AI Tools
GPT-5.5 vs Claude Opus 4.8: Which AI Frontier Model Actually Wins in 2026?

On May 28, 2026, Claude Opus 4.8 did something no Anthropic model had managed before: it knocked GPT-5.5 off the top of the Artificial Analysis Intelligence Index, scoring 61.4 versus OpenAI's 60.2. That margin is narrow enough to matter only in specific use cases — but those use cases are exactly what most developers care about.
GPT-5.5 launched April 23, 2026, and spent five weeks as the uncontested benchmark leader. Claude Opus 4.8 arrived May 28 and immediately reshuffled the rankings. Now you have two frontier models priced identically on input, separated by meaningful differences in coding, agentic tasks, and output cost. Here is exactly where each model wins.
Key takeaways
- Claude Opus 4.8 leads overall: 61.4 vs 60.2 on the Artificial Analysis Intelligence Index as of May 2026
- Coding goes to Opus 4.8 decisively: 69.2% vs 58.6% on SWE-bench Pro
- GPT-5.5 edges ahead on agentic tasks: 81.5 vs 80.1
- Output pricing favors Opus 4.8: $25/M tokens vs $30/M for GPT-5.5
- Both models carry 1M token context windows
What each model actually improved
GPT-5.5 was OpenAI's biggest reasoning upgrade since GPT-4. The 1M context window became standard — no more chunking codebases or long documents into segments. OpenAI described improvements to what it calls "conceptual clarity": the model tracks system-wide architectures across long sessions better than its predecessors. On SWE-bench Pro, GPT-5.5 scored 58.6% — a solid step forward.
Claude Opus 4.8 came with a different set of priorities. Anthropic added effort controls that let developers dial reasoning depth up or down within the same model, without switching endpoints. Dynamic workflows went production-ready: Opus 4.8 can plan a task, fan out into hundreds of parallel subagents via Claude Code Workflows, and merge results inside a single session. Mid-conversation system messages graduated from beta to GA, which matters for multi-turn applications. The 1M token context window is now on by default rather than opt-in. SWE-bench Verified scored 88.6%.
How do the benchmarks compare?
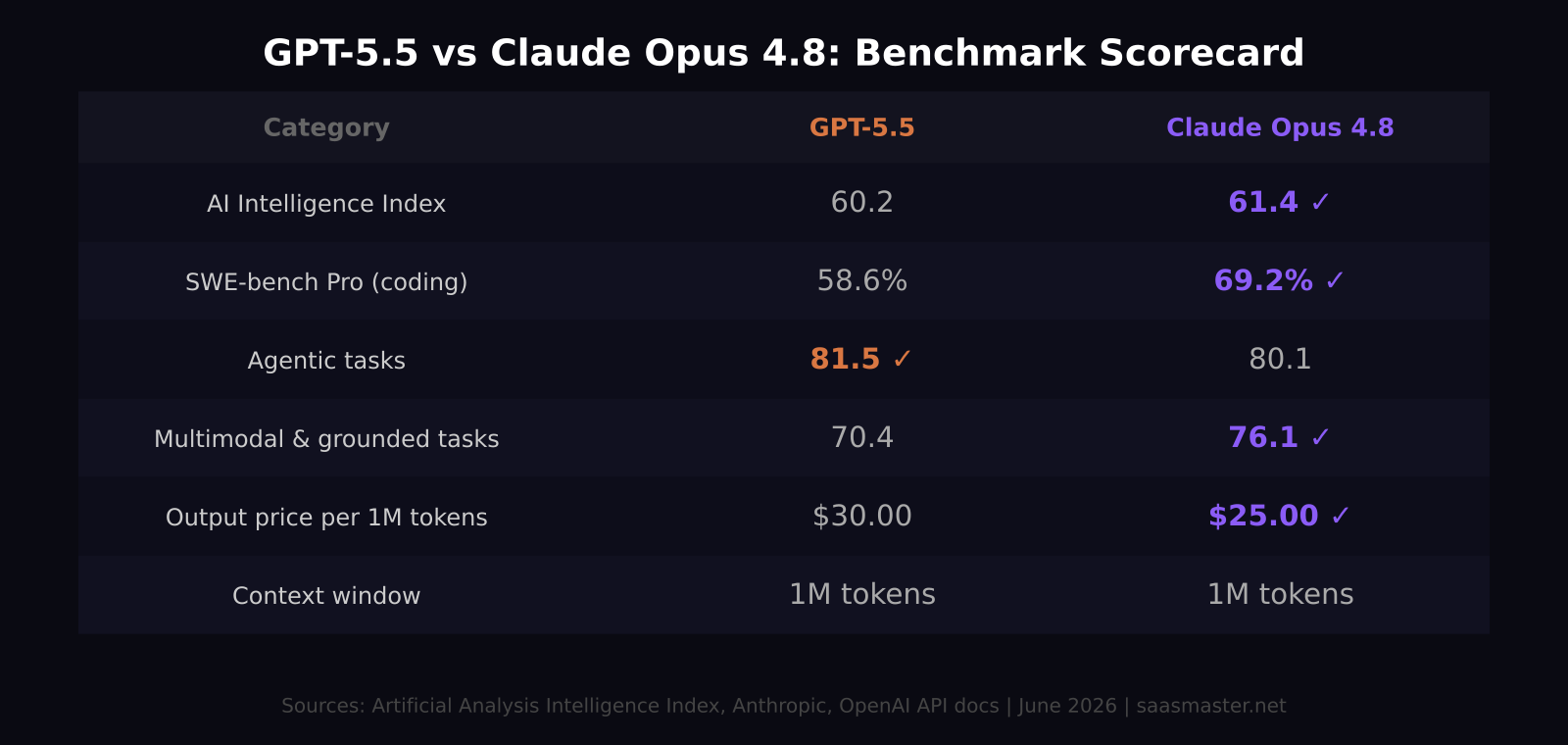
The headline number is the Artificial Analysis Intelligence Index: Opus 4.8 scores 61.4, GPT-5.5 scores 60.2. Narrow, but real. The breakdown by category is where the story gets useful.
