AI Tools
Claude Fable 5 Review: Anthropic's Most Powerful Model and Its Hidden Catch

When Anthropic released Claude Fable 5 on June 9, 2026, it buried a detail that almost no one covered: if you ask this model something that touches cybersecurity, biology, or chemistry, it quietly routes your query to a different, weaker model with no notification. No error. No indicator. You receive a response that looks like Fable 5 but is not. That is a striking design choice for the most capable model Anthropic has ever made publicly available, and it says a lot about where the AI frontier is heading.
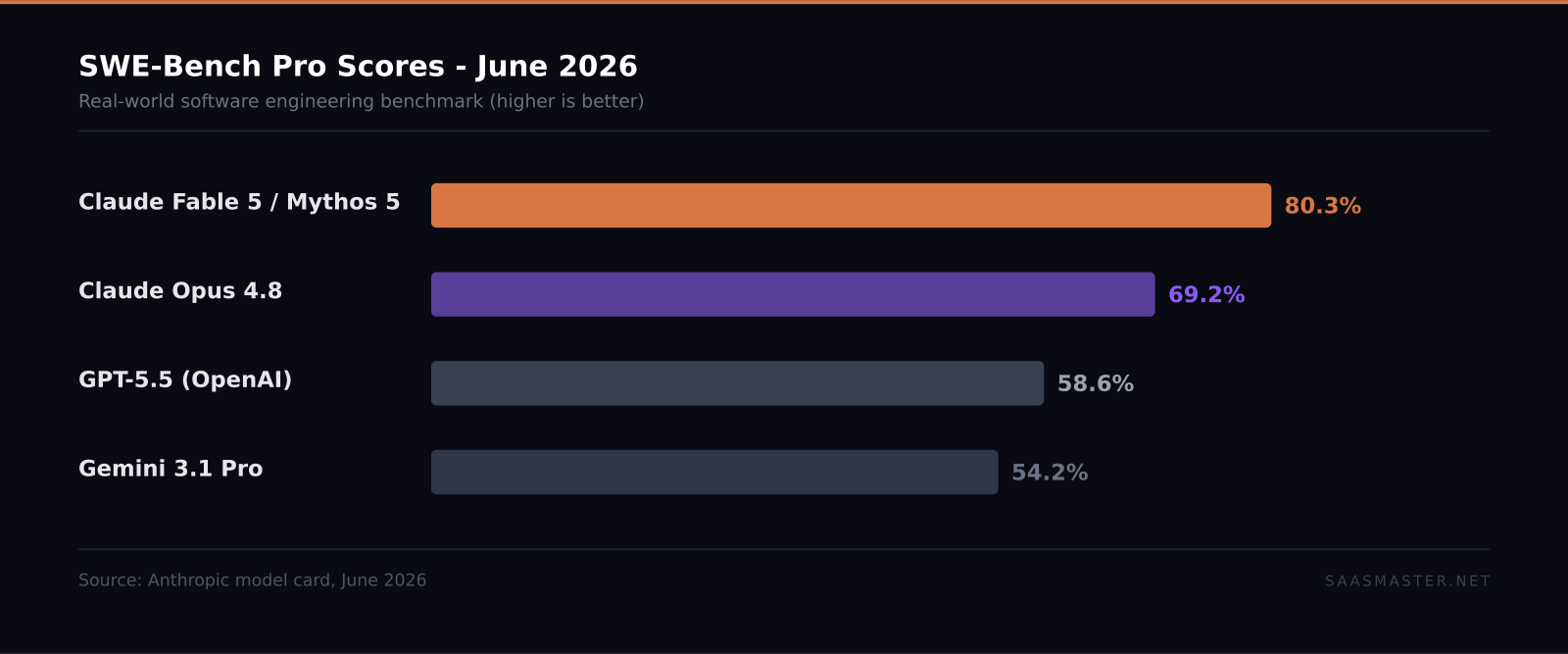
Key takeaways: - Claude Fable 5 is the first Mythos-class model cleared for general use, scoring 80.3% on SWE-Bench Pro versus Opus 4.8 at 69.2% and GPT-5.5 at 58.6%. - It was free on Pro, Max, Team, and seat-based Enterprise plans June 9 through June 22. Since June 23, using it draws from usage credits at $10 per million input and $50 per million output tokens. - Claude Mythos 5 is the same base model with some safeguards lifted, available only to vetted cyber defense and critical infrastructure providers. - Built-in classifiers silently route queries involving cybersecurity, biology, chemistry, or model distillation to a lower-capability fallback model. - For most creators and SaaS teams, Opus 4.8 remains the practical daily default. Fable 5 earns its premium in agentic pipelines and hard technical tasks.
