AI Tools
Gemini 3.5 Flash vs GPT-5.5: Which AI API Should You Build With in 2026?

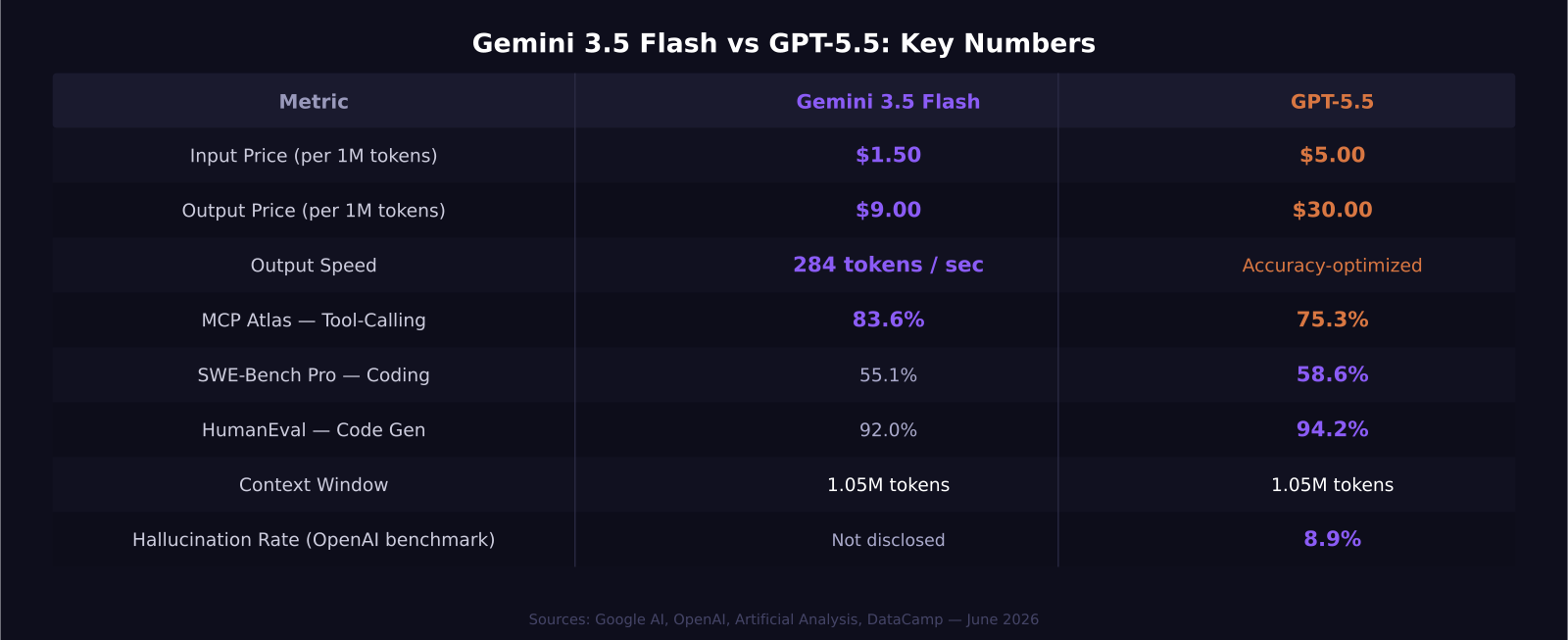
For most production API workloads in 2026, Gemini 3.5 Flash is the more cost-effective choice — it runs at $1.50 per million input tokens versus GPT-5.5's $5.00, outputs tokens four times faster, and beats OpenAI's flagship on multi-step agentic tasks. GPT-5.5 still leads on pure software engineering and has shipped the lowest hallucination rate OpenAI has ever measured, making it the right call when quality matters more than throughput. Here is how both models actually perform when you run real workloads on them.
Key takeaways:
- Gemini 3.5 Flash costs $1.50 per million input tokens; GPT-5.5 costs $5.00 on the API — a 3x difference on input, wider on output ($9 vs $30).
- Flash generates tokens at 284 per second — roughly 4x faster than competing models — and outperforms GPT-5.5 on multi-step tool-calling (83.6% vs 75.3% on MCP Atlas).
- GPT-5.5 leads on single-session coding tasks (HumanEval 94.2% vs 92%) and has cut its hallucination rate to 8.9%, down from 18.7% in GPT-5.3 Instant.
- Both models support a 1.05-million-token context window and accept text, image, audio, and video inputs.
- The price gap makes Flash the default for high-volume pipelines; GPT-5.5 earns its premium for customer-facing, domain-critical outputs.
Where these models came from
Google launched Gemini 3.5 Flash at Google I/O in May 2026 with a clear brief: build an agent-optimized model that runs at Flash speeds but matches last year's Pro-tier quality. The company claimed — and independent benchmarks confirmed — that 3.5 Flash surpasses Gemini 3.1 Pro on most tasks while costing dramatically less and running faster. It became available via the Gemini API on May 19, 2026 and quickly became one of the most-used models in developer pipelines, achieving an Intelligence Index score of 55 — above Grok 4.3 at 53 and Claude Sonnet 4.6 at 52.
OpenAI's GPT-5.5 shipped on May 5, 2026, as the new default model for ChatGPT across all paid tiers, replacing GPT-5.3 Instant. The company framed it primarily as a reliability and personalization upgrade. The headline stat: a 52.5% reduction in hallucinations on high-stakes prompts covering medicine, law, and finance. It also introduced a "memory sources" panel that shows users exactly which prior context shaped a given response — a practical feature for anyone doing long-running research. On the API, GPT-5.5 sits at the top of the GPT-5.x family.
