AI Tools
GPT-5.5 vs Claude Opus 4.8: Which Frontier AI Model Is Worth It in 2026?

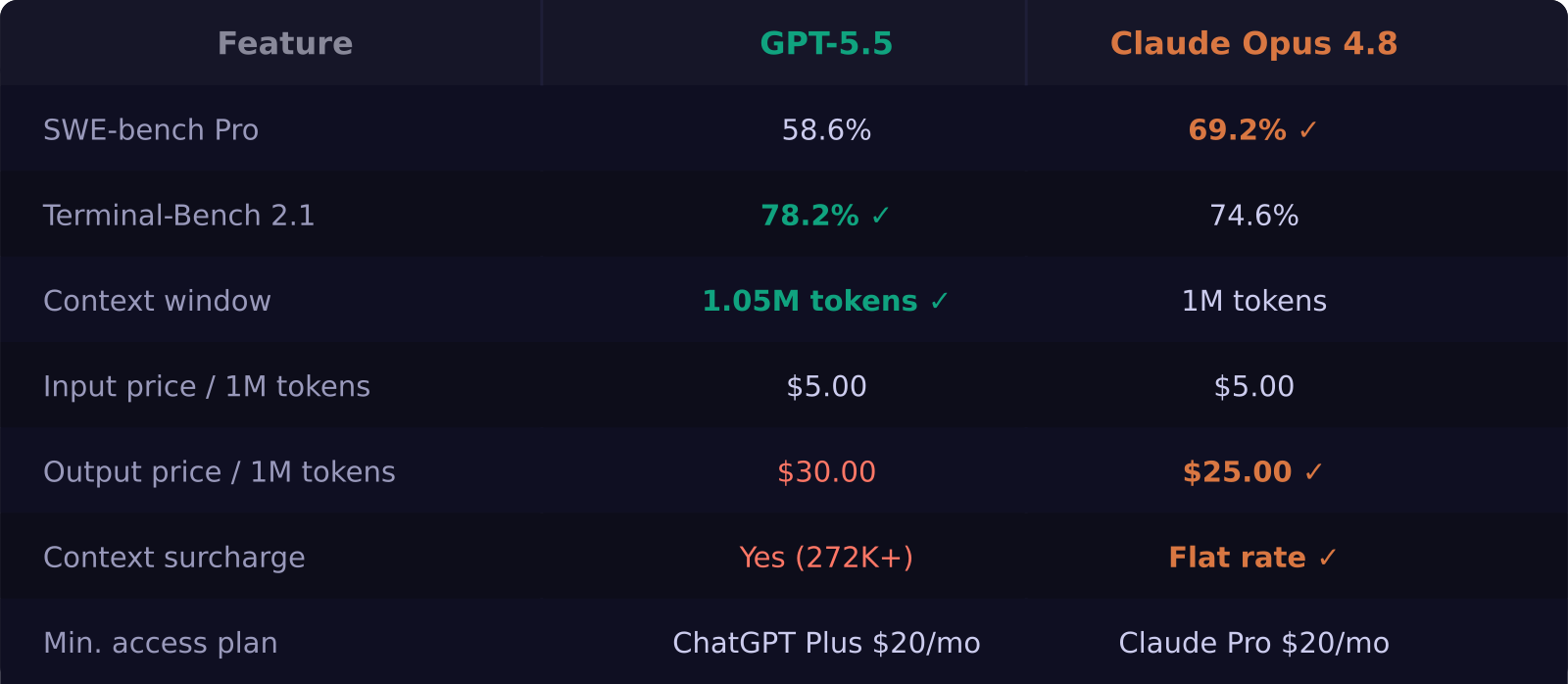
GPT-5.5 and Claude Opus 4.8 are the two most capable frontier AI models you can access right now without a research license. Claude Opus 4.8 wins on coding with a 69.2% SWE-bench Pro score versus GPT-5.5's 58.6%, and it costs 17% less per output token at $25 versus $30 per million. GPT-5.5 leads on terminal-based agentic work and has the deeper OpenAI ecosystem. For most builders and creators in 2026, the choice comes down to what you're actually building — not just who scored higher on a benchmark.
Key takeaways
- Claude Opus 4.8 leads on coding: 69.2% SWE-bench Pro vs GPT-5.5's 58.6%
- GPT-5.5 edges ahead on agentic/terminal tasks: 78.2% Terminal-Bench 2.1 vs 74.6%
- Output pricing: Opus 4.8 at $25/M vs GPT-5.5 at $30/M — same $5/M input
- GPT-5.5 adds a surcharge beyond 272K tokens; Opus 4.8 is flat across its full 1M context
- Both require a paid plan ($20/month Plus or Pro) to access
What are GPT-5.5 and Claude Opus 4.8?
