AI & SaaS
Gemini 3.5 Flash vs DeepSeek V4-Pro vs Claude Sonnet 4.6: Best Value AI Model in 2026

For most teams trying to keep their AI bill sane in 2026 without shipping worse answers, the best value model is DeepSeek V4-Pro on raw cost, Gemini 3.5 Flash on speed-per-dollar for everyday work, and Claude Sonnet 4.6 when you want a dependable middle ground from a major Western provider. The "cheapest" and the "best value" are not the same question — here is how the three line up when you weigh price against what you actually get.
I lean on these models constantly to draft scripts, summarize documentation, and generate first-pass code for the tools I review. That is exactly the kind of high-volume, quality-sensitive work where picking the right mid-tier model saves real money. Below is the head-to-head.
One framing worth setting up front: the AI market in 2026 has split into three rough tiers — frontier flagships that cost a premium, ultra-cheap open-weight models that have closed most of the quality gap, and fast mid-tier models tuned for everyday production work. These three contenders straddle that second and third tier, which is exactly where most real product workloads live. You rarely need a flagship for summarizing a support ticket; you need something good enough, fast enough, and cheap enough to run millions of times. That is the bracket we are comparing.
Key takeaways
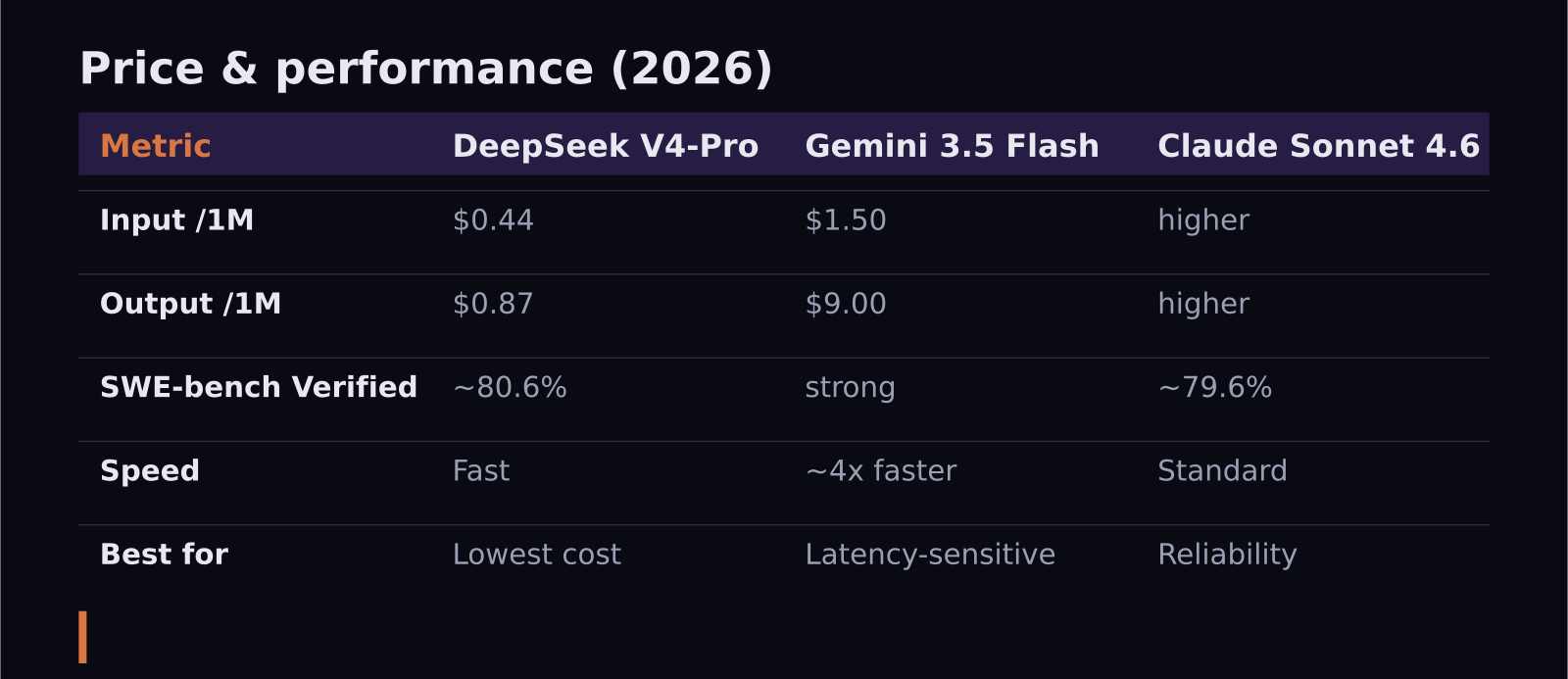
- DeepSeek V4-Pro is the cost leader at about $0.44 in / $0.87 out per million tokens after its permanent 75% price cut — roughly 11x cheaper on input than GPT-5.5.
- Gemini 3.5 Flash launched May 19, 2026 at $1.50 / $9.00 per million tokens, is about 4x faster than comparable frontier models, and delivers strong intelligence-per-dollar.
- Claude Sonnet 4.6 sits higher on price but offers the polish, reliability, and ecosystem of a major Western lab.
