AI Tools
GLM-5.2 Review: The Open-Weight Chinese AI That Just Beat GPT-5.5 on Coding

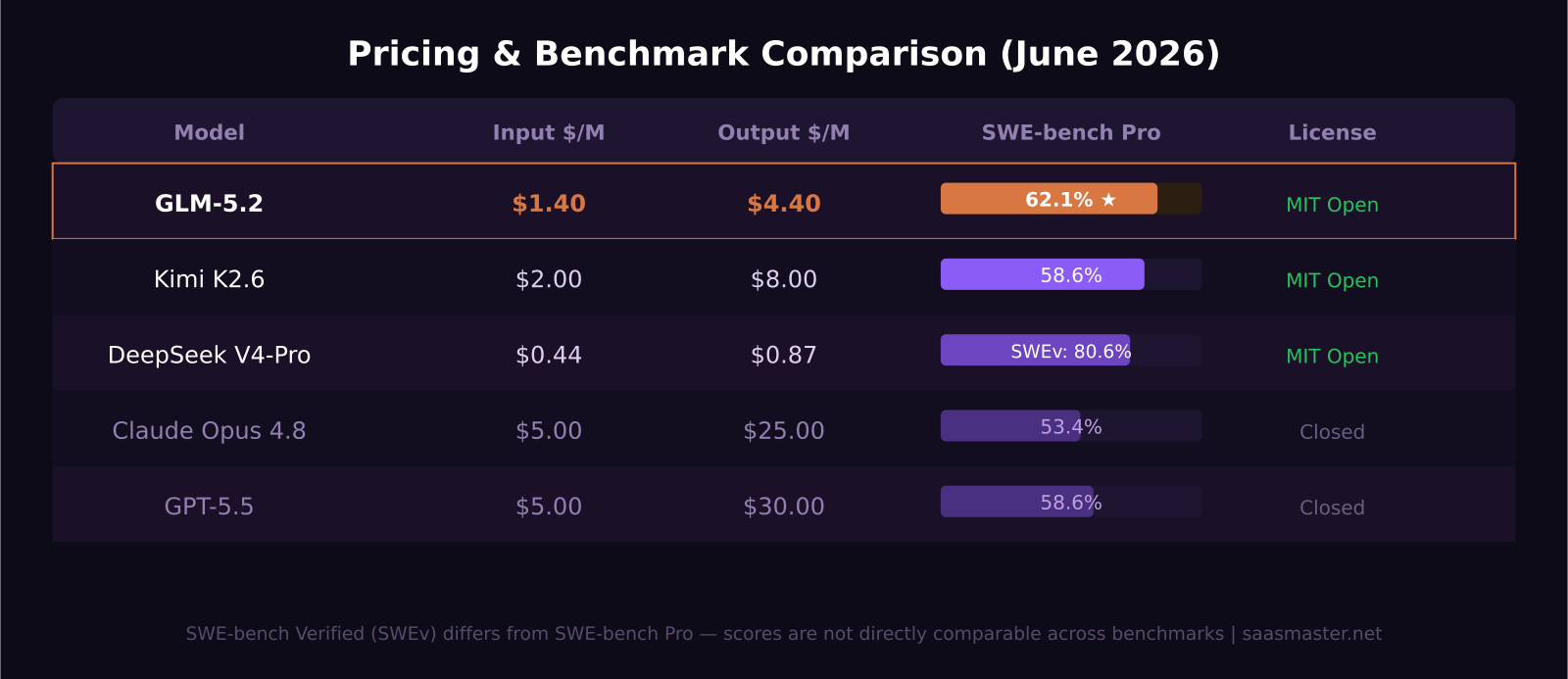
GLM-5.2 scored 62.1% on SWE-bench Pro when it launched on June 16, 2026 — ahead of GPT-5.5 at 58.6%, and it costs $1.40 per million input tokens, which is one-sixth what OpenAI charges for GPT-5.5. Released by Beijing-based Z.ai under a fully permissive MIT license with no regional restrictions, GLM-5.2 is the strongest open-weight coding model currently available by most published benchmarks.
