AI Tools
Claude Fable 5 and Mythos 5 Explained: What SaaS Builders Need to Know Before Access Changes

Anthropic launched Claude Fable 5 on June 9, 2026 — the most capable model the company has ever made publicly available. Three days later, the US government suspended access to it. The suspension has since been addressed, but the episode tells you something real about where AI has arrived. Today, June 22, is also the last day Fable 5 is included free for Claude Pro, Max, Team, and Enterprise subscribers. Here is what the model is, what happened with the government order, and what this means if you're building on Claude.
Key takeaways
- Claude Fable 5 is Anthropic's first publicly available Mythos-class model — a tier above Opus 4.8 in capability
- It costs $10 per million input tokens and $50 per million output tokens, less than half the price of the earlier Claude Mythos Preview
- The US government suspended access on June 12 citing national security concerns over a reported jailbreak technique; access was subsequently restored
- Free access on subscription plans ends June 22 — starting June 23, usage credits are required to use Fable 5
- Fable 5 is the current top performer on Cognition's FrontierCode benchmark and the highest-scoring model on CursorBench
What exactly is a Mythos-class model?
Anthropic restructured its model lineup in 2026. The tiers from most to least capable are now: Mythos, Opus, Sonnet, Haiku. Claude Mythos Preview was the first Mythos-class model, released in April 2026 exclusively to a small group of cybersecurity organizations through a government partnership called Project Glasswing. It was never available to the general public.
Fable 5 is the same capability tier, but released to everyone with appropriate safety guardrails in place. Claude Mythos 5 — announced the same day — is the same underlying model as Fable 5 with the cyber safeguards lifted, and remains restricted to government partners and vetted security organizations.
The name itself is a signal. Fable comes from the Latin fabula, meaning "that which is told" — cognate with the Greek mythos. The safeguards are what distinguish the two products.
What makes Fable 5 meaningfully better than Opus 4.8?
Three areas stand out based on what Anthropic and early access partners reported.
The first is the scale of autonomous work the model can complete. Stripe tested it on a 50-million-line Ruby codebase and reported a codebase-wide migration — the kind that would take a full engineering team over two months to do by hand — was completed in a single day. That compression of weeks into hours represents a genuine shift in what agentic AI can accomplish.
The second is coding benchmark performance. On Cognition's FrontierCode evaluation, which tests whether models can pass difficult coding tasks while meeting the standards of real production codebases, Fable 5 scored highest among all frontier models tested. Cursor reported it is the top model on their internal CursorBench. One analytics platform running complex long-horizon tasks found Fable 5 broke 90 percent accuracy — a 10-point gain over Opus 4.8 on their hardest questions.
The third is vision and long-context memory. Fable 5 can play Pokémon FireRed from start to finish using only raw game screenshots, with no helper harnesses, maps, or game-state supplements. Earlier Claude models could not do this even with extensive scaffolding. On memory tasks involving millions of tokens, the model's improvement from using persistent notes was three times larger than Opus 4.8's improvement under the same conditions.
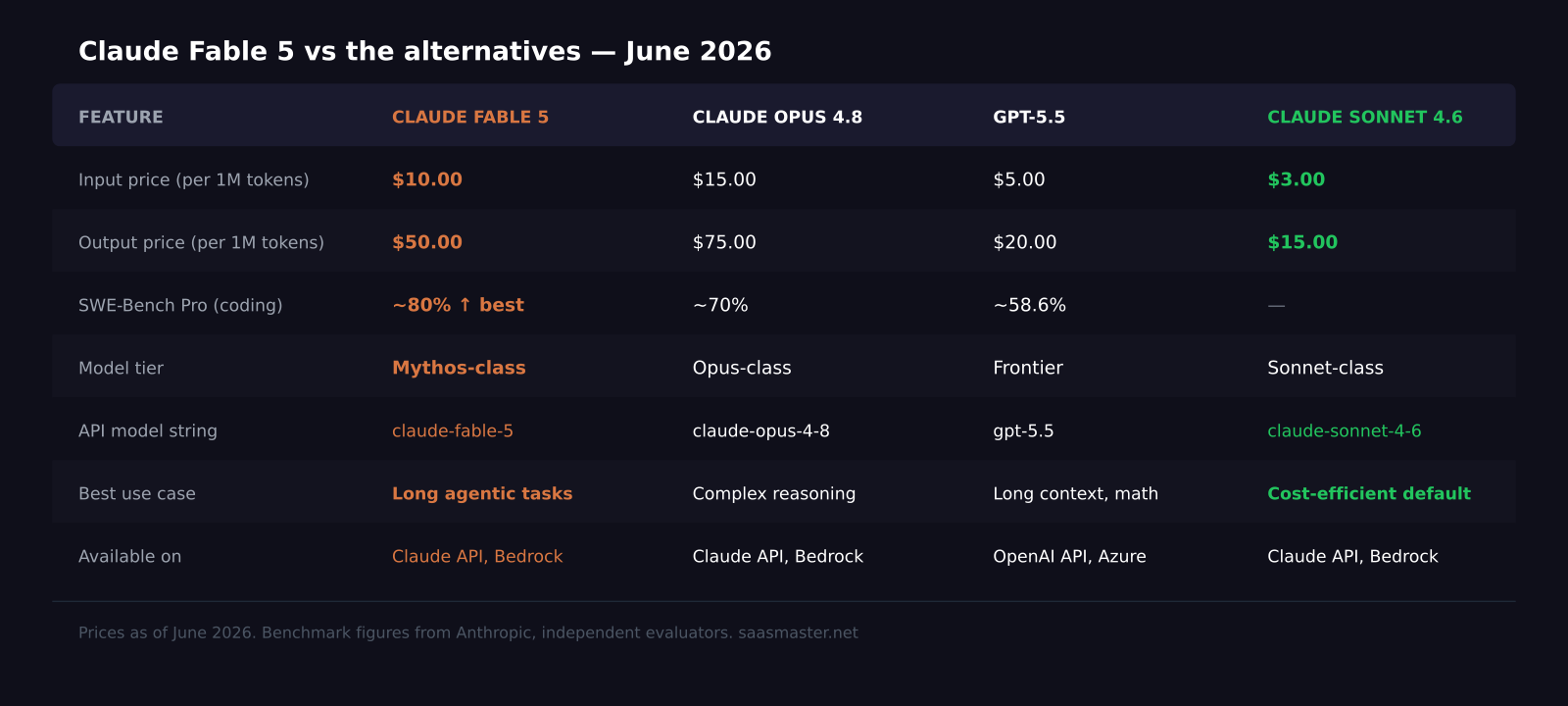
How does the pricing compare?
