AI Tools
Kimi K2.6 Review: The Open-Weight Agentic Coder That Beats GPT-5.5 for 80% Less

Open weights. A trillion parameters. A coding benchmark score that outpaced GPT-5.4 on SWE-Bench Pro — the closest thing the industry has to a real-world coding exam. When Moonshot AI released Kimi K2.6 on April 20, 2026, one thing became clear: you no longer need to pay frontier prices to get frontier results on code.
At $0.60 per million input tokens, Kimi K2.6 costs roughly 88 percent less than GPT-5.5 standard — and scores higher on the most rigorous coding benchmark available. That is not a footnote. It is a structural shift in who can build AI-powered software affordably.
Key takeaways
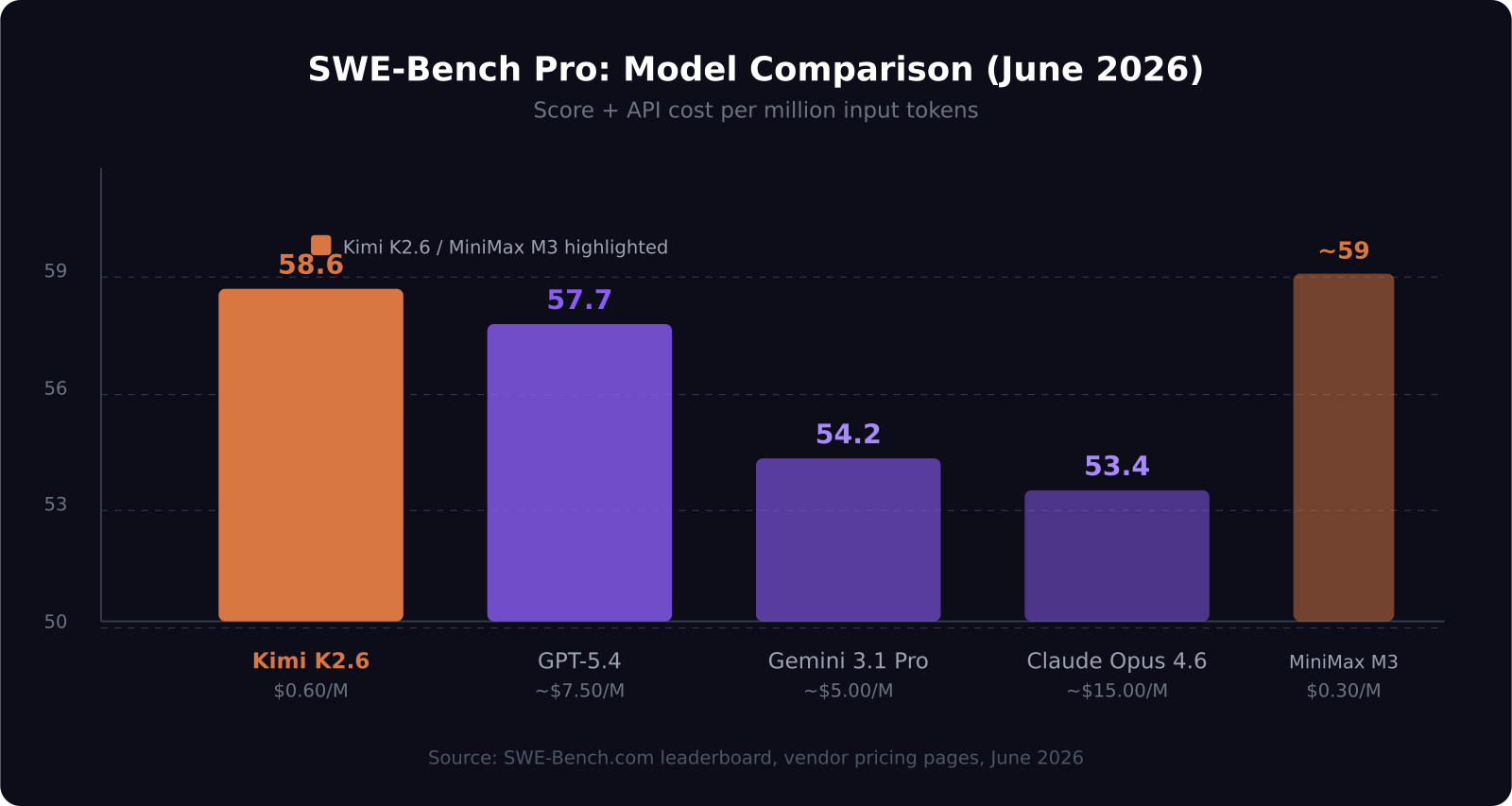
- Kimi K2.6 scored 58.6 on SWE-Bench Pro, ahead of GPT-5.4 (57.7), Gemini 3.1 Pro (54.2), and Claude Opus 4.6 (53.4)
- Pricing is $0.60 input / $2.50 output per million tokens — roughly 80–88 percent cheaper than GPT-5.5 or Claude Opus
- Agent Swarm coordinates up to 300 sub-agents for 12-hour autonomous coding sessions, natively — no external orchestration framework required
- Context window is 256,000 tokens, large enough to load an entire mid-sized codebase in a single session
- Fully open weights mean you can self-host rather than sending every token through a closed API
What Is Kimi K2.6?
Kimi K2.6 is the flagship open-weights model from Moonshot AI, a Beijing-based company behind the Kimi chatbot with over 100 million users in China. K2.6 is their contribution to the global developer community — an open model built specifically for sustained, autonomous coding work.
The architecture is a Mixture of Experts (MoE) design with 1 trillion total parameters. Only 32 billion of those parameters activate for any given token, which is what keeps the model fast and economical despite its enormous theoretical scale. Moonshot also baked in native INT4 quantization, which compresses the model efficiently without a meaningful accuracy drop.
The context window sits at 256,000 tokens. In practical terms, that means you can paste an entire mid-sized SaaS codebase into the context and have the model reason across all of it at once — a capability that matters significantly for autonomous refactoring or large-scale debugging tasks.
Is Kimi K2.6 Actually Competitive on Benchmarks?
