved partners, and Gemini 3.5 Pro has slipped its own general availability past the June 30, 2026 target Google set at I/O. This piece breaks down pricing, benchmarks, and access so you can decide what to actually build on this quarter.
Key takeaways
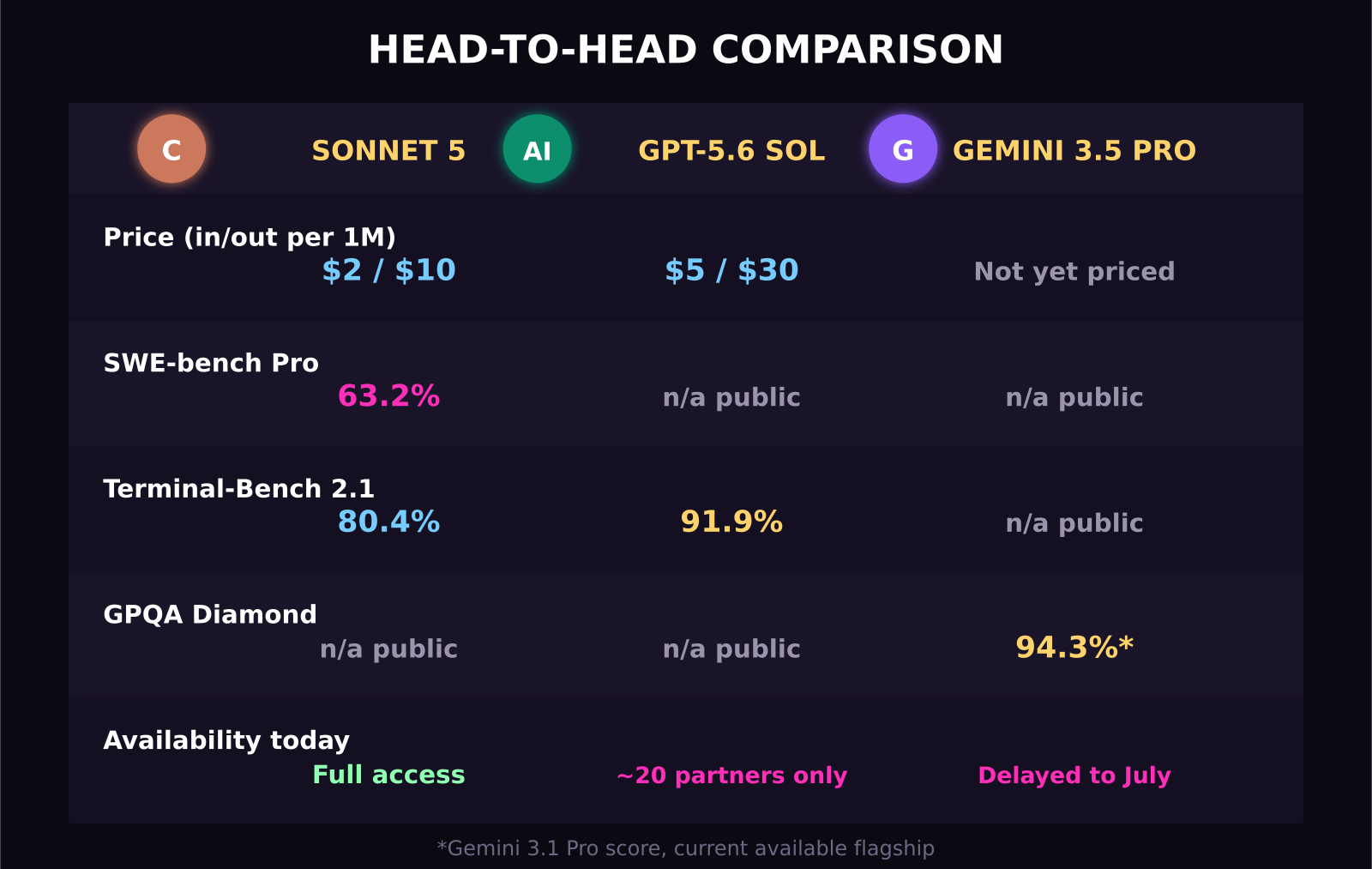
- Claude Sonnet 5 costs 2 dollars in / 10 dollars out per million tokens through August 31, 2026, then rises to 3 in / 15 out.