Coding is where the gap is widest. On SWE-bench Pro — the harder version of the software engineering benchmark — Opus 4.8 scores 69.2% versus GPT-5.5's 58.6%. That is nearly 11 percentage points. For code generation, debugging, or AI-assisted development, the gap is practically significant.
Agentic performance is where GPT-5.5 holds its ground. On agentic task benchmarks, GPT-5.5 averages 81.5 versus Opus 4.8's 80.1. Both are strong numbers, and the gap is only 1.4 points — but for teams building autonomous agents that plan and execute multi-step workflows, GPT-5.5 maintains a slight edge.
Multimodal and grounded tasks favor Opus 4.8: 76.1 versus 70.4 for GPT-5.5. If your workflow involves images, documents, or data grounding, Opus 4.8 handles it better by a meaningful margin.
Which model is cheaper to run?
Both models start at $5.00 per million input tokens. The difference shows up on output.
GPT-5.5 costs $30.00 per million output tokens at standard tier. The GPT-5.5 Pro tier pushes that to $180.00/M output (with input at $30.00/M) — positioned for maximum-compute inference.
Claude Opus 4.8 costs $25.00 per million output tokens in regular mode. A faster "fast mode" runs $10.00/M input and $50.00/M output. Prompt caching cuts costs by up to 90% on repeated content, and batch processing delivers 50% savings. At high volumes, Opus 4.8 has substantially more cost levers.
At standard rates with a typical 1:3 input-to-output ratio, Opus 4.8 saves $5 per million output tokens compared to GPT-5.5. At the scale most SaaS teams run, that is a real number on a real bill.
Does context window length matter between them?
Both offer 1M token context windows, so this is not a differentiating factor for most developers. Where they differ: Opus 4.8 supports 128k maximum output tokens on the Claude API, Bedrock, and Vertex AI. GPT-5.5's standard output limits are more constrained. If you are generating long documents, code files, or reports in single responses, Opus 4.8 has the edge.
Who should choose which model?
For developers building coding tools, automated code review, or AI-assisted engineering: Claude Opus 4.8. The SWE-bench Pro gap of nearly 11 points is too wide to ignore.
For teams deploying autonomous agents with multi-step planning and real-world execution: GPT-5.5 is competitive. The agentic gap is narrow (1.4 points), so test both on your specific workflows before committing.
For cost-conscious builders at high volume: Opus 4.8. The $5 cheaper output pricing plus flexible caching options make it the more economical default.
For multimodal tasks — document analysis, image understanding, data grounding: Opus 4.8's 5.7-point lead on that category is meaningful enough to act on.
If you are a SaaS product team picking a model for customer-facing features in mid-2026, Opus 4.8 is the stronger all-around choice. GPT-5.5 stays relevant for agentic-heavy architectures, especially if your team has already built workflows on OpenAI's tooling.
My honest take
I have been running both models across content workflows, code generation, and long-document analysis. The benchmark numbers track with real experience. Opus 4.8 is noticeably stronger on coding. The effort controls are genuinely useful — being able to dial reasoning depth without switching endpoints changes how I plan tasks.
GPT-5.5 still feels more fluid in open-ended, multi-turn agentic conversations. Something about how it tracks context and adapts mid-task feels polished. For pure coding output, though, I keep defaulting to Opus 4.8.
The pricing difference also matters more than most teams acknowledge upfront. If you are processing millions of tokens monthly, the $5 per million output gap compounds. Most teams I talk to underestimate this until the first large API bill arrives.
Frequently asked questions
Is Claude Opus 4.8 better than GPT-5.5 overall?
On the Artificial Analysis Intelligence Index as of May 2026, Opus 4.8 leads 61.4 to 60.2. It outperforms GPT-5.5 on coding (69.2% vs 58.6% on SWE-bench Pro) and multimodal tasks. GPT-5.5 leads narrowly on agentic benchmarks (81.5 vs 80.1). The right choice depends on your use case — neither model wins everywhere.
How much does Claude Opus 4.8 cost versus GPT-5.5?
Both start at $5.00 per million input tokens. Opus 4.8 costs $25.00/M for output versus GPT-5.5's $30.00/M. At high volumes, Opus 4.8 offers prompt caching (up to 90% off) and batch processing (50% off). GPT-5.5 Pro tier prices rise to $30.00/M input and $180.00/M output.
When was Claude Opus 4.8 released?
Claude Opus 4.8 was released on May 28, 2026. It immediately took the top spot on the Artificial Analysis Intelligence Index — the first Anthropic model to lead the overall rankings against a contemporary GPT model.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master