AI Tools
Kimi K2.7 Code vs DeepSeek V4 vs Claude Sonnet 4.6: Which Is the Best Coding AI Right Now?
Three days ago Moonshot AI dropped Kimi K2.7 Code on Hugging Face without fanfare — no blog post, no press release, just a model card and weights. That is how Chinese AI labs ship in 2026: fast and quiet. The model is a 1-trillion-parameter coding specialist built for agentic workflows, and it lands directly in the territory contested by DeepSeek V4 and Claude Sonnet 4.6. If you are picking a coding AI right now, here is what each one actually does and when to reach for it.
Key takeaways
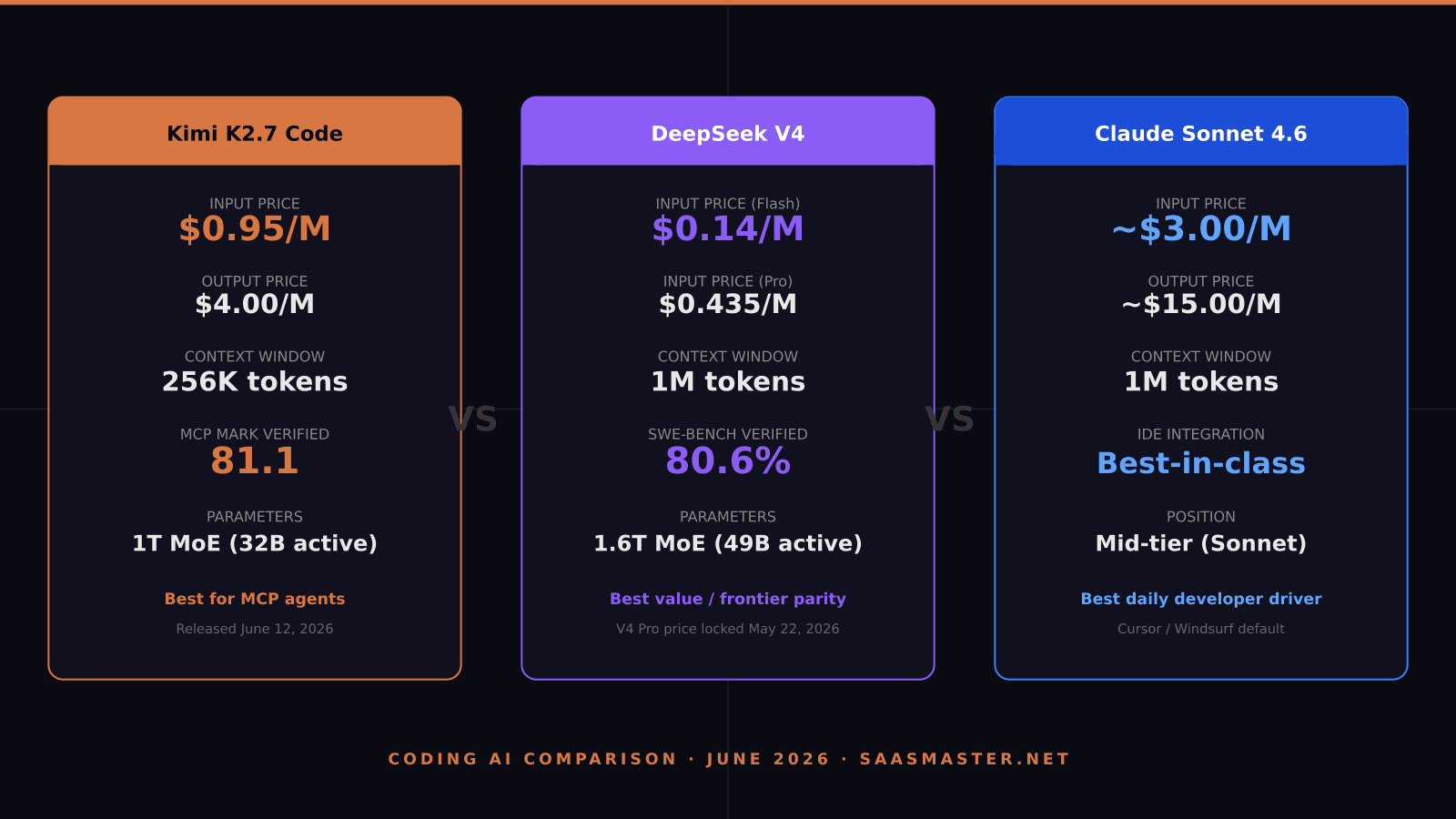
- Kimi K2.7 Code scored 81.1 on MCP Mark Verified — the strongest tool-invocation result published for any model in agentic environments
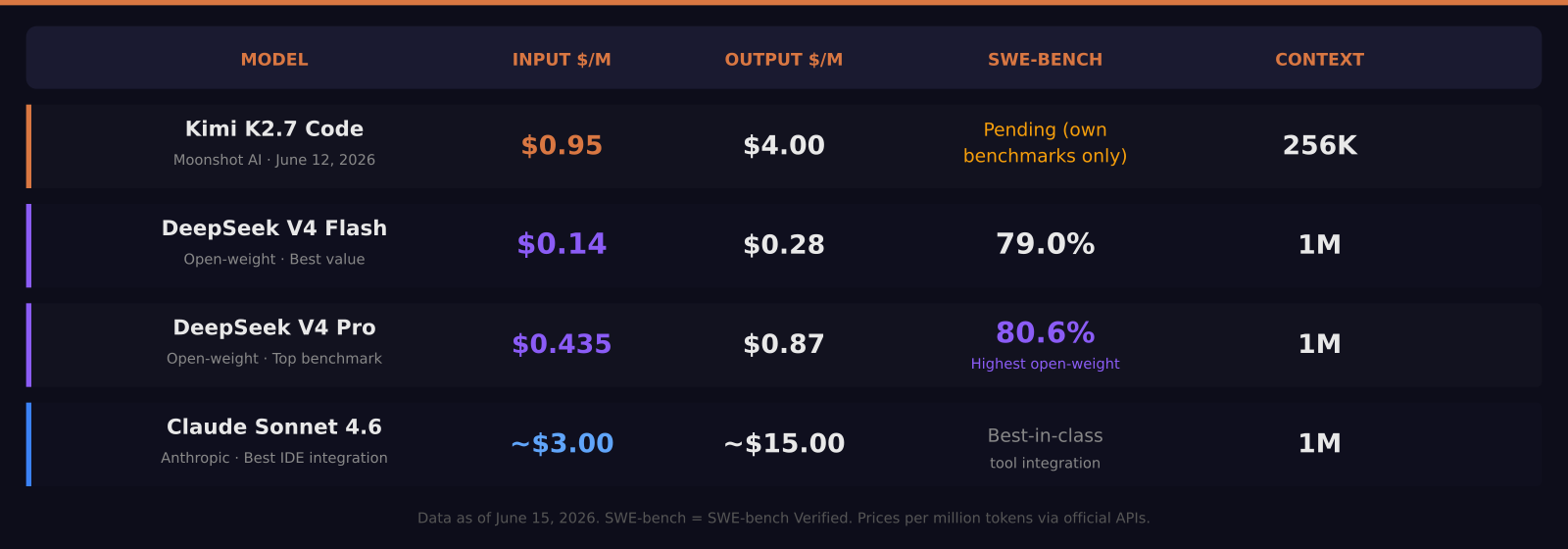
- DeepSeek V4 Flash costs $0.14 per million input tokens and scores 79.0% on SWE-bench Verified — the best value-to-performance ratio in June 2026
- DeepSeek V4 Pro reaches 80.6% SWE-bench at $0.435/M input, matching frontier models at roughly 34 times lower cost
- Claude Sonnet 4.6 is the most mature for daily IDE-integrated development — Cursor, Windsurf, and Claude Code all optimize around it
- All three models support long-context work, but context window sizes differ: 256K for Kimi, 1M for both DeepSeek V4 and Sonnet 4.6
What is Kimi K2.7 Code and why does it matter?
Moonshot AI released Kimi K2.7 Code on June 12, 2026. The architecture is a Mixture-of-Experts design with 1 trillion total parameters and 32 billion active per token — the same efficient structure used in K2.6, now with a modified routing system and 384 experts instead of the previous count. Context window is 256K tokens. Thinking mode is mandatory: every query goes through a reasoning pass before generating output.
The headline improvement over K2.6 is token efficiency. K2.7 Code uses roughly 30 percent fewer thinking tokens to reach the same or better output quality, which matters for cost in agent workflows where the model runs dozens of reasoning cycles per task. Moonshot's own benchmarks show plus 21.8 percent on Kimi Code Bench v2, plus 11.0 percent on Program Bench, and plus 31.5 percent on MLS Bench Lite.
The number worth paying closest attention to is 81.1 on MCP Mark Verified. This benchmark tests whether a model reliably invokes tools through the Model Context Protocol — reading files, writing code, running terminal commands, calling APIs — the full loop that agentic coding tools require. For anyone building with MCP-based agents, that score is more predictive of real performance than SWE-bench alone.