- Sonnet 5 beats GPT-5.5 and Gemini 3.5 Flash on SWE-bench Pro, 63.2 percent versus 58.6 and 55.1.
- GPT-5.6 Sol Ultra posts 91.9 percent on Terminal-Bench 2.1, the highest published score of the three, but access is restricted to around 20 partners.
- Gemini 3.5 Pro targets a 2 million token context window and a Deep Think reasoning mode, but general availability has slipped into July 2026.
- Gemini 3.1 Pro still leads on GPQA Diamond at 94.3 percent, the strongest reasoning score in this comparison.
- If you need something you can ship with this week, Sonnet 5 is the only fully available option among the three flagship-tier releases.
What is actually available to build on today?
This is the question that matters most, and it is not close. Claude Sonnet 5 launched June 30, 2026, with full API access and published benchmarks across the board. GPT-5.6 Sol, Terra, and Luna are in a preview restricted to about 20 US government-approved partner organizations, with no ChatGPT access and no GA date. Gemini 3.5 Pro was announced at Google I/O on May 19, 2026, targeted for June GA, and that date has come and gone, with Google citing quality refinements and now pointing to July.
If your evaluation criteria include "can my team use this in production this month," Sonnet 5 wins by default, not because the other two are worse models, but because they are not shipping products yet.
How does pricing compare?
Per million tokens:
- Claude Sonnet 5: 2 dollars in / 10 dollars out (introductory, through August 31, 2026), then 3 in / 15 out
- Claude Opus 4.8, for reference: 5 in / 25 out
- GPT-5.6 Sol: 5 in / 30 out
- GPT-5.6 Terra: 2.50 in / 15 out
- GPT-5.6 Luna: 1 in / 6 out
- Gemini 3.5 Pro: not yet publicly priced at GA
Sonnet 5's introductory pricing undercuts Sol by a wide margin while landing in genuinely competitive territory with GPT-5.6 Terra, a mid-tier model, not OpenAI's flagship. That is a meaningful positioning win for Anthropic: Sonnet 5 is priced like a mid-tier model but benchmarks like it is closing the gap with its own flagship, Opus 4.8.
Who wins on coding and agent benchmarks?
It depends which benchmark you weight. On SWE-bench Pro, an agentic coding benchmark, Sonnet 5 leads clearly: 63.2 percent versus GPT-5.5's 58.6 percent and Gemini 3.5 Flash's 55.1 percent. Note this is GPT-5.5, not GPT-5.6, since Anthropic's own system card was published before GPT-5.6 launched and does not include head-to-head numbers against it.
On Terminal-Bench 2.1, a benchmark focused on real terminal and shell tasks, the picture flips depending on which models you compare. GPT-5.5 actually edges Sonnet 5, 83.4 percent versus 80.4 percent. But GPT-5.6 Sol Ultra reportedly scores 91.9 percent on the same benchmark, ahead of every Claude model on record, including Opus 4.8 at 78.9 percent. That is the strongest data point in OpenAI's favor in this entire comparison, and it is also the one attached to the most access restrictions.
For general agent and browsing tasks, Sonnet 5 posts 84.7 percent on BrowseComp and 81.2 percent on OSWorld-Verified, both close behind Opus 4.8's 83.4 percent on OSWorld, showing Sonnet 5 has closed most of the gap to Anthropic's own flagship at a much lower price.
Who wins on reasoning and research?
Gemini 3.1 Pro, the currently available Gemini flagship while 3.5 Pro remains in limited preview, leads this category outright with a 94.3 percent score on GPQA Diamond, a graduate-level science reasoning benchmark. That is the single clearest advantage any model holds in any category across this whole comparison. If your product leans on interpreting research papers, answering expert-level medical or scientific questions, or running structured multi-step analysis, Gemini's reasoning strength is worth the wait for 3.5 Pro, or the use of 3.1 Pro today.