Key takeaways:
- GLM-5.2 scores 62.1% on SWE-bench Pro, topping GPT-5.5 (58.6%) on the hardest long-horizon coding test
- API pricing is $1.40/M input and $4.40/M output — roughly one-sixth the cost of GPT-5.5 ($5/$30)
- Built entirely on Huawei Ascend chips — no NVIDIA hardware was used at any stage
- Released under MIT open-source license with no regional access restrictions
- 753 billion total parameters, 40 billion active per token, 1-million-token context window
What is GLM-5.2, and who built it?
Z.ai is the company behind GLM-5.2. Previously known as Zhipu AI, it is a spinout from Tsinghua University that has been building large language models since 2019. The company renamed itself Z.ai in early 2026 as it pushed harder into global markets.
The GLM series (General Language Model) has been Zhipu's flagship line since GLM-1. GLM-5.2 follows GLM-5.1, which scored 58.4% on SWE-bench Pro and was already competitive with US frontier models. The 5.2 release is described by Z.ai as a targeted capability upgrade rather than a full architecture overhaul — the biggest changes are a quadrupled context window and significant gains on long-horizon autonomous coding tasks.
The architecture is a mixture-of-experts (MoE) design with 753 billion total parameters and 40 billion active per forward pass. That active parameter count puts it roughly in the same compute tier as other leading MoE models. Context window is 1 million tokens, matching Kimi K2.6 and exceeding what most US labs currently offer via standard API access.
What benchmarks did GLM-5.2 actually hit?
The number that matters most right now is SWE-bench Pro. This benchmark is designed to simulate real-world engineering tasks — not isolated code puzzles, but multi-file codebases with dependencies, realistic debugging scenarios, and tasks that take more than a few steps to complete. It is harder than the standard SWE-bench Verified, which has become easier to manipulate with scaffolding tricks.
On SWE-bench Pro, GLM-5.2 scored 62.1%. For reference, the other top results as of June 2026 are GPT-5.5 at 58.6%, Kimi K2.6 at 58.6%, and Claude Opus 4.8 at 53.4%.
On FrontierSWE, a benchmark specifically designed to test long-horizon autonomous coding sessions, GLM-5.2 hit 74.4%. Claude Opus 4.8 scored 75.1% on the same benchmark, and GPT-5.5 scored 72.6%. GLM-5.2 essentially ties the frontier on this test while costing a fraction of the price.
Outside of coding, GLM-5.2 is competitive but not dominant. Z.ai's stated focus for this release was explicitly on autonomous engineering. For general reasoning, writing, and multimodal tasks, models like GPT-5.5 and Qwen3.5-397B remain ahead.
How does GLM-5.2 pricing compare to the competition?
This is where the model becomes hard to ignore for anyone running coding agents at scale.
GLM-5.2 API pricing via Z.ai or OpenRouter is $1.40 per million input tokens, $4.40 per million output tokens, and $0.26 per million cached input tokens. For comparison, GPT-5.5 sits at $5 input and $30 output. Claude Opus 4.8 is $5 input and $25 output. Kimi K2.6 is approximately $2 input and $8 output. DeepSeek V4-Pro undercuts everyone on output cost at $0.87 per million.
For most coding agent workloads, output tokens dominate the cost. At $4.40/M output versus GPT-5.5's $30/M, GLM-5.2 is about 6.8x cheaper on the metric that actually drives bills. Combine that with a higher SWE-bench Pro score than GPT-5.5, and the value proposition is straightforward.
Z.ai also offers an enterprise coding subscription starting at $12.60 per month, which includes prioritized GLM-5.2 access for coding tasks. For smaller teams who do not want to manage API credits, that is a reasonable entry point.
What does it mean that GLM-5.2 runs on Huawei Ascend chips?
Every GPU in GLM-5.2's training and inference stack is a Huawei Ascend chip — not a single NVIDIA H100 or H200. This matters for two reasons.
First, it is a proof of concept that frontier-level model performance does not require NVIDIA hardware. US export controls on advanced semiconductors were intended to slow China's AI development. GLM-5.2's benchmark results suggest that at a minimum, those controls are not preventing results at the top of coding leaderboards, even if they are adding friction and cost to the compute process.
