AI Tools
Claude Opus 4.8 vs GPT-5.5 vs Gemini 3 Pro: The Frontier Model Showdown for 2026
If you are trying to pick a frontier AI model in June 2026, the honest answer is that the gap between the top three has never been smaller — and yet the differences that remain actually matter a lot depending on how you use AI.
Claude Opus 4.8 leads on raw intelligence benchmarks. GPT-5.5 is the fastest and most token-efficient on structured tasks. Gemini 3 Pro is the cheapest per token and comes with a 2 million token context window that neither competitor touches. Here is what the data actually shows.
Key takeaways
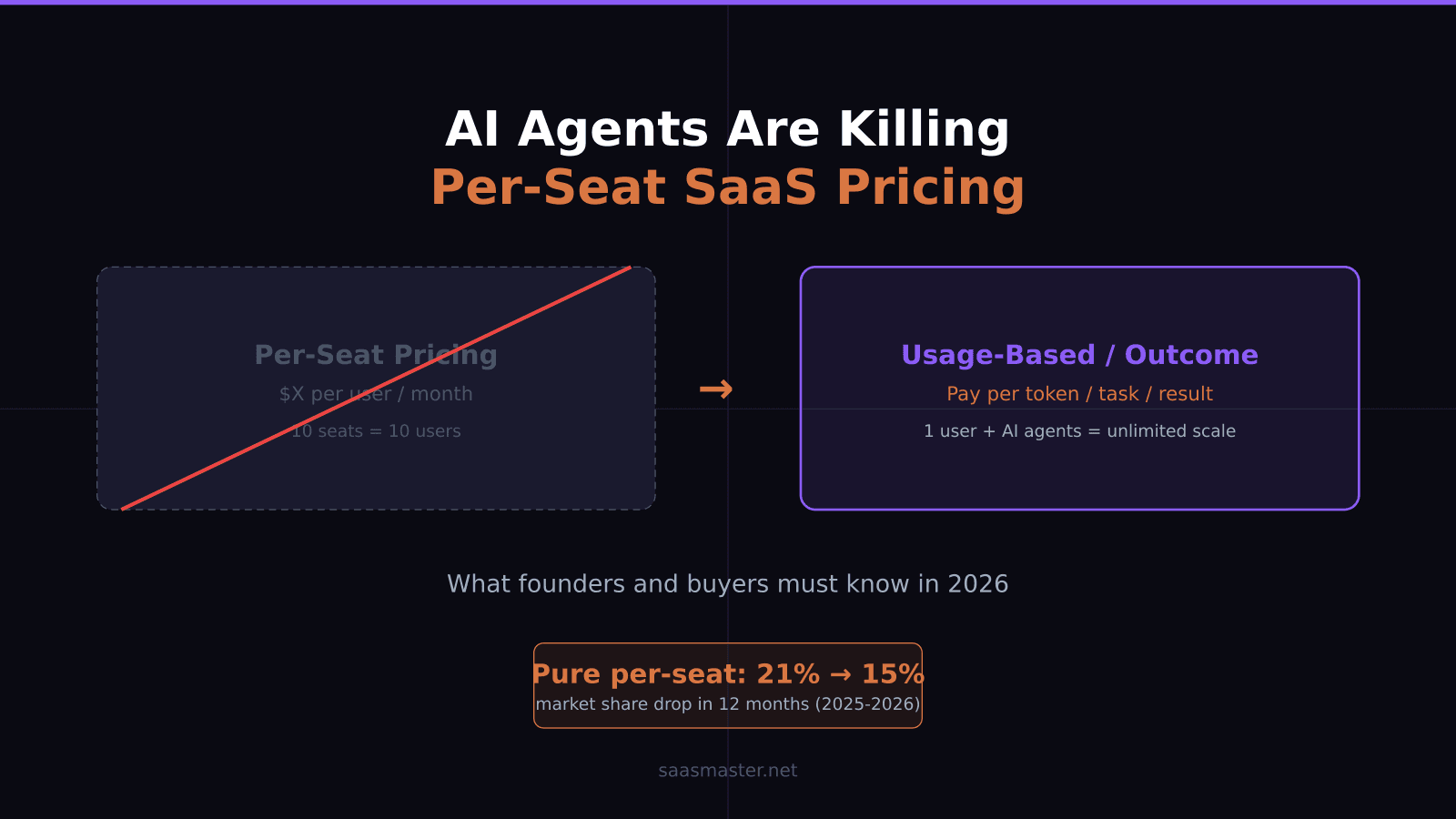
- Claude Opus 4.8 holds the top spot on the Artificial Analysis Intelligence Index at 61.4, just ahead of GPT-5.5 (60.2) and Gemini 3 Pro (58.1).