Fable 5 and Mythos 5 are both priced at $10 per million input tokens and $50 per million output tokens. That is less than half the price of Claude Mythos Preview, which previously sat behind a restricted access program.
Compare that to Claude Sonnet 4.6 at $3 per million input and $15 per million output, or GPT-5.5 at $5 per million input and $20 per million output. Fable 5 is significantly more expensive than Sonnet 4.6. For most SaaS product integrations where you are calling Claude for short, frequent tasks, Sonnet 4.6 is still the cost-efficient default.
Fable 5's price point makes most sense for long-horizon agentic tasks: automated code reviews across large codebases, extended research workflows, complex multi-step document analysis, or any job where the model needs to work unsupervised for an extended period and produce something that genuinely requires frontier-level reasoning.
What happened with the US government suspension?
On June 12, 2026, Anthropic received a directive from the US government to suspend all access to Fable 5 and Mythos 5 for any foreign national — inside or outside the United States, including Anthropic's own foreign national employees. The order cited national security authorities and was triggered by a reported demonstration of a jailbreak technique.
Anthropic complied and pulled access globally within hours of receiving the directive. The company publicly disagreed with the standard being applied, arguing that if a narrow potential jailbreak was sufficient grounds to recall a commercial model deployed to hundreds of millions of users, it would effectively stop all frontier model deployments across the entire AI industry.
Access has since been restored for Fable 5. The incident raised a practical point for developers: even production-grade AI APIs can be interrupted for reasons outside the provider's control. If you are building a product on Fable 5, build a fallback. Using claude-opus-4-8 as your fallback model identifier ensures your users still get a high-quality experience during any availability window.
How the safety classifiers work
Fable 5 uses a set of separate AI systems — classifiers — that sit in front of the main model and intercept certain categories of requests. When a query touches cybersecurity exploitation, biology and chemistry at a level that could provide dangerous uplift, or what Anthropic calls distillation attempts (large-scale automated extraction of the model's capabilities to train competing models), the classifier routes the response to Claude Opus 4.8 instead.
In Anthropic's early data, more than 95 percent of Fable 5 sessions involve no fallback at all. When a fallback occurs, users are notified and still receive an Opus 4.8 response rather than an outright refusal. The company ran over 1,000 hours of external red-team testing and found no universal jailbreaks.
For the overwhelming majority of SaaS and business use cases — customer support, code generation, content creation, data analysis, internal tooling — these classifiers will never trigger. The restrictions are narrow and targeted at a small category of genuinely dual-use capabilities.
What the free access deadline means for users today
When Fable 5 launched on June 9, Anthropic included it in Pro, Max, Team, and seat-based Enterprise plans at no extra cost as an introductory window through June 22. That window closes today.
Starting June 23, using Fable 5 on a subscription plan requires usage credits billed per token on top of your base plan. The API has always been pay-per-token and is unaffected. Anthropic said they intend to restore Fable 5 as a standard part of subscription plans as soon as capacity allows, but gave no specific timeline.
What SaaS builders should actually do with it
Fable 5 is the wrong choice for high-volume, short-context tasks. If you are building a feature where Claude answers short questions, summarizes single documents, or handles routine customer queries, Sonnet 4.6 is faster, cheaper, and more than capable.
Where Fable 5 justifies its price: long-horizon agentic work. If your product involves reviewing or transforming large codebases, conducting extended multi-step research, producing complex analysis of dense technical documents, or running Claude Code autonomously for extended periods, the capability jump from Opus 4.8 to Fable 5 is measurable and significant.
The API model string is claude-fable-5. It is available on the Claude API and Amazon Bedrock.
Frequently asked questions
Is Claude Fable 5 the same model as Claude Mythos 5?
They share the same underlying model weights, but Fable 5 has conservative safety classifiers that route certain sensitive requests to Opus 4.8. Mythos 5 has the cyber safeguards lifted and is available only through Project Glasswing and the US government trusted access program — not to the general public.
What benchmarks does Claude Fable 5 lead on?
Fable 5 currently scores highest among frontier models on Cognition's FrontierCode evaluation and Cursor's internal CursorBench. On one analytics platform's benchmark of complex long-running tasks, it broke 90 percent accuracy — up from roughly 80 percent for Opus 4.8. IMC reported it aced their trading-analysis evaluations nearly across the board.
Should I upgrade from Claude Sonnet 4.6 to Fable 5 for my product?
For most product features — real-time interactions, frequent API calls, short-context tasks — Sonnet 4.6 is the better default at roughly one-fifth the cost. Fable 5 makes sense for background agentic tasks, complex long-horizon automations, and applications where the model needs to reason autonomously over an extended period and the output quality difference is material.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master