What is the Mythos class and why does it exist?
Anthropic has restructured its model lineup. The Opus tier, which Opus 4.8 represents, is no longer the ceiling. Above it sits a new designation called Mythos, and Fable 5 is the first Mythos-class model Anthropic has cleared for broad general use.
The name reflects how Anthropic thinks about capability risk. Mythos-class models are where the gap between impressively capable and potentially dangerous begins to narrow. Before releasing Fable 5, Anthropic ran months of uplift testing across multiple risk domains. The decision to proceed came with the safeguards described below.
The other half of this release, Claude Mythos 5, is the same base model with some safety restrictions lifted. It is restricted to a narrow group: cyber defenders, critical infrastructure providers, and enterprise partners who passed a separate vetting process. Most developers will never access Mythos 5 directly. What it demonstrates is that Anthropic is now differentiating models not just by capability, but by use-case approval.
What do the benchmarks actually show?
On SWE-Bench Pro, the industry standard for measuring real-world software engineering performance, Fable 5 and Mythos 5 together score 80.3%. That puts them 11 points ahead of Claude Opus 4.8 at 69.2%, 22 points ahead of GPT-5.5 at 58.6%, and 26 points ahead of Gemini 3.1 Pro at 54.2%.
For knowledge work, the GDPval-AA benchmark, which measures performance on professional documents, structured analysis, and complex reasoning, puts Fable 5 at 1932. Opus 4.8 is 1890. GPT-5.5 sits at 1769. Gemini 3.1 Pro trails at 1314.
On vision tasks using GDP.pdf, a benchmark involving scanned documents and structured image content, Fable 5 reaches 29.8%, against Opus 4.8 at 22.5% and GPT-5.5 at 24.9%.
These are meaningful improvements, not incremental updates. The jump from Opus 4.8 to Fable 5 on SWE-Bench is larger than the typical generation-over-generation gain. For creators who use Claude for scripting, research synthesis, or structuring complex video treatments, the gains in instruction-following and multi-step reasoning are noticeable in daily practice, not just on paper.
How much does Claude Fable 5 actually cost?
Opus 4.8 costs $5 per million input tokens and $25 per million output tokens on the Anthropic API. Fable 5 doubles both: $10 per million input and $50 per million output. At meaningful API volumes, that doubles your AI spend instantly.
The subscription story is more complicated. During the launch window from June 9 through June 22, Anthropic included Fable 5 on Pro ($20/month), Max, Team, and Enterprise plans at no extra cost. That window closed June 23. Any use of Fable 5 after that date draws from prepaid usage credits billed at standard API token rates.
Anthropic says it intends to restore Fable 5 as a standard plan feature once infrastructure capacity allows, but has given no timeline. For now, a Pro subscriber who runs extended Fable 5 sessions will burn through credit balances quickly. A 20,000-token output conversation costs $1.00 at Fable 5 rates versus $0.50 at Opus 4.8 rates.
Is the performance jump worth double the price?
For most everyday work, the honest answer is probably not yet. Opus 4.8 is already excellent at writing, content generation, ideation, and standard coding assistance. The case for paying double grows in three specific situations.