SWE-Bench Pro is the test that matters most for production coding work. It takes real GitHub issues from active open-source repositories and measures how reliably a model resolves them end-to-end — not fill-in-the-blank completions, but working code changes that close the issue.
Kimi K2.6 scored 58.6 on SWE-Bench Pro. For context, GPT-5.4 scored 57.7. Gemini 3.1 Pro came in at 54.2. Claude Opus 4.6 scored 53.4.
On SWE-Bench Verified — a broader variant of the same test suite — K2.6 scored 80.2 percent, the highest of any open-weights model currently on the public leaderboard. The Artificial Analysis Intelligence Index also placed K2.6 at a score of 54, again the top mark among openly available models.
The honest caveat: on complex English-language instruction following — detailed system prompts with strict formatting rules, multi-step constraints, and precise output schemas — Claude Opus 4.8 remains more consistent. K2.6 occasionally misses edge cases in heavily constrained prompts. For raw coding output and code reasoning, though, K2.6 is genuinely competitive with anything you can access right now.
What Is Agent Swarm and Why Does It Matter?
This is the feature that separates K2.6 from most of the 2026 model field.
Agent Swarm is a native orchestration primitive built into the model itself — not an external framework you layer on top. When running a swarm task, K2.6 can spin up to 300 parallel sub-agents, coordinating them across up to 4,000 sequential steps.
In practical terms: you give K2.6 a software specification and it can autonomously write code, run tests, diagnose failures, fix bugs, and continue the loop for 12 hours or more without you prompting it at each stage.
Most agentic AI workflows in 2026 still require external orchestration — LangGraph, Claude Code, Cursor agents, or custom frameworks — wrapping a base model and managing the task loop from outside. Kimi K2.6 builds that loop in natively, which means faster coordination, lower token overhead, and significantly less prompt engineering to set up a long-running autonomous job.
If you have ever watched a 30-step coding task through an external agent framework fall apart at step 18 because of a subtle context management failure, the appeal of native coordination becomes obvious. The model knows what it spawned.
