AI Tools
MAI-Thinking-1 vs Claude Opus 4.6 vs o3: Best Reasoning Model for Builders in 2026?

Microsoft's MAI-Thinking-1 joins Claude Opus 4.6 and o3 as the third serious reasoning model you can actually build with in 2026. It scores 97.0% on AIME 2025, matches Opus 4.6 on SWE-bench Pro, and runs inside Azure with no OpenAI dependency. Here is where each model wins, where each falls short, and which one belongs in your stack.
Key takeaways
- MAI-Thinking-1 is Microsoft's first in-house reasoning model, a 35B MoE trained entirely without OpenAI data
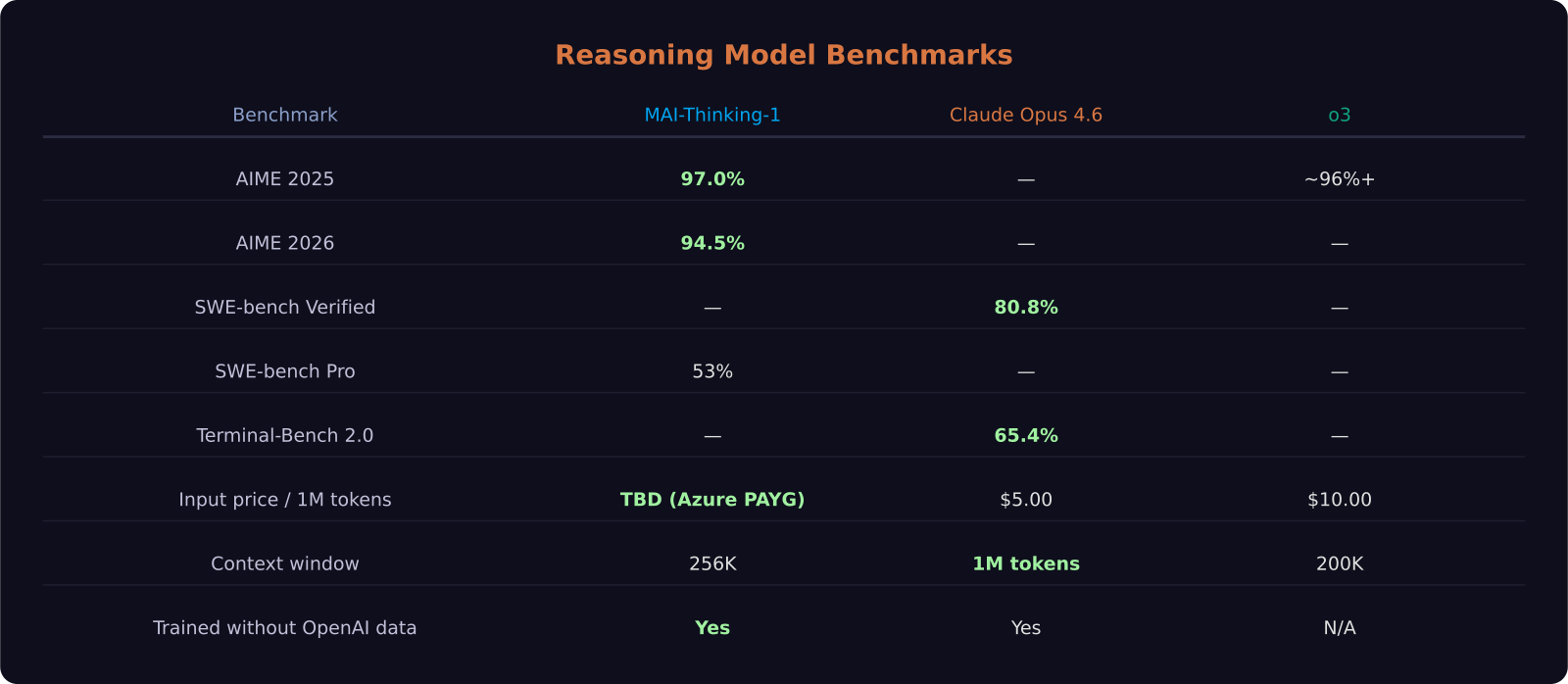
- It hits 97.0% on AIME 2025 and 94.5% on AIME 2026 — matching the math ceiling of o3
- Claude Opus 4.6 leads on agentic coding with 80.8% SWE-bench Verified and a 1M token context window
- o3 costs $10 per million input tokens — twice what Claude Opus 4.6 charges at $5
- MAI-Thinking-1 has no published per-token pricing yet; free prototyping is available via GitHub Models
Why there are three reasoning models worth discussing now
For the first half of 2026, the reasoning tier was effectively a two-horse race: o3 from OpenAI and Claude Opus 4.6 from Anthropic. Microsoft announced MAI-Thinking-1 at Build 2026 on June 2, 2026, and it changes the picture for teams running Azure-native infrastructure. It is not a distillation or fine-tune — Microsoft trained it from scratch on commercially licensed data, which matters for enterprise compliance teams that care about data provenance.
