AI Tools
MiniMax M3: The Chinese Open-Source Model That Just Outbenchmarked GPT-5.5 on Code

A Chinese open-source model just outscored GPT-5.5 on the industry's hardest software engineering benchmark — and it costs roughly 5 to 10 percent of what OpenAI charges per API call. MiniMax, a Shanghai-based AI lab that has been quietly building toward this moment, launched M3 on June 1, 2026, as the first open-weight model to combine frontier-level coding performance, a one-million-token context window, and native multimodal support in a single package. Here is what it is, what it actually does, and whether the benchmark claims hold up.
Key takeaways:
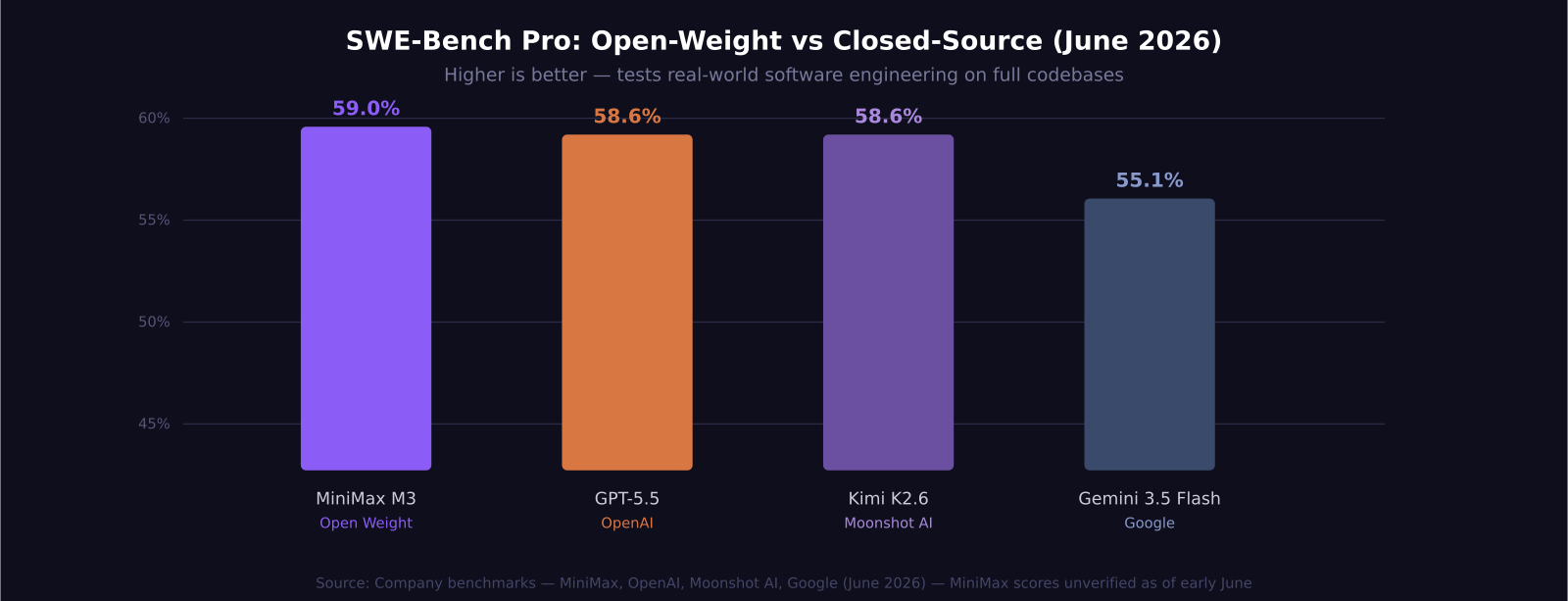
- MiniMax M3 scored 59.0% on SWE-Bench Pro, narrowly edging past GPT-5.5 (58.6%) and Kimi K2.6 (58.6%) on the most demanding real-world coding benchmark in current use.
- It is the first open-weight model to combine a 1-million-token context window with native multi-modal computer use — accepting text, image, and video inputs.
- MiniMax reports API pricing at 5 to 10 percent of GPT-5.5 and Gemini 3.1 Pro costs, making it dramatically cheaper for high-volume coding and document workloads.
- The M3 benchmarks were company-reported and had not been independently verified as of early June 2026; open weights were promised by approximately June 11.
- M3 joins DeepSeek V4 and Kimi K2.6 in a cluster of Chinese open models now competitive with top US closed-source models on coding benchmarks.
What is MiniMax and why does M3 matter?
MiniMax is one of China's leading foundation model labs, operating alongside DeepSeek, Moonshot AI (which makes Kimi), and Alibaba's Qwen team. Unlike some of those better-known names, MiniMax has focused on combining multimodal capabilities with strong language modeling — the company also makes Hailuo AI, a video generation tool that competed with Runway and Kling. M3 is its most ambitious release.
What makes M3 notable is the specific combination it ships: frontier coding performance, a one-million-token context window, and native support for text, image, and video input, all in an open-weight model available for self-deployment. Until M3, that combination did not exist. DeepSeek V4 Pro has strong coding and long context but different multimodal coverage. Kimi K2.6 is a one-trillion-parameter vision-language model with competitive benchmark scores but a different architectural profile. M3 claims to close those gaps in a single release.
