AI Tools
DeepSeek V4 vs Kimi K2.6 vs GLM-5.2: Which Chinese Open-Weight AI Wins in 2026?

Three Chinese AI labs have each released an open-weight model in 2026 that outperforms at least one American frontier model on a major coding benchmark. DeepSeek V4, Kimi K2.6, and GLM-5.2 are the three worth comparing — and together they represent the most competitive open-weight AI ecosystem that has ever existed, all available under MIT licenses you can download, self-host, and fine-tune today.
Key takeaways:
- GLM-5.2 leads on SWE-bench Pro (62.1%), ahead of GPT-5.5 (58.6%) and Kimi K2.6 (58.6%)
- DeepSeek V4-Pro is the cheapest flagship at $0.87/M output — up to 34x less than GPT-5.5's $30/M
- Kimi K2.6 has the most advanced agent architecture, with a native Agent Swarm coordinating up to 300 sub-agents
- All three run on MIT open-source licenses — freely downloadable, globally accessible, self-hostable
- The newest is GLM-5.2 (June 16, 2026); DeepSeek V4 and Kimi K2.6 both launched in late April 2026
Why does this comparison matter right now?
Eighteen months ago, the question was whether Chinese AI labs could compete with OpenAI and Google. Today the question is which Chinese open-weight model best fits your use case. That shift happened faster than most Western developers expected.
DeepSeek-R1 broke through at the end of 2024 with a cost-performance combination that shook the industry. Kimi K2.6 followed in April 2026 as the first open-weight model to beat GPT-5.4 on SWE-bench Pro. GLM-5.2 extended that lead in June 2026. DeepSeek V4, released the same week as Kimi K2.6, became the cheapest way to access near-frontier coding intelligence by a significant margin.
All three are MIT-licensed with no regional restrictions. That openness is a large part of why they are increasingly the default starting point for developers building AI-powered products — especially those running inference at scale where API costs matter.
What are DeepSeek V4, Kimi K2.6, and GLM-5.2?
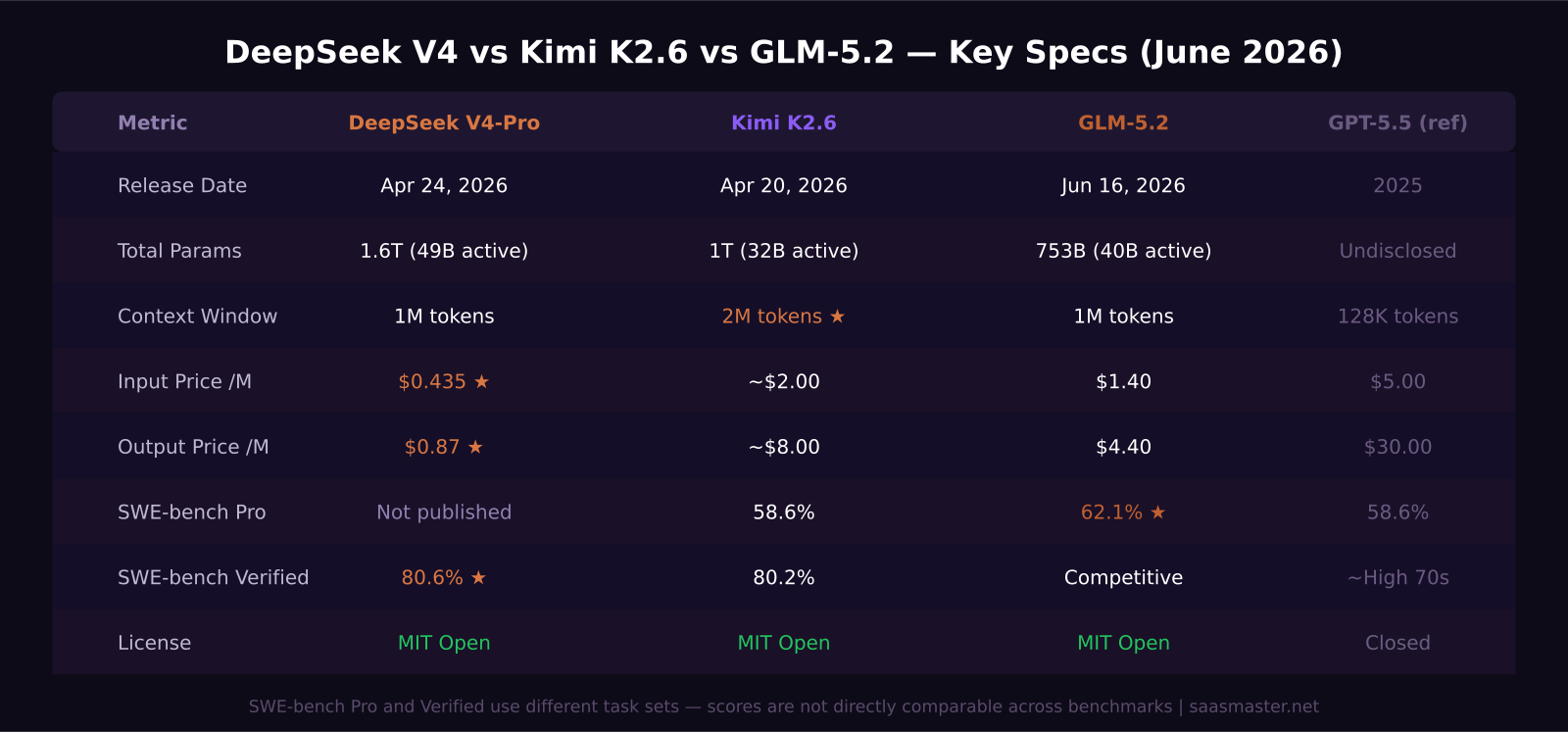
DeepSeek V4 was released April 24, 2026 by DeepSeek, a subsidiary of the Chinese quantitative hedge fund High-Flyer. It comes in two variants: V4-Pro with 1.6 trillion total parameters and 49 billion active per token, and V4-Flash with 284 billion total and 13 billion active. Both support a 1-million-token context window. V4-Pro is the variant that leads coding leaderboards and price comparison tables. Pricing is $0.435 per million input tokens and $0.87 per million output tokens — permanent rates locked in on May 22, 2026, after an initial promotional period.