These are all extended-thinking models. They take longer and cost more than fast chat models, but they solve the problems where GPT-5.5 and Gemini 3.1 Pro hit their ceiling — math, complex multi-step code, scientific inference, and long-horizon agentic tasks.
MAI-Thinking-1: what Microsoft actually built
MAI-Thinking-1 is a 35-billion active-parameter Mixture-of-Experts model with a 256K context window. It activates only the components relevant to a given request, which keeps inference costs lower than its total parameter count would suggest. Microsoft is co-designing it with the Maia 200 chip and claims a 1.4x performance-per-watt gain when running on that silicon end-to-end.
On AIME 2025 it scored 97.0%. On AIME 2026 it scored 94.5%. For context, these are the hardest publicly available math competition benchmarks, and those numbers sit right alongside o3's results. On SWE-bench Pro it lands at 53%, which is close to Claude Opus 4.6 on that same benchmark.
Access right now is through Azure AI Foundry in private preview, with a public preview coming shortly. GitHub Models offers free-tier access for prototyping with your existing GitHub credentials, no Azure subscription needed. Per-token pricing for production use has not been published yet — Microsoft is going pay-as-you-go on reasoning tokens consumed through Foundry.
Claude Opus 4.6: still the agentic coding leader
Claude Opus 4.6 launched February 4, 2026 and remains the most capable model for long-context agentic coding. At $5 per million input tokens and $25 per million output tokens, it is half the cost of o3. The 1M token context window — with a premium tier at $10/$37.50 for prompts above 200K tokens — is four times larger than MAI-Thinking-1's 256K limit and five times larger than o3's 200K window.
On SWE-bench Verified it scores 80.8%, the highest Anthropic has reported for this model family. Terminal-Bench 2.0 at 65.4% leads all three models on that benchmark. For OSWorld — which tests autonomous computer use — it hits 72.7%. If your use case involves autonomous agents that interact with software interfaces or navigate multi-step developer workflows, Opus 4.6 is still the strongest option available today.
It also introduced adaptive thinking, where the model dynamically allocates how much extended reasoning to use based on contextual cues. Developers can set explicit effort controls to trade off inference cost against answer quality.
o3: most expensive, still the hardest reasoning ceiling
OpenAI's o3 costs $10 per million input tokens and $40 per million output tokens — twice the Opus 4.6 rate on input and 60% more expensive on output. It has a 200K token context window, which is the smallest of the three. What justifies that price is that o3 remains the strongest model for the absolute hardest reasoning tasks — complex proofs, multi-hop research synthesis, and deep code review where context chains across many files.
For most builder use cases in 2026, o3 is overkill at its price point. It makes sense when you have a specific evaluation where it is meaningfully better than the alternatives, or when you need to run it infrequently on difficult problems and cost-per-call is not a constraint.
How to choose between these three
If you are already in Azure and need an enterprise-grade reasoning model without an OpenAI dependency, MAI-Thinking-1 is worth evaluating now — especially since GitHub Models lets you test it free. Its math and science performance is genuinely competitive with o3.
If you are building agentic coding systems, autonomous research agents, or anything that needs to read very long documents while reasoning, Claude Opus 4.6 is the strongest all-around choice at a reasonable price.
If you have a specific high-stakes task — complex legal analysis, deep scientific reasoning, or a benchmark-driven decision where o3 outperforms the others in your own evals — then the $10 input price is justified. Otherwise, you are paying for ceiling you will rarely touch.
The creator angle
I cover these models regularly in tutorials and tool walkthroughs. The most interesting thing about MAI-Thinking-1 is not the benchmark score — it is the data provenance story. Microsoft's claim that it was trained without any third-party model distillation, on clean, commercially traceable data, is exactly what enterprise legal and compliance teams want to hear before deploying a reasoning model in production. That is a positioning angle OpenAI and Anthropic cannot match on their own models, and it could drive real adoption independent of raw benchmark rankings.
Frequently asked questions
Is MAI-Thinking-1 better than o3?
On math benchmarks like AIME 2025 (97.0%) and AIME 2026 (94.5%), MAI-Thinking-1 is competitive with o3. On SWE-bench Pro it sits at 53%, close to o3's range. The main differences are context window (256K vs 200K for o3) and training lineage — Microsoft built MAI-Thinking-1 entirely without OpenAI data, which matters for enterprise compliance.
How much does Claude Opus 4.6 cost versus o3?
Claude Opus 4.6 costs $5 per million input tokens and $25 per million output tokens. OpenAI o3 costs $10 per million input tokens and $40 per million output tokens. For most use cases, Opus 4.6 is the better value, especially given its 1M token context window versus o3's 200K.
Where can I access MAI-Thinking-1?
MAI-Thinking-1 is available in private preview on Azure AI Foundry. Free-tier prototyping access is available through GitHub Models using your existing GitHub account — no Azure subscription required. Public preview via the MAI Playground is forthcoming.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
