AI & SaaS
MiniMax M3 Is Here: The Open-Weight AI Model That Beats GPT-5.5 at 5% of the Cost

MiniMax M3 launched June 1, 2026, and the headline number is genuinely striking: it scores higher than GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro — one of the most trusted coding benchmarks in the industry — at roughly 5 to 10 percent of the price per million tokens. If you are building on AI right now and you have not looked at M3 yet, this post will change that.
Key takeaways
- MiniMax M3 launched June 1, 2026 as the first open-weight model to combine a 1M-token context window, frontier coding, and native multimodality
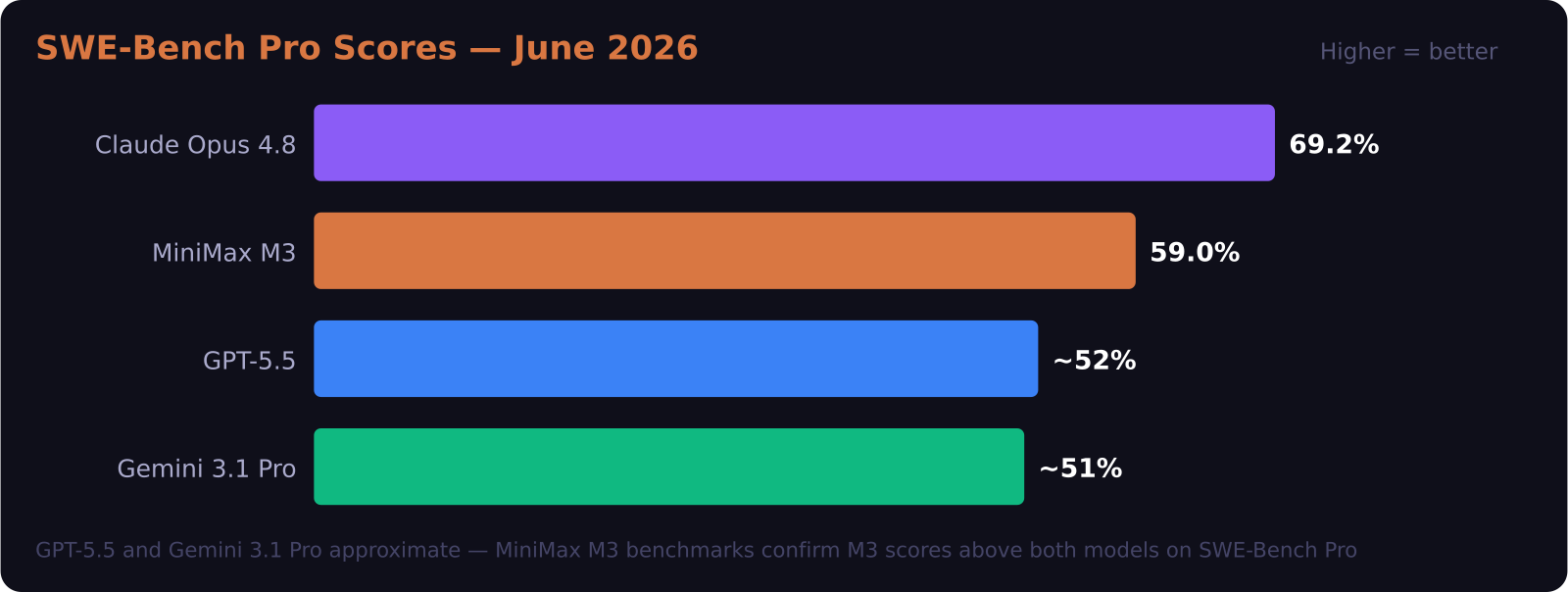
- It scores 59.0% on SWE-Bench Pro, beating GPT-5.5 and Gemini 3.1 Pro (though trailing Claude Opus 4.8's reported 69.2%)
- Pricing starts at $0.60 per million input tokens and $2.40 per million output tokens, with a 50% promotional discount currently active
- The new MSA architecture cuts per-token compute at 1M context to one-twentieth of the prior generation — more than 9x faster prefill, more than 15x faster decode
- Open weights and a technical report are coming to Hugging Face and GitHub within weeks of the launch
Why MiniMax M3 is a bigger deal than most coverage suggests
The pattern with models from non-US AI labs is that they get covered in a brief news cycle and then get underestimated by Western builders who default to OpenAI and Anthropic. M3 is the model most likely to disrupt that pattern.
The reasons: it is open-weight, which means you can run it yourself, fine-tune it, and avoid API dependency entirely. It has a 1M-token context window that is not a marketing claim but an engineering fact backed by a new attention architecture. And it costs a fraction of what GPT-5.5 or Gemini 3.1 Pro cost at scale. For SaaS builders running AI features in their product, the cost math alone justifies a serious evaluation.
