AI Tools
Claude Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash: Best AI Model for SaaS Teams in 2026

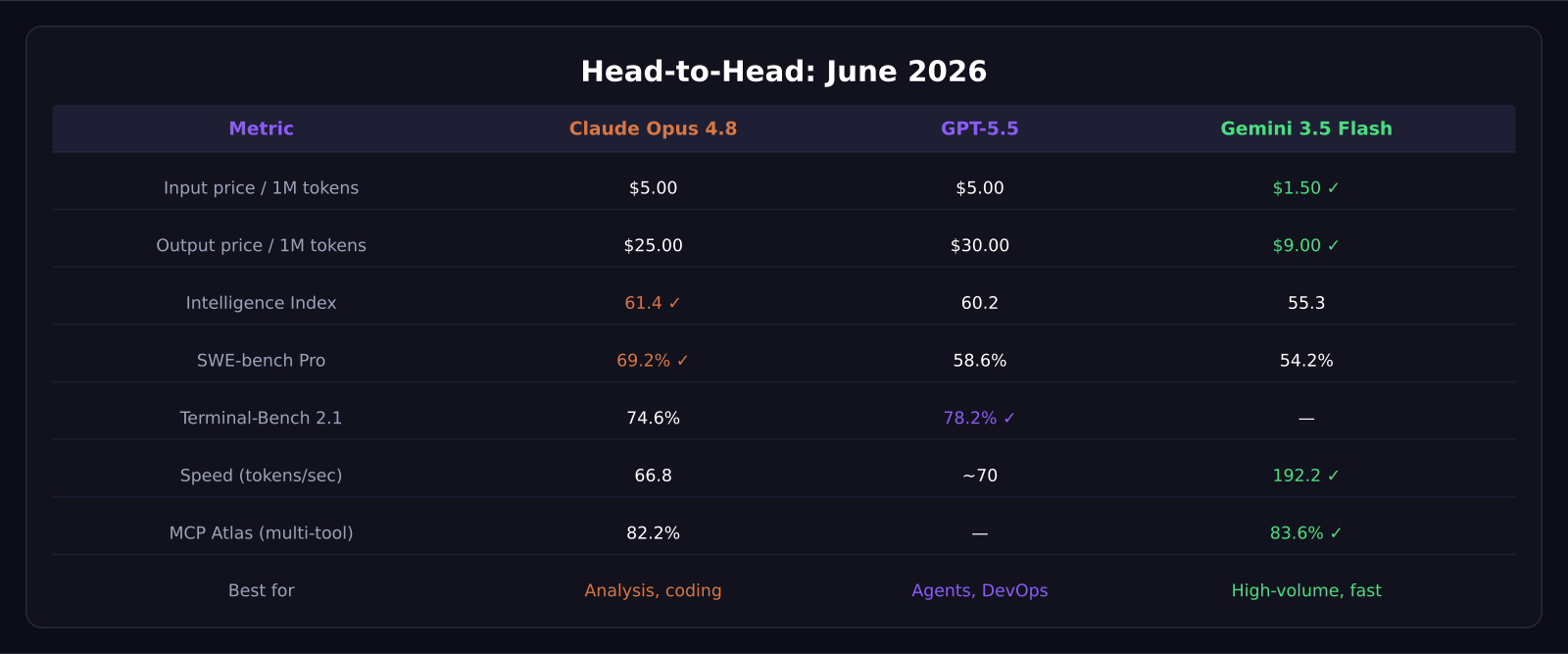
Claude Opus 4.8 tops the AI benchmarks in June 2026 with a 61.4 Intelligence Index score, but GPT-5.5 still dominates terminal automation and Gemini 3.5 Flash runs at nearly 3x the speed for a fraction of the price. The honest answer is that none of these three is the single best model — each wins in different situations, and knowing which to reach for is worth real money on your API bill.
Key takeaways
- Claude Opus 4.8 scores 61.4 on the Artificial Analysis Intelligence Index, dethroning GPT-5.5 (60.2) as the top-ranked model.
- GPT-5.5 leads agentic and terminal-automation tasks with 78.2% on Terminal-Bench 2.1.
- Gemini 3.5 Flash outputs 192.2 tokens per second — nearly 3x faster than Opus 4.8 — at $1.50 input / $9 output per million tokens.
- A three-model routing strategy can cut API costs 40 to 60% without sacrificing quality.
- All three models are available through their native APIs and through Amazon Bedrock.
How these models got here
Claude Opus 4.8 dropped on May 28, 2026, with Anthropic claiming it is the most reliable model in the Opus line for sustained, multi-step analytical work. GPT-5.5 launched April 23, 2026, as OpenAI's sharpest agentic model yet. Gemini 3.5 Flash arrived May 19, 2026, positioned as the speed and cost tier in Google's model family.