Gemini 3.5 Flash, the smaller model already shipping ahead of Pro, already beats 3.1 Pro on several agent-style benchmarks: Terminal-Bench 2.1 (76.2 versus 70.3 percent) and MCP Atlas (83.6 versus 78.2 percent). It still trails on long-context retrieval past 128k tokens and on the hardest reasoning benchmarks like Humanity's Last Exam and ARC-AGI-2, where 3.1 Pro keeps a real lead.
What about context window and multimodal work?
Gemini 3.5 Pro is aiming for a 2 million token context window plus a Deep Think reasoning mode, and it absorbs the use cases Google previously reserved for a separate "Ultra" tier: the hardest reasoning tasks, deep multimodal understanding, and very long documents. Once it actually ships, that combination of context length and multimodal range is likely to be the strongest argument for choosing Gemini over Claude or GPT-5.6 for document-heavy or research-heavy products. Right now, in July 2026, that argument is still theoretical, because Pro has not shipped.
So which one should you actually build on?
For most SaaS teams shipping product this quarter, Claude Sonnet 5 is the practical answer: full availability, competitive-to-leading agentic coding scores, and pricing that undercuts everything except OpenAI's smallest tier. If your workload is reasoning-heavy or research-heavy, keep an eye on Gemini 3.5 Pro's actual GA date, and evaluate Gemini 3.1 Pro in the meantime for GPQA-style tasks. If you happen to be one of the roughly 20 organizations with GPT-5.6 access, Sol's Terminal-Bench score is the best in the field, but that is not a decision most builders get to make yet.
What does "closing the Opus gap" actually mean for your product?
Sonnet 5's most useful trait is not any single benchmark win, it is how close it now sits to Anthropic's own flagship. On OSWorld-Verified, Sonnet 5 scores 81.2 percent against Opus 4.8's 83.4, a 2.2 point gap. On Terminal-Bench 2.1, Sonnet 5 actually beats Opus 4.8, 80.4 versus 74.6. On GDPval-AA v2 knowledge work, Sonnet 5's 1,618 Elo edges past Opus 4.8's 1,615. That means for a large share of production SaaS workloads, agentic workflows, customer-facing knowledge tasks, terminal and dev-tool automation, you are no longer paying a real performance tax to use the cheaper model. That is a different situation than a year or two ago, when picking the budget-tier model usually meant a visible capability cut.
The practical implication: architect your product to default to Sonnet 5 for the bulk of agentic and knowledge work, and reserve Opus 4.8 selectively for the narrow slice of tasks, deep research, the hardest multi-step judgment calls, where its remaining edge is actually worth the roughly 2.5x cost premium.
What should enterprise buyers watch for next?
Three things worth tracking over the next month: whether GPT-5.6 Terra and Luna get independently benchmarked once broader access opens, since OpenAI's own claims about matching GPT-5.5 performance at lower cost have not yet been verified by third parties; whether Gemini 3.5 Pro actually hits its now-slipped July target, given it already missed one public deadline; and whether Anthropic publishes a direct Sonnet 5 versus GPT-5.6 comparison once Sol reaches wider availability, since the current picture is stitched together from separate system cards that were not tested against each other on identical conditions.
Frequently asked questions
Is Claude Sonnet 5 better than GPT-5.6 Sol?
On the one published head-to-head benchmark, Terminal-Bench 2.1, GPT-5.6 Sol Ultra scores higher (91.9 percent versus Sonnet 5's 80.4 percent). But Sol is restricted to around 20 approved partners with no general access, while Sonnet 5 is fully available today at a lower price, which makes Sonnet 5 the more practical choice for almost every team.
When will Gemini 3.5 Pro be available?
Google originally targeted June 2026 for general availability, announced at I/O on May 19, 2026. That date passed without a public launch, and Google has since pointed to July 2026, citing quality refinements after early enterprise testing.
Which model is cheapest for high-volume tasks?
GPT-5.6 Luna is the cheapest of the group at 1 dollar input and 6 dollars output per million tokens, though it is currently limited to the same restricted preview access as Sol and Terra. Among fully available models, Claude Sonnet 5's introductory pricing of 2 in / 10 out is the strongest value through August 31, 2026.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master