- On SWE-bench Verified, DeepSeek V4-Pro reports about 80.6%, putting open-weight quality within striking distance of frontier proprietary models.
- The right pick depends on whether you optimize for absolute cost, speed, or vendor trust and integration.
Which is cheapest, and by how much?
DeepSeek V4-Pro is the clear cost winner. After DeepSeek made its 75% discount permanent in May 2026, standing rates are about $0.435 per million input tokens and $0.87 per million output tokens. That is roughly 11.5x cheaper than GPT-5.5 on input and around 34x cheaper on output. If you run high volumes of summarization, classification, or code generation, that gap compounds into thousands of dollars a month.
Gemini 3.5 Flash is more expensive than DeepSeek at $1.50 / $9.00 per million tokens — notably, about 3x the price of the Flash model it replaced, which is part of a broader trend of "cheap" tiers creeping up in 2026. But Flash earns its keep through speed and efficiency rather than rock-bottom pricing.
Claude Sonnet 4.6 is the priciest of the three here, and it is not trying to win on cost. It competes on consistency, safety tuning, and how well it slots into existing Anthropic-based workflows.
Which gives the most performance per dollar?
This is the real "value" question. Gemini 3.5 Flash delivers roughly 6.1 intelligence points per dollar of output cost — nearly 3x more efficient than Claude Opus 4.6 and about 3.6x more efficient than GPT-5.5 on that measure. It is also about 4x faster than comparable frontier models and scores around 76% on Terminal-Bench 2.1, so for interactive, latency-sensitive products it punches well above its price.
DeepSeek V4-Pro is the efficiency king on pure reasoning cost. Its 80.6% on SWE-bench Verified puts it shoulder-to-shoulder with frontier models, and it scores about 93.5% on LiveCodeBench. It is frequently described as the second-strongest open-weight reasoning model available, behind only Kimi K2.6 — frontier-adjacent quality at a fraction of frontier prices.
Claude Sonnet 4.6's value is harder to put in a single number. It scores around 79.6% on SWE-bench Verified, which trails the other two on paper, but for a lot of teams the reason to pay more is reliability under real workloads, predictable behavior, and the comfort of a major provider with strong tooling and support.
So which should you actually use?
If your priority is the lowest possible cost for serious reasoning and code, DeepSeek V4-Pro is hard to argue against — just weigh the considerations that come with routing data to a non-Western provider, which matters for some businesses and not others.
If you are building anything user-facing where latency is felt — chat, autocomplete, live assistants — Gemini 3.5 Flash's speed and multimodal support make it the pragmatic default, and its efficiency keeps the bill reasonable.
If you want a known-quantity Western model with strong guardrails and ecosystem fit, and the budget allows, Claude Sonnet 4.6 is the safe, polished choice. The smartest setup for most teams is routing: cheap models for the easy 80% of requests and a stronger model for the hard 20%.
A real example: what this saves at scale
Numbers make the trade-off concrete. Imagine a product that processes 500 million input tokens and 100 million output tokens a month — a realistic figure for a busy summarization or support feature. On GPT-5.5 at $5.00 / $30.00, that is roughly $2,500 in input plus $3,000 in output, about $5,500 a month. On DeepSeek V4-Pro at $0.44 / $0.87, the same volume runs about $220 plus $87, roughly $307 a month. That is not a rounding difference; it is a feature that either ships or does not.
Gemini 3.5 Flash on the same volume lands near $750 input plus $900 output, about $1,650 a month — more than DeepSeek but far below GPT-5.5, and you are buying speed and a major-provider relationship for the gap. The point is not that one model is right for everyone. It is that the spread between these three is now large enough that picking deliberately, rather than defaulting to whatever you used last year, is worth real money.
What the benchmarks do not tell you
Scores like SWE-bench and intelligence-per-dollar are useful for ranking, but they flatten things that matter day to day. A model that is 2% better on a benchmark but twice as slow can feel worse in a live product. A cheaper model that occasionally formats output inconsistently can cost you more in engineering time than it saves in tokens. Before you commit, run your own evaluation on your actual prompts — a few hundred representative requests through each model will tell you more than any leaderboard. The headline numbers point you at the right shortlist; your own data picks the winner.
Frequently asked questions
Is DeepSeek V4-Pro safe to use for a business?
Technically it is reliable and high-performing. The real question is data governance — where requests are processed and whether that fits your compliance needs. Many teams use it for non-sensitive, high-volume tasks and reserve a Western model for anything regulated.
Why did Gemini 3.5 Flash get more expensive than the old Flash?
Google priced the new Flash at $1.50 / $9.00, roughly 3x its predecessor, reflecting its jump toward frontier-level quality. It is part of a 2026 pattern where the budget tier is no longer as cheap as it once was, though efficiency per dollar still improved.
Which is best for coding specifically?
On benchmarks, DeepSeek V4-Pro leads this trio for code at about 80.6% on SWE-bench Verified and 93.5% on LiveCodeBench. Gemini 3.5 Flash is the better pick when you need fast responses, and Claude Sonnet 4.6 is the choice if reliability and ecosystem matter more than raw score.
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