Second, there is a practical angle for enterprise buyers in certain markets. If your organization operates in a region with restrictions on American technology, or if supply chain independence from NVIDIA matters to your procurement team, Z.ai's infrastructure offers a fully operational alternative with verified performance numbers.
Z.ai has not published detailed training compute figures, so a precise cost-efficiency comparison with US-trained models is not possible. The benchmark results, however, are independently verifiable and consistent across multiple testing organizations.
Is the MIT license actually unrestricted?
Yes, and Z.ai's documentation is explicit about it. The GLM-5.2 weights are available on Hugging Face under the standard MIT license. The release notes state directly: no regional limits, no usage restrictions, technical access without borders.
This stands in contrast to some earlier open-weight Chinese models that carried restrictions on commercial use outside China or in specific regulated industries. Z.ai is clearly competing for global developer adoption, and an unrestricted MIT license with that explicit language is the strongest possible signal in that direction.
You can download the weights, run GLM-5.2 locally with sufficient hardware, fine-tune on your own data, and deploy in any jurisdiction. For a 753 billion parameter MoE model, this level of openness is notable. Self-hosting requires significant hardware — Z.ai's documentation references 8x H200 for full-precision inference — but quantized community versions are available on Hugging Face for smaller setups, and cloud providers including OpenRouter, Together AI, and others are offering hosted inference.
Who should use GLM-5.2 right now?
If you are building or running coding agents — automated pull request reviewers, autonomous bug fixers, code migration tools, or AI-assisted code review pipelines — GLM-5.2 is the most cost-effective option at the top of the SWE-bench Pro table right now. Its combination of score and price is unmatched among currently published results.
If you want to experiment with a frontier-class model on your own infrastructure, the MIT weights are available today. Cloud providers have deployments running and inference times are practical.
If your use case is general reasoning, writing, analysis, or multimodal tasks, GLM-5.2 is capable but not the clear winner. For those workloads, GPT-5.5, Claude Opus 4.8, or Qwen3.5-397B may be better fits depending on your specific requirements.
For SaaS builders who are anchoring product features on an AI model, GLM-5.2 is worth adding to your evaluation. The pricing makes extended testing inexpensive, and the benchmark performance means you are not making a compromise to save money.
What does GLM-5.2 mean for the broader market?
This is the third time in 18 months that a Chinese open-weight model has landed above a US closed-weight frontier model on a major coding benchmark. DeepSeek R1 did it in late 2024. Kimi K2.6 did it on SWE-bench Pro in April 2026. GLM-5.2 has now extended that lead, and Z.ai did it on Huawei hardware with MIT-licensed weights.
The pattern suggests the performance gap between US and Chinese AI labs has effectively closed for agentic coding tasks. What remains is ecosystem advantage — tooling depth, integration breadth, brand recognition in enterprise sales, and regulatory clarity in Western markets. Those factors still favor OpenAI and Anthropic.
But for developers who prioritize benchmark performance and cost over ecosystem comfort, the Chinese open-weight models are now a serious first choice. GLM-5.2 is the clearest single example of that shift.
Frequently asked questions
Is GLM-5.2 better than GPT-5.5?
On SWE-bench Pro, GLM-5.2 scores 62.1% versus GPT-5.5's 58.6%, making it the stronger coding model on that specific benchmark. For general reasoning, writing, and multimodal tasks, GPT-5.5 remains ahead. Which model is better depends entirely on your use case — GLM-5.2 was specifically optimized for long-horizon autonomous coding.
Can I run GLM-5.2 locally?
Yes. The weights are on Hugging Face under the MIT license. Full-precision inference is hardware-intensive, with Z.ai referencing 8x H200 in their self-hosting documentation. Quantized community builds exist for smaller setups. Hosted inference is also available through OpenRouter, Together AI, and other providers at the published API rates.
How does GLM-5.2 compare to DeepSeek V4?
DeepSeek V4-Pro is significantly cheaper ($0.435/$0.87 per million tokens versus GLM-5.2's $1.40/$4.40) and leads SWE-bench Verified at 80.6%. On SWE-bench Pro specifically, GLM-5.2's 62.1% is ahead of published DeepSeek V4 Pro numbers on that particular test. The right model depends on which benchmark better reflects your workload and whether cost or raw score matters more at your usage volume.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