Kimi K2.6 was released April 20, 2026 by Moonshot AI, a Beijing lab founded in 2023 that has grown rapidly on the strength of its long-context capabilities. It is a 1-trillion-parameter MoE with 32 billion active parameters per token. Its signature feature is Agent Swarm, a native architecture that lets it coordinate up to 300 parallel sub-agents across up to 4,000 coordinated steps — the largest autonomous agent orchestration any model has shipped as a built-in primitive. Context window is 2 million tokens in early tests, making it the clear long-context leader among these three. API pricing is approximately $2 per million input tokens and $8 per million output tokens.
GLM-5.2 was released June 16, 2026 by Z.ai, formerly known as Zhipu AI, a Tsinghua University spinout that has been building large language models since 2019. It is a 753-billion-parameter MoE with 40 billion active parameters per token and a 1-million-token context window. It was built entirely on Huawei Ascend chips — no NVIDIA hardware. API pricing is $1.40 per million input tokens and $4.40 per million output tokens, under MIT license with explicitly no regional restrictions.
How do the benchmarks compare?
SWE-bench Pro is the most meaningful benchmark for agentic coding work right now. It tests real multi-file software engineering tasks rather than isolated puzzles, and it is harder to game with scaffolding tricks than the standard SWE-bench Verified.
GLM-5.2 leads on SWE-bench Pro at 62.1%. Kimi K2.6 scores 58.6%, identical to GPT-5.5's result on the same test. DeepSeek V4's SWE-bench Pro numbers have not been published separately, though its SWE-bench Verified score of 80.6% leads all open-weight models on that broader benchmark. Kimi K2.6 scored 80.2% on SWE-bench Verified when it launched.
On FrontierSWE, a benchmark specifically designed for long-horizon autonomous engineering, GLM-5.2 scored 74.4%, just below Claude Opus 4.8's 75.1% and above GPT-5.5's 72.6%.
For math reasoning and general intelligence tasks, DeepSeek V4 and Qwen3.5-397B lead the Chinese open-weight field. GLM-5.2 and Kimi K2.6 are competitive but were not specifically optimized for those benchmarks in their current versions.
Which is cheapest to run at scale?
DeepSeek V4-Flash wins on raw price for output-heavy workloads at $0.28 per million output tokens. Among flagship-tier models, DeepSeek V4-Pro at $0.87 per million output is the cheapest option that scores above 80% on SWE-bench Verified.
For the specific combination of SWE-bench Pro performance and API price, GLM-5.2 offers the strongest ratio right now. It leads the benchmark and costs $4.40 per million output tokens versus GPT-5.5's $30 — roughly 6.8 times cheaper on the metric that drives most agent pipeline bills.