What MiniMax Sparse Attention actually changes
Most large language models struggle with long context windows because compute cost scales quadratically with context length. The standard transformer attention mechanism has to look at every token relative to every other token, which becomes exponentially expensive past 100K tokens.
MiniMax's MSA architecture cuts that cost to one-twentieth of the previous generation at 1M-token context. Practically, this means M3 can process a full product codebase, a year of customer support transcripts, or a large legal document in a single context window — without the latency and cost that make 1M-token context impractical with other models.
The speed gains are significant: more than 9x faster prefilling and more than 15x faster decoding at 1M-token context compared to M3's predecessor. Speed matters enormously in agentic workflows where you are chaining multiple model calls.
How does M3 benchmark against the current frontier?
SWE-Bench Pro, which tests real-world coding on actual GitHub issues, is where M3 makes its clearest case. M3 scores 59.0%, which beats both GPT-5.5 and Gemini 3.1 Pro. Claude Opus 4.8 still leads the pack at a reported 69.2% — so M3 is not the absolute top of the field on coding, but it sits clearly above two of the most widely deployed frontier models.
Terminal-Bench 2.1, which tests autonomous terminal task execution, puts M3 at 66.0%. This positions it as a credible choice for agentic workflows where the model is running shell commands, executing code, and iterating on outputs without human intervention.
BrowseComp, which tests web browsing and information extraction, comes in at 83.5 — strong for agentic tasks involving pulling and synthesizing information from the web.
The benchmark caveat worth keeping: M3's numbers were published by MiniMax, and independent third-party reproduction is still in progress. As with any new model, the self-reported numbers are a starting point, not a final verdict.
What does MiniMax M3 actually cost?
At launch, M3 is priced at $0.60 per million input tokens and $2.40 per million output tokens on OpenRouter and the MiniMax API. A 50% promotional discount is active at launch, bringing effective costs to approximately $0.30 per million input tokens and $1.20 per million output tokens.
For context: Claude Opus 4.8 is priced at $5 per million input tokens. If you are running a SaaS product with AI features that process large amounts of text — customer support, document analysis, code review — the difference in per-token cost is the difference between an AI feature that works economically and one that destroys your margin.
Monthly token plan subscriptions are also available directly from MiniMax at roughly $20, $50, and $120 tiers that bundle a fixed volume at a predictable monthly cost.
Who should actually use MiniMax M3?
M3 is best suited for builders, not end users. If you are a SaaS founder or developer thinking about where to plug in a model, M3 is worth direct evaluation for these specific cases:
Long-context document work. Legal tech, compliance, research, and financial analysis applications that need to process large documents in a single pass benefit directly from the 1M context window with fast decode speed.
Cost-sensitive AI features. Any SaaS product where you are passing user text through a model at volume. The pricing gap between M3 and GPT-5.5 or Opus 4.8 is large enough to significantly change unit economics at scale.
Agentic coding workflows. The Terminal-Bench 2.1 score and SWE-Bench performance suggest M3 is a credible backend model for coding agents and automated engineering workflows — particularly where cost efficiency matters more than reaching Claude Opus 4.8's ceiling.
Open-weight fine-tuning. Once the Hugging Face weights are released, M3 becomes available for fine-tuning on your own data — something you cannot do with GPT-5.5 or most closed frontier models.
The honest limitations
The benchmark caveats are real. Third-party reproduction of M3's SWE-Bench results is still early, and frontier model claims from newer labs have historically benefited from favorable benchmark setups. Run your own evals before committing a production pipeline to M3.
The open weights are not out as of early June 2026. The technical report and model weights are expected within ten days of the June 1 launch — the MiniMax Hugging Face page is the place to watch.
And for applications where you need the absolute highest quality on complex reasoning and multimodal tasks, Claude Opus 4.8 still leads the field. M3 is the cost-efficiency play at frontier-adjacent quality, not the maximum-quality choice.
Frequently asked questions
Is MiniMax M3 open-source?
MiniMax M3 is open-weight, meaning the model weights will be publicly available on Hugging Face and GitHub along with a technical report. This is different from fully open-source, which would also include training data and code, but it does allow self-hosting, fine-tuning, and independent deployment without API dependency.
How does MiniMax M3 compare to Claude Opus 4.8?
On SWE-Bench Pro, Claude Opus 4.8 scores a reported 69.2% versus M3's 59.0% — a meaningful gap on coding benchmarks. Claude Opus 4.8 is also more expensive at $5 per million input tokens versus M3's $0.60. The choice depends on whether you need maximum coding performance or cost-efficient frontier-adjacent performance at scale.
Where can I access MiniMax M3?
M3 is available through the MiniMax API, on OpenRouter, and through MiniMax Code. Monthly subscription token plans are offered directly from MiniMax. Open weights on Hugging Face were expected within days of the June 1, 2026 launch.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
