AI & SaaS
OpenAI Jalapeño Chip: What It Is and What It Means for AI Costs

OpenAI unveiled its first custom silicon on June 24, 2026. The chip is called Jalapeño, built in partnership with Broadcom, and it is not a general-purpose GPU. It is a purpose-designed inference accelerator built entirely around how OpenAI's models process tokens at scale — and OpenAI is targeting more than 50% cheaper inference costs once it deploys at full production scale.
That number matters. Every ChatGPT query, every API call, every Codex task runs on inference hardware. If Jalapeño delivers on its cost targets, it directly affects what OpenAI can charge — and what competitors have to respond with.
Here is what we know.
Key takeaways
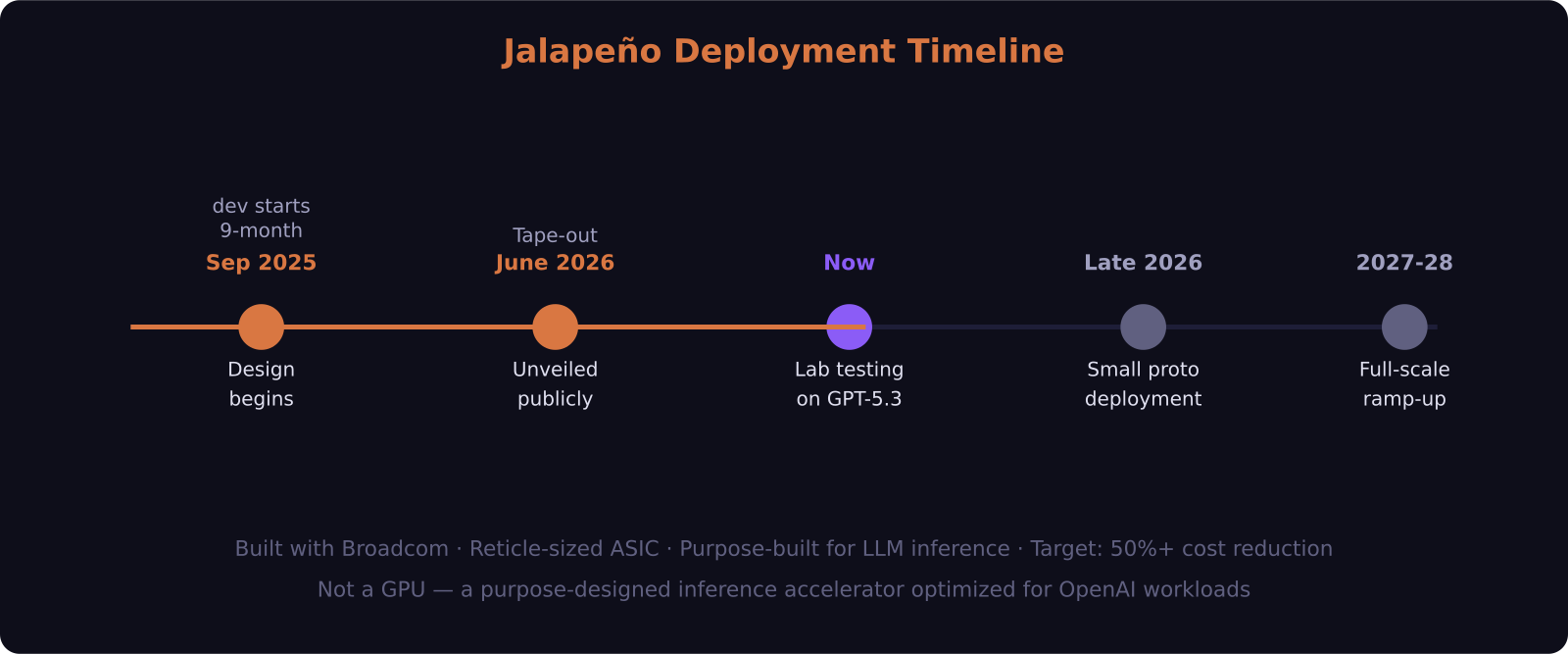
- Jalapeño is OpenAI's first custom chip, announced June 24, 2026 — a purpose-built LLM inference ASIC designed with Broadcom, not adapted from a general GPU.
- The chip reached tape-out in just nine months, a development pace OpenAI says was accelerated by its own AI models assisting in the design process.
- Engineering samples are already running GPT-5.3-Codex-Spark in the lab at production target frequency and power.
- Initial small-scale deployment begins late 2026, with full ramp starting in 2027 and peak deployment in early 2028.
- The targeted cost reduction is more than 50% versus current state-of-the-art inference hardware.
What Is Jalapeño?
Jalapeño is a reticle-sized ASIC — an application-specific integrated circuit — meaning every transistor on the chip exists to run one kind of workload: LLM inference. Unlike NVIDIA's H100 or H200 GPUs, which are designed to handle training, inference, and general compute workloads, Jalapeño has no general-purpose flexibility. OpenAI traded flexibility for optimization.