How Does the Pricing Stack Up?
Kimi K2.6 API pricing: $0.60 per million input tokens, $2.50 per million output tokens.
For comparison, GPT-5.5 standard runs at approximately $7.50 input / $15.00 output per million tokens. Claude Opus 4.8 is priced around $15.00 input / $75.00 output. Even MiniMax M3 — which we reviewed last month as a benchmark-competitive cheap option — comes in at $0.30 input / $1.20 output.
K2.6 is not the cheapest option in absolute terms. MiniMax M3 wins on raw per-token cost. But M3 does not offer native Agent Swarm or match K2.6 on SWE-Bench Pro. For agentic coding work where you need both capability and scale, K2.6 occupies a position no other model has claimed: frontier coding performance at near-open-source prices.
An autonomous coding session that burns through 5 million tokens — a realistic number for a 12-hour swarm run — costs roughly $3.25 combined with K2.6. The same session with GPT-5.5 runs closer to $37 to $50 depending on the input-to-output token split. At any meaningful volume, that delta transforms the unit economics of AI-powered development.
Who Should Be Using Kimi K2.6?
Three profiles stand out as clear fits right now.
Developers and small engineering teams building products with long autonomous coding cycles — refactors, complex feature implementations, infrastructure automation, or sustained CI/CD work — will find K2.6's native swarm capabilities and low token cost difficult to argue against. You get a better SWE-Bench score than GPT-5.4 at a fraction of the price, with the ability to run unsupervised for extended periods.
Teams working in bilingual Chinese-English environments get a meaningful advantage with K2.6. Moonshot's training reflects their background and expertise — for any workflow that mixes Chinese-language documentation, comments, or user-facing strings with production code, K2.6 handles language switching more reliably than Western models.
Infrastructure-sensitive teams who need to self-host for regulatory compliance, data residency requirements, or latency control can download the full open weights and run K2.6 on their own GPU cluster. That option simply does not exist with GPT-5.5, Claude Opus, or any of OpenAI's proprietary lineup.
Where Does Kimi K2.6 Fall Short?
Instruction following under complex English-language constraints is the documented weak spot. If your prompts involve many simultaneous rules — specific output formats, hard restrictions on content, precise schema requirements — Claude Opus 4.8 is more consistently reliable. K2.6 occasionally reinterprets or drops edge-case constraints, particularly when prompts are dense with conflicting requirements.
Self-hosting is also more demanding than it sounds. Running a 1 trillion parameter MoE model requires significant GPU infrastructure. Unless you are operating a well-provisioned compute cluster, the Kimi API is the practical path — which puts you in the same cloud-dependency situation as any other vendor.
Community tooling and documentation are newer than the GPT-4 and Claude ecosystems, which have years of community integrations, Stack Overflow answers, and documented quirks. K2.6, released April 2026, is still building that knowledge base. You may hit less-documented edge cases before they get resolved in the wild.
Frequently asked questions
How does Kimi K2.6 compare to Claude Opus 4.8 for coding? K2.6 scores higher on SWE-Bench Pro (58.6 versus 53.4 for Claude Opus 4.6) and costs significantly less at $0.60 versus $15.00 per million input tokens. For raw coding output and autonomous tasks, K2.6 is competitive or better. Claude still leads on complex English instruction following and strict output compliance in high-constraint workflows.
Can I self-host Kimi K2.6 for free? The weights are open and available to download. Running the full 1 trillion parameter model requires meaningful GPU capacity — most teams use the Kimi API at $0.60/$2.50 per million tokens rather than self-hosting. Smaller quantized variants are more accessible for local testing.
Is Kimi K2.6 better than MiniMax M3 for agentic coding? For dedicated coding and agentic tasks, K2.6 has the edge — it scores higher on SWE-Bench Pro and includes native Agent Swarm for long autonomous runs. MiniMax M3 is cheaper per token at $0.30/$1.20 and offers a 1M-token context window. The right pick depends on your workload: swarm-based agentic coding favors K2.6, while very long context tasks at minimum cost favor M3.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