How much does each model actually cost?
This is where the gap is hardest to ignore. Gemini 3.5 Flash costs $1.50 per million input tokens and $9.00 per million output tokens, with cached input billed at just $0.15 per million. GPT-5.5 on the API is priced at $5.00 per million input tokens and $30.00 per million output tokens.
On a typical agentic workflow generating 500,000 input tokens and 150,000 output tokens per day, that works out to about $2.10 with Flash versus $8.00 with GPT-5.5. At scale — say a product running 10 million input tokens daily — the difference is roughly $15 versus $50. For a product team running 100 million input tokens a month, Flash saves around $350 monthly on input alone. That is a real infrastructure cost difference that changes unit economics.
GPT-5.5 Instant — the version built into ChatGPT for consumers — is included in all paid plans at no extra charge. If you are building on the API, though, you are paying the $5 input rate.
Which model is faster?
Speed is where Flash earns its name. Google reports that 3.5 Flash outputs tokens at 284 per second, which independent benchmarks have confirmed — roughly four times the throughput of Gemini 3.1 Pro. At that rate, multi-step agentic tasks that chain five or six tool calls complete in a few seconds rather than tens of seconds — a user-experience difference that becomes visible quickly in production.
GPT-5.5 is not slow, but its architecture is optimized for accuracy and depth within a single response window rather than raw token throughput. That trade-off shows up clearly when you compare them on time-to-completion for parallel agent loops.
Which one handles agents and tools better?
This is Gemini 3.5 Flash's clearest advantage. On MCP Atlas, a benchmark that tests multi-step tool-calling reliability across complex agentic loops, Flash scores 83.6% versus GPT-5.5's 75.3%. That is an 8-point gap on exactly the benchmark that matters most for building AI assistants, workflow automation tools, and anything that calls external APIs in sequence.
The model also achieves an Elo of 1,656 on GDPval-AA, which measures real-world agentic performance on representative tasks. The pattern is consistent: when a task involves parallelizing work across multiple tools and managing state across a conversation, Flash holds a meaningful advantage.
Does GPT-5.5 still have an edge in coding and reasoning?
Yes, on certain tasks it does. On HumanEval, the standard function-level coding benchmark, GPT-5.5 scores 94.2% against Gemini 3.5 Flash's 92%. The gap is modest but consistent — GPT-5.5 tends to outperform when the task requires deep single-session reasoning over chains of dependent logic.
On SWE-Bench Pro, which tests models on real GitHub repositories with actual bug fixes required, GPT-5.5 scores 58.6% versus Flash's 55.1%. That 3.5-point gap is material if your use case is code review, large-scale refactors, or multi-file reasoning where context and accuracy compound.
The hallucination story is also relevant here. OpenAI measured an internal hallucination rate of 8.9% on GPT-5.5 Instant, down from 18.7% on GPT-5.3. If your application surfaces answers directly to end users in sensitive domains — legal, medical, financial — that number is a meaningful signal for production reliability.
So which should you build with?
The answer depends on what your workload actually looks like.
Choose Gemini 3.5 Flash if you are building an agentic product — something that calls tools, chains steps, processes documents at volume, or needs fast response times for user-facing interactions. The combination of lower cost and higher tool-calling scores is a compelling case for most product teams. The 4x throughput advantage also means lower latency for multi-turn interactions where response time affects user experience directly.
Choose GPT-5.5 if your product depends on high-accuracy answers in narrow domains, you need the hallucination rate improvements OpenAI has measured, or your users rely on deep single-session reasoning — complex coding assistance, legal document analysis, or financial modeling where the cost of a wrong answer is high. The 3x to 6x price premium is real, but so is the quality ceiling GPT-5.5 reaches on those tasks.
The practical middle path: use Flash as the default for your pipeline and route to GPT-5.5 only for queries where it demonstrably improves output quality on your specific inputs. Most products will find that 80 to 90 percent of their traffic performs just as well on Flash.
Both models carry a 1.05-million-token context window, both accept text, image, audio, and video inputs, and both support structured JSON output and system instructions. From a pure integration standpoint, the choice is primarily about performance and cost — not capability gaps.
Frequently asked questions
Is Gemini 3.5 Flash as smart as GPT-5.5?
On most agentic and multi-step benchmarks, yes — and on tool-calling benchmarks it scores meaningfully higher. GPT-5.5 has an edge on single-session software engineering tasks (SWE-Bench Pro: 58.6% vs 55.1%) and carries a lower measured hallucination rate on domain-specific prompts. For most API workloads, the two models are closely matched in overall intelligence, and the price-performance ratio favors Flash for high-volume usage.
Can I use Gemini 3.5 Flash through OpenAI's API?
No. Gemini 3.5 Flash is a Google model available through the Gemini API and on aggregator platforms like OpenRouter. GPT-5.5 is available through OpenAI's API and is the default model in paid ChatGPT tiers. You can access both through OpenRouter if you want to test them in the same codebase using a unified interface.
Which model is better for building coding agents?
GPT-5.5 leads slightly on pure software engineering benchmarks (SWE-Bench Pro: 58.6% vs 55.1%), but Gemini 3.5 Flash leads on multi-step tool-calling and agentic loop reliability (MCP Atlas: 83.6% vs 75.3%). For agents that interact with file systems, APIs, and terminals across multi-step chains, Flash's agentic benchmark score and lower latency make it the stronger choice for most production pipelines.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
