AI Tools
DeepSeek V4 vs Kimi K2.6 vs Qwen 3.7 Max: China's AI Models Are Cheaper Than You Think

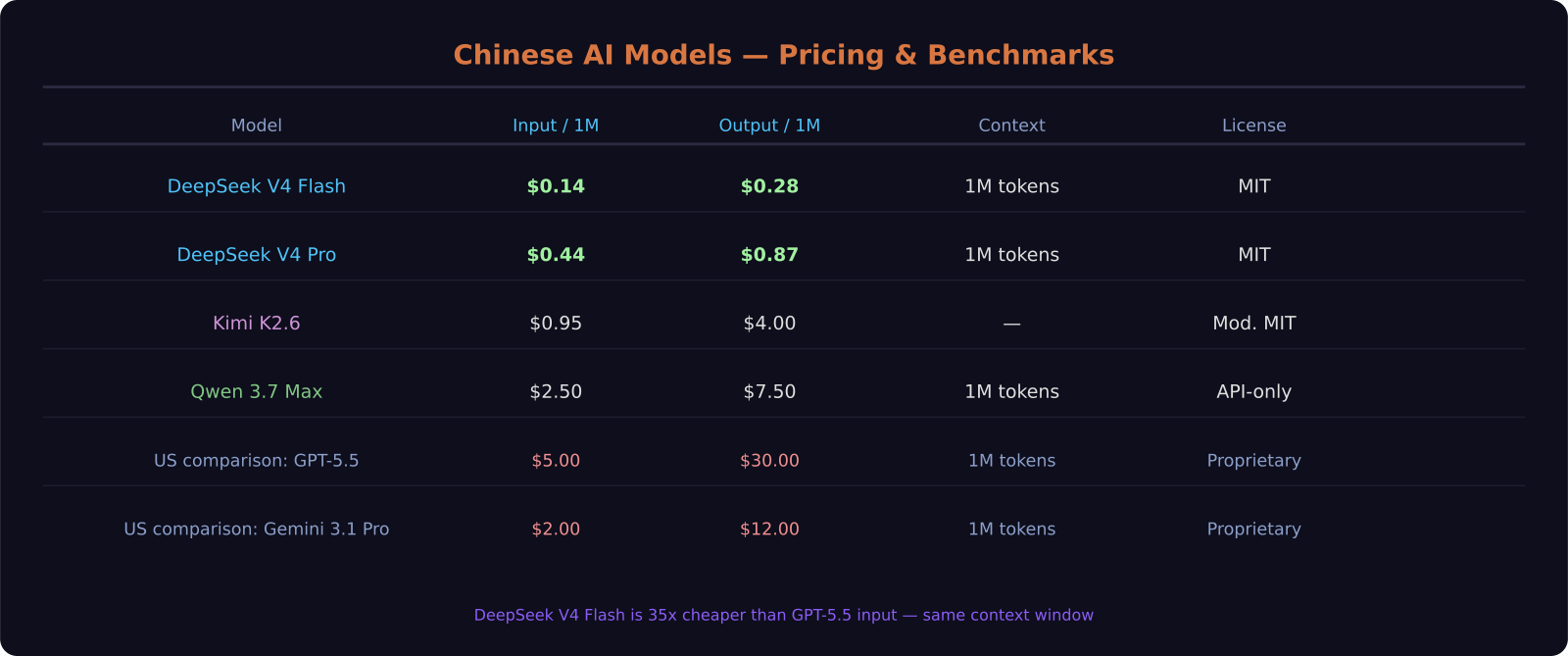
DeepSeek V4 Flash costs $0.14 per million input tokens. GPT-5.5 costs $5.00 per million input tokens. That is a 35x price difference for a model with the same 1 million token context window — and it is open source under MIT. If you have not looked at Chinese AI models since the DeepSeek R1 moment, the landscape has shifted further than you might expect. Here is where things actually stand.
Key takeaways
- DeepSeek V4 Flash is the cheapest capable AI API available at $0.14/$0.28 per million input/output tokens, 35x cheaper than GPT-5.5
- Kimi K2.6 became the first open-weight model to beat GPT-5.4 on SWE-bench Pro — a significant milestone for open-source coding models
- Qwen 3.7 Max ran autonomously for 35 hours straight, firing 1,158 tool calls, in Alibaba's internal agentic coding test
- All three are available on OpenRouter — no China-based account required
- The best Chinese models trail the top US frontier tier by roughly 9 aggregate points, but the gap is closing faster than predicted
Why Chinese AI got interesting again in 2026
The first DeepSeek moment was a shock — a small Chinese lab released R1 with performance matching o1 at a fraction of the cost. What followed was a year of relentless iteration. DeepSeek, Moonshot AI, and Alibaba have each shipped multiple major model versions, and the cumulative effect is that in mid-2026, you have three distinct Chinese models that are legitimately worth evaluating against GPT-5.5 and Gemini 3.1 Pro depending on your use case.
The common thread: all three are open-weight or open-source, all are available on OpenRouter, and all undercut US proprietary models on price by a substantial margin.
DeepSeek V4: the price floor for capable AI
DeepSeek V4 comes in two variants. Flash is the headliner on cost: $0.14 per million input tokens and $0.28 per million output tokens. That is not a typo. A model with a 1M context window and genuinely competitive capability for less than the cost of a cup of coffee per billion tokens. The V4 Pro variant steps up to $0.44/$0.87 — still under half the price of Gemini 3.1 Pro and nearly 12x cheaper than GPT-5.5 input.