Kimi K2.6 at approximately $8 per million output tokens is the most expensive of the three Chinese models, but its Agent Swarm architecture can replace what would otherwise require multiple model calls in a coordinated pipeline, which changes the effective cost calculation for complex workflows.
Which has the best agent capabilities?
Kimi K2.6 has the most explicit agent-native design of the three. Its Agent Swarm primitive is the only built-in mechanism that lets a single model call out to 300 parallel sub-agents coordinating up to 4,000 steps. If you are building a complex autonomous engineering pipeline — say, a system that simultaneously runs tests, fixes bugs, writes documentation, and validates changes across a large monorepo — Kimi K2.6's architecture is purpose-built for that at a level no other open-weight model currently matches natively.
DeepSeek V4-Pro is strong for agentic coding when paired with external scaffolding such as OpenHands, Claude Code, or custom orchestration layers. It does not have a native multi-agent primitive, but its raw benchmark performance means the underlying capability is there when you build the scaffolding yourself.
GLM-5.2 focuses on sustained long-horizon tasks within a single context window. Its FrontierSWE score reflects that strength — excellent at long, complex coding sessions without needing to fan out to sub-agents. For simpler agent designs where one model handles everything in one thread, that approach has real advantages in predictability and cost.
Who should use which model?
For developers building coding agents where benchmark performance on real-world tasks is the primary signal, GLM-5.2 is the current leader on SWE-bench Pro and is the most cost-effective at that performance level. Start there for agent pipelines.
For teams that need the absolute lowest API cost at the flagship tier, DeepSeek V4-Pro at $0.87 per million output tokens is unmatched among models that score above 80% on SWE-bench Verified. If budget is the primary constraint and you are comfortable building your own orchestration layer, V4-Pro is the right choice.
For builders working on large-scale autonomous systems that need to coordinate hundreds of parallel tasks, Kimi K2.6's Agent Swarm is the most developed native solution available in any open-weight model today. The higher price is offset by the reduction in orchestration complexity.
For teams that need infrastructure independence from both American software and NVIDIA hardware — whether for regulatory reasons, supply chain diversification, or geopolitical considerations — GLM-5.2 built on Huawei Ascend and MIT-licensed for self-hosting is the most proven option at frontier performance levels.
For general reasoning, writing, multilingual tasks, and use cases outside of coding, none of these three is the obvious first choice. Qwen3.5-397B handles multilingual tasks better than any of them and is available at $0.10 per million input tokens in its Flash variant.
What does this mean for SaaS builders?
A year ago, the practical decision for most SaaS developers was which US model provider to build on. Today that calculus has shifted. The Chinese open-weight ecosystem offers lower API costs, competitive or superior benchmark performance on coding tasks, and MIT-licensed weights you can self-host or fine-tune without vendor lock-in.
The trade-off is ecosystem maturity. OpenAI's tooling integrations, Anthropic's safety documentation and enterprise support, and Google's platform breadth are still ahead of what these three labs provide on the developer experience side. Enterprise agreements, compliance documentation, and community plugin support are more developed on the US side.
But for developers who are willing to work with slightly thinner tooling in exchange for significantly lower costs and strong benchmark performance, DeepSeek V4, Kimi K2.6, and GLM-5.2 are now serious production options. The question is no longer whether to consider them — it is which one fits your specific workload.
Frequently asked questions
Which Chinese AI model is best for coding in 2026?
On SWE-bench Pro, GLM-5.2 currently leads at 62.1%, followed by Kimi K2.6 at 58.6%. On SWE-bench Verified, DeepSeek V4-Pro-Max leads all open-weight models at 80.6%, with Kimi K2.6 close behind at 80.2%. All three significantly outperform their price-equivalent US competitors. The best choice depends on which benchmark better reflects your actual workload and whether raw score or agent architecture matters more.
Are these Chinese models safe to use in enterprise applications?
All three are MIT-licensed and can be run on your own infrastructure, giving you full control over data. DeepSeek, Moonshot AI, and Z.ai all offer commercial API tiers with standard enterprise agreements for cloud access. As with any third-party AI provider, review the data processing terms before sending sensitive data through the cloud API rather than self-hosting.
How does DeepSeek V4-Pro compare to GPT-5.5 on price?
DeepSeek V4-Pro costs $0.87 per million output tokens. GPT-5.5 costs $30 per million output tokens. Per output token, DeepSeek V4-Pro is approximately 34 times cheaper than GPT-5.5, while scoring above 80% on SWE-bench Verified — a benchmark on which GPT-5.5 is not a clear leader.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