- Opus 4.8 dominates coding with 69.2% on SWE-bench Pro versus 58.6% for GPT-5.5.
- Gemini 3 Pro is significantly cheaper at $2.00 / $12.00 per 1M tokens versus $5.00 / $25–30 for the other two.
- GPT-5.5 is more token-efficient and faster for structured tool-use workflows.
- None of these models is clearly best for every use case — routing across them is the smartest production architecture.
When did these models ship?
Claude Opus 4.8 landed on May 28, 2026 — just 41 days after Opus 4.7, which tells you how fast Anthropic is moving right now. GPT-5.5 shipped April 23, 2026, following GPT-5 in August 2025 and a series of incremental updates. Gemini 3 Pro has been rolling out through Q1 and Q2 2026, with the 2M context window going generally available in March.
All three are current flagship models from their respective companies. None of them are "preview" or limited-access at this point.
What the benchmarks actually tell you
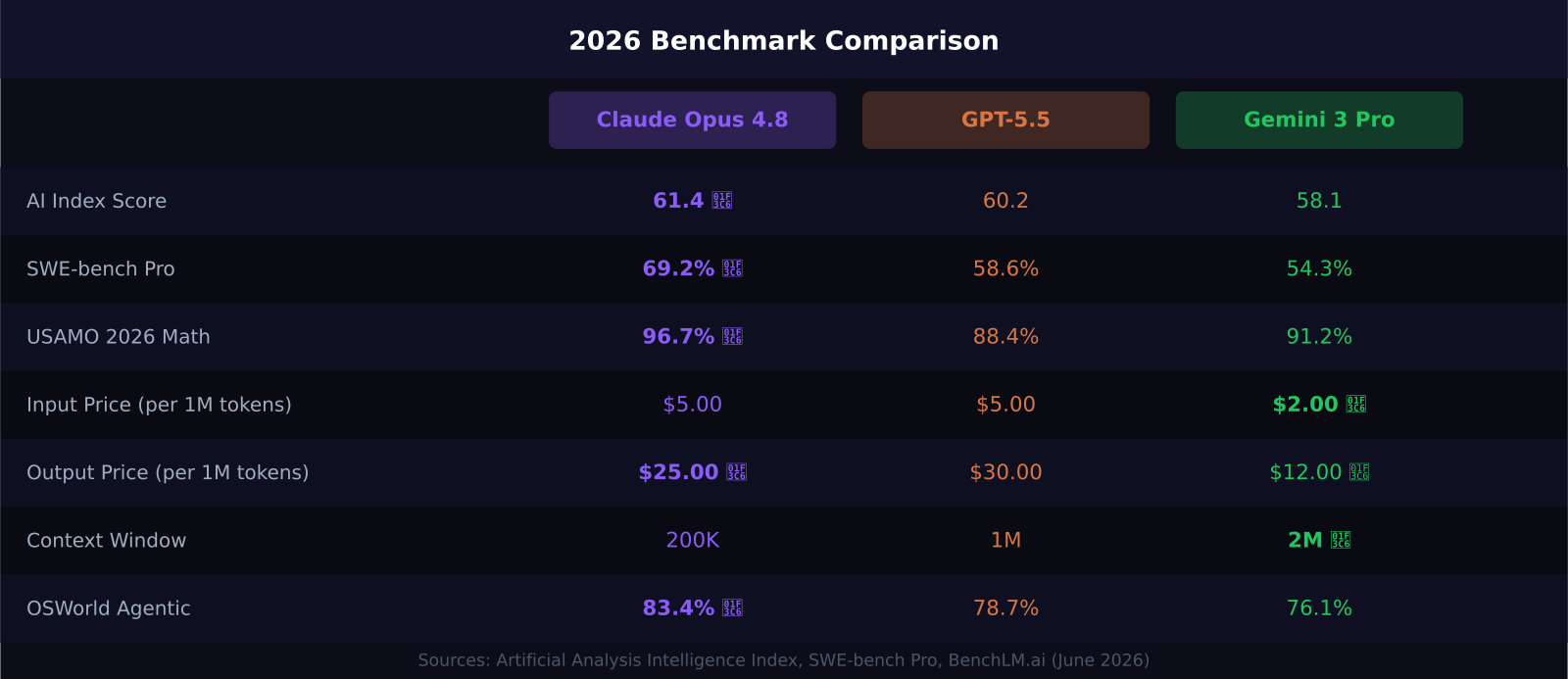
The Artificial Analysis Intelligence Index puts Opus 4.8 at 61.4, GPT-5.5 at 60.2, and Gemini 3 Pro at 58.1. That gap is real but not dramatic on general intelligence tasks.