DeepSeek V4-Pro pricing was locked in permanently on May 22, 2026. Both variants carry MIT licenses, meaning you can deploy the weights yourself if you have the infrastructure, with no usage restrictions. Caching cuts the price further — cache-hit pricing on V4 Pro lands at $0.003625 per million tokens.
On Codeforces, V4 sits at 2121 Elo — roughly the 96th percentile. The R2 reasoning traces that power that score are baked in, so you do not need to run a separate reasoning model step. For high-volume applications where GPT-5.5 would be prohibitively expensive, DeepSeek V4 Flash is the model that changes the math.
Kimi K2.6: the open-weight model that beat GPT-5.4
Kimi K2.6 is an unusual model to explain without sounding like hyperbole. It has 1 trillion total parameters but only 32 billion active per token through a Mixture-of-Experts architecture. It launched April 20, 2026 under a Modified MIT license. And it became the first open-weight model to beat GPT-5.4 on SWE-bench Pro.
That benchmark result matters because SWE-bench Pro is one of the hardest coding evaluations available — it tests real-world software engineering tasks, not sanitized code puzzles. For an open-weight model to surpass a proprietary frontier model on that benchmark is a meaningful milestone. The MATH-500 score sits at 97.4%, at the top of what any model — open or closed — has posted.
Kimi K2.6 is natively multimodal, which differentiates it from DeepSeek V4. Pricing is $0.95 per million input tokens and $4.00 per million output tokens. The output price is higher than DeepSeek's by a significant margin, which matters for applications where the model generates long responses — though automatic context caching reduces repeated context costs to approximately $0.19 per million hit-rate tokens.
If you are building agentic coding tools, autonomous research assistants, or anything that needs to process and generate long technical content while staying open-weight, Kimi K2.6 is the strongest Chinese option.
Qwen 3.7 Max: Alibaba's agentic endurance test
Qwen 3.7 Max launched May 20, 2026 at the Alibaba Cloud Summit in Hangzhou. It is the current flagship from Alibaba's Qwen team — API-only, with a 1 million token context window up from 256K on Qwen 3.6 Max.
The benchmark that stands out is GPQA Diamond at 92.4%, placing it in the range of Gemini 3.1 Pro and Claude Opus 4.6 on scientific reasoning. SWE-bench Pro at 60.6% and Terminal-Bench 2.0 at 69.7% are competitive with the second tier of frontier models. The Artificial Analysis Intelligence Index placed it at 56.6 at launch — top 10 of 151 measured models that week.
But the number people keep citing is the 35-hour autonomous coding run. Alibaba's internal testing had Qwen 3.7 Max running a single coding task autonomously for 35 hours, firing 1,158 tool calls, and delivering a 10x speedup over the standard Triton reference implementation. That is not a benchmark — it is a real-world demonstration of what extended agentic use looks like at scale. Whether your workflows approach that duration or not, it establishes that the model does not degrade or hallucinate its way into collapse over long autonomous sessions the way earlier models did.
Pricing is $2.50/$7.50 per million input/output tokens with a 90% discount on cached input ($0.25 per million). It is available through Alibaba Cloud Model Studio and OpenRouter.
So which one should you actually use?
For high-volume, cost-sensitive applications where you need broad capability and do not specifically need multimodal input: DeepSeek V4 Flash. The $0.14 input price is transformative for products where you were previously budget-constrained by model costs.
For open-weight agentic coding, autonomous development tasks, or anything where you want to self-host the weights: Kimi K2.6. Its SWE-bench Pro performance is the best publicly available from any open-weight model.
For long-context scientific and technical reasoning where you need strong benchmark performance and are comfortable with API-only access: Qwen 3.7 Max. The GPQA Diamond score and the agentic endurance story make it compelling for research and technical SaaS applications.
All three are available on OpenRouter, which means you can swap between them without changing your API integration.
The creator take
I cover AI tools for builders and SaaS teams, and the honest observation is this: the price compression from Chinese open-source models is now affecting what US model providers can charge. Gemini 3.1 Pro at $2.00 per million input tokens was considered aggressive pricing a year ago. DeepSeek V4 Flash at $0.14 makes it look expensive. That dynamic is going to keep reshaping the market throughout 2026, and builders who ignore these models for geopolitical rather than technical reasons are leaving real money on the table.
Frequently asked questions
Are Chinese AI models safe to use in production?
DeepSeek, Kimi, and Qwen are all available through established API providers including OpenRouter, Fireworks, and Baseten, which means you can access the models without sending data directly to China-based servers. Enterprise users should review the specific data processing terms for whichever provider they use. Qwen 3.7 Max is API-only through Alibaba Cloud, which has different data residency considerations.
How does DeepSeek V4 compare to GPT-5.5 on benchmarks?
DeepSeek V4 Pro scores at approximately the 96th percentile on Codeforces (2121 Elo) and delivers strong performance on general reasoning tasks. GPT-5.5 leads on SWE-bench Verified (88.7%) and agentic coding. For the price gap — $0.44 vs $5.00 per million input tokens — DeepSeek V4 Pro offers exceptional value for most non-frontier use cases.
Which Chinese AI model is best for coding in 2026?
Kimi K2.6 leads on coding benchmarks, having become the first open-weight model to beat GPT-5.4 on SWE-bench Pro, with a MATH-500 score of 97.4%. For budget-first coding tasks, DeepSeek V4 Flash at $0.14 per million tokens handles a wide range of coding use cases competently. Qwen 3.7 Max at 60.6% SWE-bench Pro is the strongest on agentic long-running coding sessions.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