The model uses what MiniMax calls MSA — Multi-Stage Attention — an architectural design the company says enables efficient long-context reasoning without the memory degradation that typically affects quality at context lengths beyond 200,000 tokens.
How does M3 actually compare on benchmarks?
MiniMax reports the following scores for M3 at launch:
- SWE-Bench Pro: 59.0% — testing models on real GitHub repositories with actual bug fixes required.
- Terminal-Bench 2.1: 66.0% — measuring command-line tool use and agent performance.
- SWE-fficiency: 34.8%
- BrowseComp: 83.5%
For context: GPT-5.5 scores 58.6% on SWE-Bench Pro; Kimi K2.6 (released in April 2026) scores 58.6% on the same benchmark. M3's 59.0% puts it at the top of the open-weight leaderboard and just above two well-funded closed-source models from US labs. Gemini 3.5 Flash — the strongest performance-per-dollar model Google currently offers — scores 55.1% on SWE-Bench Pro, putting M3 roughly four points ahead on that test.
The 66.0% on Terminal-Bench 2.1 is a strong result for any model in the agentic coding category and suggests M3 is genuinely built for agent workflows that interact with command-line environments, not just document summarization.
What does M3 cost to run?
MiniMax has not published per-token API prices in the same transparent format that OpenAI and Google use, but the company and multiple third-party analyses place API call costs at 5 to 10 percent of what you would pay for GPT-5.5 or Gemini 3.1 Pro on equivalent tasks. That is a significant cost advantage for any developer running coding or long-context workloads at volume.
The model is also being released as open weights under a permissive license, which means developers who can run their own inference infrastructure could in theory deploy M3 at hardware cost only — removing the API margin entirely. The open-weight release was scheduled for approximately June 11, 2026. As of early June the API was live but the downloadable weights had not yet shipped.
For comparison: DeepSeek V4-Pro, the most direct competitive comparison among Chinese open-weight models, is available via the DeepSeek API with 1M-token context and MIT licensing, and has been independently verified by the community since its April 2026 release.
Should you trust the benchmarks?
Carefully — and that caveat applies to every frontier model launch, not just M3. The M3 scores are self-reported by MiniMax. As VentureBeat noted directly in their coverage of the launch: the benchmark scores had not been independently replicated as of early June 2026, and the open weights had not yet shipped, meaning the research community could not run its own verification at launch time.
That situation is standard for first-week frontier releases. OpenAI, Google, and Anthropic all publish self-reported benchmark results before independent evaluators can test them. The meaningful difference with M3 is that the open-weight release delay meant even researchers with hardware access could not verify the claims immediately.
The model is live via the MiniMax API. Developers can run evaluations on tasks from their actual use case — which is always more meaningful than published benchmark scores for a specific workload. Independent verification on platforms like Artificial Analysis and LMSYS Chatbot Arena is likely within weeks of the open weights becoming available.
What this says about the Chinese AI landscape in 2026
M3 is the latest in a pattern that has been building through 2025 and into 2026: Chinese AI labs releasing models that benchmark at or near US closed-source frontiers, at open-weight prices. DeepSeek V4-Pro and V4-Flash both ship under the MIT license with 1M-token API context. Kimi K2.6 is a trillion-parameter vision-language model. Qwen 3.6 Max runs at Alibaba Cloud pricing.
What is different about M3 is the timing and the specific combination it targets. It arrives as Claude Opus 4.8 holds the top benchmark spot at 61.4 on the Artificial Analysis Intelligence Index — the first model to break 60 by a clean margin — and as GPT-5.5 has cut its hallucination rate under 9 percent. The gap between US frontier models and Chinese open-weight challengers is now measured in single-digit benchmark percentage points.
For developers building on open infrastructure, or working within cost constraints that make $5-per-million-token pricing prohibitive, the practical question is no longer whether Chinese open models are good enough. It is which model fits the specific use case. M3's combination of strong coding performance, multimodal input, and long context makes it a serious option for agent pipelines, code review tools, and document analysis systems — once the open weights are verified.
Frequently asked questions
Is MiniMax M3 better than GPT-5.5?
On SWE-Bench Pro, M3 scores 59.0% against GPT-5.5's 58.6% — a narrow lead. GPT-5.5 likely maintains advantages in hallucination reduction (8.9% rate on OpenAI's internal benchmark) and response reliability for non-coding tasks. M3's primary edge is cost: the dramatically lower API price and planned open-weight release make it more practical for high-volume coding and document workloads where the cost per token matters.
When will the MiniMax M3 open weights be available?
MiniMax announced the open-weight release for approximately June 11, 2026. As of early June, the API was live but the downloadable model weights had not shipped. Check MiniMax's Hugging Face organization page and the MiniMax developer blog for confirmation.
Who is MiniMax and what else do they make?
MiniMax is a Shanghai-based AI research lab founded in 2021. Alongside large language models, the company operates Hailuo AI, a text-to-video generation product that has competed with Runway and Kling in the short-form video generation space. M3 is MiniMax's first model to directly challenge US frontier closed-source models on coding and software engineering benchmarks.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