Where Opus 4.8 breaks away from the pack is coding. Its 69.2% on SWE-bench Pro is 10 percentage points ahead of GPT-5.5 (58.6%) and about 15 ahead of Gemini 3 Pro. On USAMO 2026 math competition problems, Opus 4.8 jumped to 96.7%, up from 69.3% on the previous version — a 27-point gain that signals a genuine architectural improvement in rigorous reasoning.
For agentic tasks, Opus 4.8 also leads. It scored 83.4% on OSWorld-Verified and was the only model to complete every case on the Super-Agent benchmark. In practice, this means it handles long-running multi-step tasks with fewer dropped threads and hallucinated tool calls.
Pricing: where Gemini pulls ahead
If raw intelligence benchmarks favor Claude, the pricing picture tilts toward Gemini. At $2.00 input / $12.00 output per 1M tokens for Gemini 3 Pro, Google is roughly 60% cheaper on output tokens compared to Opus 4.8 and 75% cheaper compared to GPT-5.5 Pro.
For applications running millions of tokens per day — think customer support bots, document processing pipelines, or anything with high-volume generation — that difference compounds quickly.
The calculus shifts again when you factor in Opus 4.8's new Fast Mode: $10 input / $50 output per 1M at roughly 2.5x speed. That is a premium tier that does not undercut Gemini on price, but it is worth knowing the option exists if latency is your bottleneck.
Which is actually better for coding?
Claude Opus 4.8 is clearly the best coding model of the three right now. The 69.2% SWE-bench Pro score is the headline, but the more interesting new capability is the parallel subagent architecture in Claude Code: Opus 4.8 can plan a large refactor, spawn hundreds of subagents, and verify their outputs against your test suite before returning results. That is genuinely new behavior that GPT-5.5 and Gemini 3 Pro do not have in a comparable form today.
If you are a non-developer using an AI coding tool, you will not feel this difference directly — but the IDEs and tools built on top of these models (Cursor, Claude Code, Windsurf) increasingly exploit it under the hood.
Who wins for writing and long-context work?
GPT-5.5 still handles structured writing tasks faster and is often more consistent on shorter prompts with precise formatting requirements. For long-form writing — blog posts, reports, narrative summaries — the quality gap between all three is close enough that personal preference and interface usually matter more than the model itself.
Gemini 3 Pro is the obvious choice when context length is your constraint. Needing to process a 500-page legal document, a year of Slack history, or an entire codebase in a single prompt? The 2 million token window is the differentiator. Opus 4.8 and GPT-5.5 cap out at 200K and 1M tokens respectively.
So which model should you actually use?
For coding, agentic work, and complex multi-step reasoning: Claude Opus 4.8 is the top choice. The benchmark lead over GPT-5.5 is real and it compounds on the hardest tasks.
For structured tool-use workflows, speed-sensitive production pipelines, and teams already invested in OpenAI's ecosystem: GPT-5.5 makes sense. It is more efficient per task and more predictable on constrained formats.
For cost-sensitive applications, multimodal needs, or anything requiring massive context windows: Gemini 3 Pro offers the best value. The $2.00 input price and 2M context are hard to ignore at scale.
The most common enterprise architecture in 2026 is routing across all three: send coding tasks to Opus 4.8, high-volume generation to Gemini, and speed-critical structured tasks to GPT-5.5. That is the smart play.
Frequently asked questions
Is Claude Opus 4.8 really better than GPT-5.5?
On most benchmarks, yes. Opus 4.8 leads the Artificial Analysis Intelligence Index (61.4 vs 60.2) and has a substantial edge on coding tasks (69.2% vs 58.6% on SWE-bench Pro). GPT-5.5 is faster and more token-efficient on structured workflows, so "better" depends on your use case.
Why is Gemini 3 Pro so much cheaper?
Google is pricing Gemini aggressively to drive adoption on Google Cloud and grow its API developer base. At $2.00 / $12.00 per 1M tokens, Gemini 3 Pro is roughly 60% cheaper on output than Opus 4.8 ($25.00 output) and 60% cheaper than GPT-5.5 ($30.00 output). The trade-off is slightly lower benchmark scores on coding and agentic tasks.
Can I use all three models at once?
Yes. Multi-model routing via a single API gateway (tools like LiteLLM, PortKey, or OpenRouter) lets you send each request to the cheapest or most capable model for that specific task. This is the architecture most serious production teams use in 2026.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master