These are the top-tier flagship models from OpenAI and Anthropic respectively — one step above their mid-range workhorses. GPT-5.5 sits above GPT-5 in the OpenAI lineup and is optimized for complex reasoning, terminal-level automation, and multi-step agentic tasks. Claude Opus 4.8 is Anthropic's current flagship, built for long-context coding projects, deep document analysis, and developer workflows.
Neither is available on a free plan. GPT-5.5 requires ChatGPT Plus at minimum ($20/month), while Claude Opus 4.8 requires Claude Pro ($20/month) or API billing. At the API level, both share a $5.00 per million input token price, but diverge on output: GPT-5.5 at $30.00 versus Opus 4.8 at $25.00.
Which is better at coding?
Claude Opus 4.8 is the stronger coding model by a clear margin. On SWE-bench Pro — the most rigorous real-world coding evaluation — Opus 4.8 scores 69.2% versus GPT-5.5's 58.6%. That 10.6 percentage-point gap translates into noticeably fewer errors on complex multi-file refactors and debugging sessions that span long codebases.
From my own experience throwing large React projects at both, Opus 4.8 is more likely to catch the edge-case bug on the first attempt. GPT-5.5 is still excellent and produces readable, well-structured code, but when correctness matters — production-level work, client deliverables — Opus 4.8 is the safer pick.
The context advantage compounds this. Opus 4.8's flat $25/M pricing across its full 1M token window means you can dump an entire codebase into context without a surprise invoice. GPT-5.5 applies a surcharge beyond roughly 272K tokens, which catches developers off guard on large-context tasks.
Which is better for agentic tasks?
GPT-5.5 takes the lead here. On Terminal-Bench 2.1 — which tests models on real shell environments, file system navigation, and multi-step command sequences — GPT-5.5 scores 78.2% versus Opus 4.8's 74.6%. The gap is narrower than on coding benchmarks, but it's consistent across test runs.
This plays out in practice when you're running GPT-5.5 inside tools like Cursor or using the OpenAI Assistants API for autonomous multi-step workflows. The model is faster at recovering from tool call errors, and its function-calling reliability in production environments is slightly ahead. If your use case is automation pipelines, web scraping agents, or long-horizon task execution, GPT-5.5 edges out.
How does pricing compare in practice?
At identical usage volumes, Claude Opus 4.8 is cheaper. On a typical workload of 500K input tokens and 200K output tokens per month, GPT-5.5 costs $8.50 versus Opus 4.8's $7.50. That 12% difference becomes meaningful at scale — at 5M output tokens monthly, you're saving $25,000 per year by choosing Opus 4.8.
The hidden cost is GPT-5.5's context surcharge. Applications that regularly send 300K+ token payloads will see GPT-5.5 bills climb faster than expected. Anthropic's flat pricing model is simpler and more predictable, which matters when building production products where cost forecasting is real.
Which is better for writing and creative work?
GPT-5.5 has a slight edge for premium general writing — strategy documents, investor memos, customer-facing copy. The prose flows more naturally for business contexts and it handles multi-format output (structured JSON + natural language narratives in the same response) better. OpenAI has clearly invested in this model's voice and adaptability.
Claude Opus 4.8 is excellent at long-form technical writing and produces very clean documentation. It's more consistent on tone over long documents. But if the primary job is persuasive or creative writing rather than technical output, GPT-5.5 wins by feel.
Who should use each model?
Claude Opus 4.8 is the right choice if you write code, build software products, or work with large documents and codebases. Its coding accuracy, flat context pricing, and $25/M output rate make it the better tool for developers and technical builders.
GPT-5.5 is the right choice if you need deep agentic automation, you're already embedded in the OpenAI ecosystem (Assistants API, Custom GPTs, OpenAI's tools stack), or your primary work is high-stakes writing where prose quality is the main output.
Both models are available at $20/month through their respective consumer plans. At the API level, run your actual workload through both for a week before committing to infrastructure choices — the pricing difference is real but the qualitative fit for your specific use case matters more.
Frequently asked questions
Is Claude Opus 4.8 or GPT-5.5 better for coding? Claude Opus 4.8 leads clearly with 69.2% on SWE-bench Pro compared to GPT-5.5's 58.6%. For correctness-critical coding work, Opus 4.8 is the stronger model in 2026.
Which model is cheaper, GPT-5.5 or Claude Opus 4.8? Input pricing is identical at $5.00 per million tokens. Claude Opus 4.8 is cheaper on output at $25.00/M versus $30.00/M for GPT-5.5. Opus 4.8 also has no context surcharge, unlike GPT-5.5 which charges extra beyond 272K tokens.
Can I use GPT-5.5 or Claude Opus 4.8 for free? Neither is available on free tiers. Both require a $20/month paid plan — ChatGPT Plus for GPT-5.5 and Claude Pro for Opus 4.8 — or direct API billing.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