At this point, every frontier model is extremely capable at most tasks. What separates them is consistency on hard problems, cost at scale, and the edge cases that break workflows.
Pricing: who is cheapest and by how much?
Gemini 3.5 Flash is aggressively priced. At $1.50 per million input tokens and $9 per million output tokens, it undercuts both Claude Opus 4.8 ($5 in, $25 out) and GPT-5.5 ($5 in, $30 out) by a significant margin. For high-volume pipelines — think customer-facing chatbots, document summarization, or any task running thousands of calls a day — Flash can save you 60 to 70% on cost compared to either Opus or GPT-5.5.
If you are running low-volume, high-stakes tasks like legal review, financial analysis, or complex coding, the cost difference matters less than getting it right. That is where Opus 4.8 earns its price.
Which is smarter: Claude Opus 4.8 vs GPT-5.5?
On the Artificial Analysis Intelligence Index, Opus 4.8 currently holds the top spot at 61.4 versus GPT-5.5 at 60.2. That gap is small but consistent across multiple third-party benchmarks. Opus 4.8 also leads on SWE-bench Pro at 69.2% compared to GPT-5.5's 58.6%, a notable gap for any team using AI in a coding workflow.
I have run both on complex analytical tasks — drafting structured content strategy documents, auditing SaaS onboarding flows, writing production-ready code — and Opus 4.8 does catch errors that GPT-5.5 occasionally lets through. The reliability advantage is real, not just a marketing claim.
Where GPT-5.5 still wins
Despite falling behind on overall intelligence rankings, GPT-5.5 leads on Terminal-Bench 2.1 at 78.2% versus Opus 4.8's 74.6%. If your use case involves autonomous agents running CLI commands, interacting with shell environments, or orchestrating DevOps pipelines, GPT-5.5 is still the safer default. OpenAI's computer-use features are also more mature and better-documented than Anthropic's equivalent.
For teams building agentic systems on AWS, the fact that GPT-5.5 reached general availability on Amazon Bedrock in June 2026 alongside Codex makes it easier to evaluate without leaving your existing cloud infrastructure.
How fast is Gemini 3.5 Flash in practice?
The raw speed number is striking: 192.2 tokens per second versus Opus 4.8's 66.8 and GPT-5.5's roughly 70. In a real-world chat application or a pipeline generating large volumes of text, Flash is nearly three times faster. That translates to a noticeably snappier user experience and lower latency for anything customer-facing.
On multi-tool coordination benchmarks (MCP Atlas), Flash also edges ahead at 83.6% versus Opus 4.8's 82.2%. If you are building an AI layer that orchestrates multiple tools simultaneously, Flash handles the coordination surprisingly well for a model positioned as a budget option.
The smart routing strategy
The teams getting the best results in 2026 are not picking one model and committing. They route by task type:
- Code review, complex analysis, and legal or financial summaries go to Claude Opus 4.8.
- Terminal automation, CLI agents, and DevOps scripting go to GPT-5.5.
- High-volume pipelines, customer chat, multi-tool coordination, and anything latency-sensitive goes to Gemini 3.5 Flash.
This routing approach can cut your AI spend by 40 to 60% compared to running everything through a single premium model, according to engineering teams that have shared cost breakdowns publicly. The exact savings depend on your workload mix, but even a rough split saves money.
My take as someone who uses all three
For SaaS product work — writing tutorials, building walkthroughs, analyzing software features — I lean on Opus 4.8 as my default because I would rather have a second opinion that catches something than save a few cents and miss a problem. But for generating first drafts, summarizing research, or any task I am going to review myself, Flash is fast enough and cheap enough to make the premium models feel like overkill.
GPT-5.5 is the one I reach for when building or testing anything that involves running code autonomously. OpenAI has a wider ecosystem of developer tooling around agentic workflows, and it shows in the benchmark gaps on terminal tasks.
Frequently asked questions
Is Claude Opus 4.8 worth the price over GPT-5.5?
For analysis-heavy tasks and coding, yes. Opus 4.8's 61.4 Intelligence Index versus GPT-5.5's 60.2 is a small gap overall, but on SWE-bench Pro the lead grows to 69.2% versus 58.6%. If silent errors in code or analysis are costly for you, the extra reliability justifies the similar price point.
Can Gemini 3.5 Flash replace a more expensive model?
For high-volume, latency-sensitive, or multi-tool tasks, yes. Flash scores 83.6% on MCP Atlas and runs at 192.2 tokens per second. For tasks that require sustained deep reasoning or high-accuracy code generation, a premium model is still the better call.
Which model is best for building a SaaS AI feature in 2026?
It depends on the feature. Customer-facing chat or document processing: use Flash for cost and speed. Code generation or complex logic: use Opus 4.8. Any automation that touches a terminal or runs shell commands: use GPT-5.5. Routing across all three by task type is the approach serious engineering teams are using.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