The chip's architecture was designed around the specific bottlenecks OpenAI encounters at inference scale: data movement between memory and compute, the imbalance between how fast a model can read weights and how fast it can generate output tokens, and the networking efficiency needed when thousands of chips run in concert across a data center.
OpenAI built this with Broadcom — a semiconductor company that already designs custom ASICs for Google's TPU line. Broadcom's ASIC experience combined with OpenAI's deep knowledge of its own model behavior is what allowed a nine-month development cycle to produce something credible enough to begin production testing.
Why Did OpenAI Build Its Own Chip?
NVIDIA has been OpenAI's primary compute supplier, and that relationship remains intact — NVIDIA silicon will continue running OpenAI workloads for years. But relying entirely on a single vendor at the scale OpenAI operates is both expensive and strategically uncomfortable.
Google built TPUs. Amazon built Trainium and Inferentia. Meta built MTIA. The pattern among hyperscalers is consistent: once your compute budget crosses a certain threshold, custom silicon starts to pencil out. OpenAI's training and inference costs place it comfortably in that territory.
The stated goal is to own "the full stack" — from model weights to the hardware running them. Every dollar that Jalapeño saves per million tokens becomes a pricing lever or a margin advantage over competitors who remain dependent on third-party hardware.
What Makes Jalapeño Different from a GPU?
A standard AI GPU is optimized for training: massive matrix multiplications running in parallel, high memory bandwidth, and the flexibility to handle different model architectures. Those features come with cost and power overhead that inference workloads do not use efficiently.
LLM inference has a specific computational signature: you load a large model once, then generate tokens sequentially, one token at a time per request. The bottleneck shifts from raw compute to memory bandwidth and latency. Jalapeño's architecture is designed specifically around this pattern — reducing the data movement overhead that makes large-model inference expensive at scale.
OpenAI says early benchmarks show Jalapeño will deliver performance per watt substantially better than current state-of-the-art. The chip also runs at production target frequency and power in current lab testing on GPT-5.3-Codex-Spark, which means the design is not still chasing a thermal ceiling.
When Will Jalapeño Actually Be Available?
The timeline is gradual. Small prototype deployment begins in late 2026 — not enough scale to move pricing meaningfully, but enough to validate the production design in real-world conditions. From there, deployment ramps through 2027 and reaches full-scale production in the first half of 2028.
That is an honest timeline for custom silicon. From tape-out to mass deployment, the typical cycle is eighteen to twenty-four months, and Jalapeño's nine-month tape-out to announcement already moved faster than the industry norm. The 2028 full ramp is not a punt — it is realistic.
What Does This Mean for AI Pricing?
In the near term: nothing changes. NVIDIA hardware continues to run OpenAI's infrastructure through 2027 at minimum. The API pricing you see today will not shift because Jalapeño is in lab testing.
In the medium term: if the cost-reduction targets hold, OpenAI has two choices. It can lower API pricing to grow usage and market share, or it can maintain pricing and capture the margin improvement. Given competitive pressure from Anthropic, Google, and open-weight models, the more likely outcome is a mix — some pricing reductions on high-volume tiers, maintained margins on premium capability.
For users, the most meaningful downstream effect is accessibility. Cheaper inference at scale tends to result in higher rate limits, lower usage-based pricing over time, and more generous free tiers as the cost floor drops.
The Creator's Take
What strikes me most about the Jalapeño announcement is the speed. Nine months from concept to tape-out, with OpenAI's own AI models assisting in the chip design process, is a proof of concept for a different kind of hardware development cycle. If that pace can be repeated, the gap between "we have a new model" and "we have custom silicon optimized for that model" shrinks considerably.
It also changes how I think about the long-term positioning of companies like Anthropic and xAI, which do not have their own silicon programs announced. Running on NVIDIA at scale is viable — but owning the inference layer is increasingly a structural advantage.
Frequently asked questions
Is Jalapeño replacing NVIDIA chips?
Not anytime soon. Jalapeño is targeted for small prototype deployment in late 2026 and full scale in 2028. NVIDIA silicon will continue running the majority of OpenAI's workloads through at least 2027. Jalapeño is a long-term infrastructure investment, not an immediate hardware replacement.
How did OpenAI build a chip in nine months?
OpenAI worked with Broadcom, which has deep ASIC design experience from building Google's TPUs. OpenAI also used its own AI models to assist in the chip design process — a detail that speaks to how automated chip design is becoming. The combination of an experienced silicon partner and AI-assisted development enabled the unusually fast timeline.
Will Jalapeño make ChatGPT cheaper to use?
Not immediately. The chip does not reach meaningful production scale until 2028. Longer term, if OpenAI achieves its target of 50%+ inference cost reduction, competitive pressure is likely to translate some of that into lower pricing or higher limits, but no specific pricing changes have been announced.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
