AI Tools
Kimi K2.7 Code Review: The Open-Source 1-Trillion-Parameter Coding Agent

On June 12, 2026, Moonshot AI released Kimi K2.7 Code — and it's one of the more interesting open-source model drops of the month. Not because it tops every benchmark, but because it does something most models still struggle with: it actually works through a problem the way a developer does. It plans, opens files, runs commands, reads what broke, and loops back to fix it. No hand-holding required.
Key takeaways
- Kimi K2.7 Code released June 12, 2026 by Moonshot AI — open-source, available on Hugging Face
- 1-trillion-parameter Mixture-of-Experts architecture with 32B active parameters per token
- Cuts reasoning token usage by 30% vs K2.6 — meaningfully cheaper per task at scale
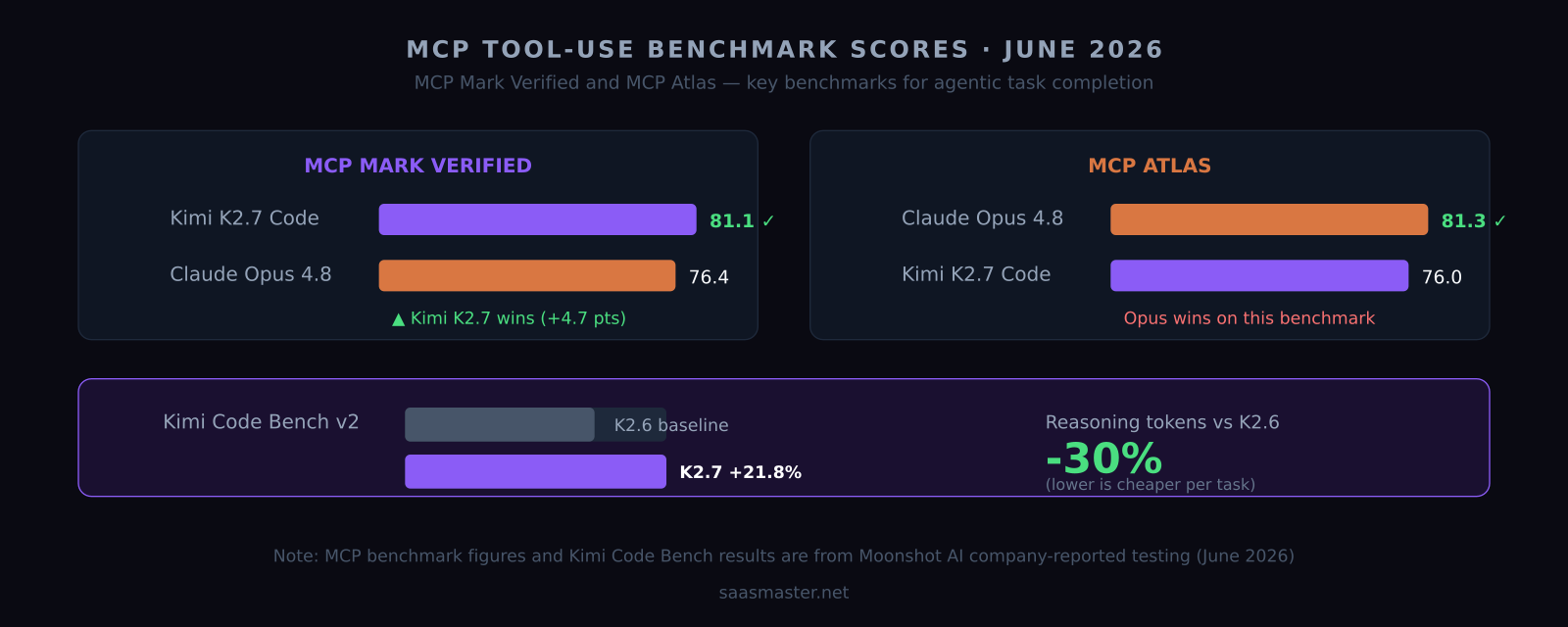
- Beats Claude Opus 4.8 on MCP Mark Verified tool-use benchmark (81.1 vs 76.4)
- Reports +21.8% improvement on Kimi Code Bench v2 over K2.6
What is Kimi K2.7 Code?
Kimi K2.7 Code is Moonshot AI's coding-specialized evolution of their K2 model family. Where K2.6 was a broad general-purpose powerhouse, K2.7 narrows and deepens: it is engineered specifically for long-horizon software engineering, where the model takes dozens or hundreds of sequential actions to complete a task rather than answer a single prompt.
The distinction is concrete. A standard LLM sees a coding question and outputs code. K2.7 Code sees a GitHub issue, forms a plan, browses the relevant files in the repository, makes targeted edits across multiple files, runs tests, reads error output, and generates a fix — the full loop. That sequence of planning, acting, observing, and adapting is what separates an agentic coding model from an autocomplete tool.