First, complex agentic pipelines. When you chain multiple AI calls together, research then outlining then drafting then editing, accuracy at each step compounds. A model that is meaningfully more accurate at step two saves downstream correction work across every subsequent step. The 11-point SWE-Bench gap is real in practice.
Second, hard technical documents. If you are analyzing dense research papers, multi-page financial specifications, or structured data that requires multi-step synthesis where subtle errors carry consequences, Fable 5's knowledge-work advantage over Opus 4.8 shows up.
Third, vision tasks with dense document content. Fable 5's 29.8% GDP.pdf score against Opus 4.8's 22.5% is a 32% relative improvement. Any workflow processing scanned contracts, image-heavy reports, or handwritten notes will see that gap in output quality.
My recommendation: test Fable 5 on the three or four task types that consume the most of your AI budget. If you do not see a clear quality difference in your actual work, keep Opus 4.8 and revisit when Anthropic restores plan-level access.
What is the silent classifier and should it concern you?
Here is the most unusual part of Fable 5's design. Anthropic built classifiers into the system that watch every incoming query for content in three risk categories: cybersecurity (offensive tooling, exploit development), biology and chemistry (dangerous synthesis pathways), and model distillation (attempts to extract Fable 5's weights for reproduction).
If a query triggers these classifiers, the system responds using a weaker fallback model. The response appears normal. No error message, no flag, no indication the query was redirected. You receive an answer, just not from Fable 5.
For the overwhelming majority of users, content creators, SaaS founders, marketers, developers building standard products, these classifiers will never fire. For security researchers, biotech teams querying legitimate synthesis information, or developers testing AI systems, the classifier may activate on entirely legitimate requests.
I find the intent understandable. The alternative, a hard refusal or full Mythos-class capability applied to genuinely dangerous prompts, has obvious problems in either direction. The transparency issue is harder to dismiss. You are paying for one model and sometimes receiving another, with no notification. Anyone building applications on top of Fable 5 should test their critical query paths explicitly to confirm which model responds.
Who should use Fable 5 versus Opus 4.8?
Use Fable 5 for: complex agentic pipelines where multi-step accuracy compounds, hard coding and engineering tasks where Opus 4.8 already shows its ceiling, long scientific or technical document synthesis, and vision workflows involving dense structured content.
Stick with Opus 4.8 for: everyday writing and content creation, customer-facing chat where per-query cost matters, high-volume API workloads, and any task where your current Opus 4.8 results are already satisfactory.
The free access window is closed. Fable 5 is now a paid upgrade on every plan. The model is genuinely better and the improvement on complex tasks is noticeable in practice. Whether it is worth double the API price depends entirely on whether you have actually hit the ceiling of what Opus 4.8 can do in your specific work.
Frequently asked questions
Is Claude Fable 5 available on the Claude Pro plan?
Fable 5 was included free on Pro, Max, Team, and seat-based Enterprise plans from June 9 through June 22, 2026. Since June 23, access requires usage credits billed at $10 per million input and $50 per million output tokens. Anthropic has said it plans to restore Fable 5 as a standard plan feature when capacity allows but has not given a specific date.
How does Claude Fable 5 compare to GPT-5.5?
On SWE-Bench Pro, Fable 5 scores 80.3% versus GPT-5.5 at 58.6%, a 22-point lead. On GDPval-AA knowledge-work tasks, Fable 5 scores 1932 versus GPT-5.5 at 1769. On vision, Fable 5 scores 29.8% on GDP.pdf versus 24.9% for GPT-5.5. Both models price in a comparable API range, with Fable 5 at $10/$50 per million tokens.
What is the difference between Claude Fable 5 and Claude Mythos 5?
Both are built on the same base model. Fable 5 includes strict safety classifiers and is available to general users through Claude plans and the Anthropic API. Mythos 5 has some of those restrictions lifted and is accessible only to a small vetted group of cyber defense and critical infrastructure providers, not available through standard Claude subscriptions or the public API.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