The model launched June 12 via API and for direct download on Hugging Face. Moonshot AI describes this as their most agent-capable open-source release to date.
Architecture: 1 trillion parameters, 32 billion active
K2.7 Code uses a Mixture-of-Experts architecture — the same foundational design behind DeepSeek V4 and several other current efficient frontier models. Total parameter count is 1 trillion, but only 32 billion activate per token during inference. That gap is why MoE models can approach the quality of much larger dense models at a fraction of the compute cost.
The model supports a 256,000-token context window. For software engineering tasks, that's enough room to hold a large codebase in context and reason about changes across many interconnected files simultaneously. Multi-head Latent Attention (MLA) handles the internal memory architecture.
K2.7 Code also processes multimodal inputs natively: text, images, and video. For development work, that opens up workflows that most coding tools still can't touch — feed it a screenshot of a broken UI alongside the relevant code and it can incorporate the visual context directly.
How much better is it than K2.6?
Moonshot AI reports two primary improvements, both of which matter in production.
First, thinking-token consumption drops by approximately 30% versus K2.6. Models in the reasoning category generate internal chain-of-thought tokens before answering — and those tokens are billed at normal rates even though users never see them. A 30% reduction in thinking tokens is a direct, compounding cost reduction for any high-volume agentic workload.
Second, K2.7 improves 21.8% over K2.6 on Kimi Code Bench v2. That is a substantial jump for a single model generation.
Worth noting: these figures are from Moonshot AI's own testing. Independent third-party evaluations of K2.7 Code are still emerging. The numbers are directional — treat them as a starting point for your own evaluation rather than settled fact.
How it compares to the competition
On MCP Mark Verified — a benchmark measuring autonomous multi-step task completion via tool calls — K2.7 Code scores 81.1 versus Claude Opus 4.8's 76.4. That is a meaningful result for an open-source model going up against one of Anthropic's flagship reasoning models.
On MCP Atlas, the picture reverses slightly: K2.7 scores 76.0 versus Opus 4.8's 81.3. So it is not a clean sweep across every tool-use benchmark, but K2.7 is in competitive range with models that cost significantly more.
On multi-language coding, K2.7 nearly matches GPT-5.5 on MLS Bench Lite — which is notable given that GPT-5.5 leads the Terminal-Bench 2.0 rankings by a wide margin.
The benchmarks that predict real-world agentic performance most accurately are the MCP ones. If you are building a system where an AI model calls APIs, reads files, and executes actions autonomously, those scores are the ones to care about. K2.7's win on MCP Mark Verified is directly applicable to that class of work.
Who should use Kimi K2.7 Code?
If you are building AI into a development workflow, K2.7 Code is worth a serious evaluation. The 30% thinking-token reduction versus K2.6 means lower per-task cost for equivalent output quality — and that compounds fast when you are running hundreds of agent tasks per day in production.
For teams currently using Claude Opus 4.8 for agentic coding tasks, K2.7 Code's MCP Mark result of 81.1 versus 76.4 is a direct prompt to run a side-by-side test. Open-source, no licensing friction, competitive on the benchmark that matters most for tool use.
Access is practical. Weights are on Hugging Face for self-hosting, though a 1T-parameter MoE model requires serious GPU infrastructure. Most teams will access K2.7 via API through Moonshot AI's platform or major aggregators, at pricing competitive with other Chinese frontier models.
The multimodal input support is a genuine differentiator most people are sleeping on. Most AI coding tools today work in text only. The ability to pass an image or short video clip alongside a code question opens up workflows — reviewing UI screenshots, processing error screen recordings — that simply are not possible with purely text-based models.
Frequently asked questions
How does Kimi K2.7 Code compare to GitHub Copilot?
They solve different problems. Copilot is IDE-integrated and optimized for real-time autocomplete while you write. K2.7 Code is a model you call programmatically for longer autonomous tasks — writing a feature end-to-end, diagnosing and fixing a multi-file bug, or completing a full agent loop. Think of K2.7 as a coding agent that does the work, and Copilot as an assistant that helps while you do the work.
Are Moonshot AI's benchmark numbers independently verified?
Not fully yet. The +21.8% on Kimi Code Bench v2 and the company-run coding results are Moonshot AI's own figures. MCP Mark Verified and MCP Atlas are more widely tracked benchmarks, and K2.7 Code's scores there have appeared in independent coverage, but comprehensive third-party evals are still coming. Treat the numbers as directional until more external results arrive.
What hardware do you need to self-host Kimi K2.7 Code?
Running a 1T-parameter MoE model locally requires significant infrastructure — multiple high-end data center GPUs. The MoE architecture activates only 32B parameters per token, which reduces memory requirements compared to a dense 1T model, but it is still not a machine you spin up on a laptop. Most teams will use the API rather than self-hosting.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