K2.7 Code is released under a Modified MIT license, meaning commercial use is allowed with conditions. API pricing is $0.95 per million input tokens and $4.00 per million output tokens, with cached input at $0.19 per million.
The important caveat: Moonshot had not submitted K2.7 to independent benchmark suites like SWE-bench Verified or GPQA as of June 15, 2026. Every number above comes from the official model card. That is a meaningful gap when comparing to DeepSeek V4, which has third-party verified SWE-bench scores.
What changed with DeepSeek V4 in May 2026?
DeepSeek V4 became the open-weights coding benchmark leader in May 2026. On May 22 Moonshot confirmed the 75 percent promotional discount on V4 Pro is now the permanent standing price: $0.435 per million input tokens and $0.87 per million output tokens. That price change matters because it put DeepSeek V4 Pro in competition with Sonnet-tier pricing while matching Opus-tier performance on coding tasks.
The model comes in two variants. V4 Flash runs at $0.14 per million input and $0.28 per million output. It scores 79.0 percent on SWE-bench Verified — vendor-reported but consistent with community testing — and 93.5 on LiveCodeBench, which tests performance on recent competitive programming problems. V4 Pro steps to 80.6 percent on SWE-bench, the highest open-weight entry published, tied with Gemini 3.1 Pro.
Architecture is 1.6 trillion total parameters with 49 billion active per token, and both variants support 1 million token context. That full-repo context is the practical edge over Kimi K2.7 Code for large codebase analysis: you can load an entire monorepo into a single V4 Pro query in a way you cannot with K2.7's 256K limit.
How does Claude Sonnet 4.6 fit into this picture?
Claude Sonnet 4.6 is Anthropic's mid-tier model, positioned between Haiku 4.5 for speed and cost and Opus 4.8 for frontier tasks. It ships with a 1 million token context window and 1 million token extended context support. Pricing sits at approximately $3 per million input tokens and $15 per million output tokens — more expensive than either DeepSeek V4 variant, significantly so on output.
What Sonnet 4.6 has that neither DeepSeek V4 nor Kimi K2.7 match is integration depth. Claude Code, Cursor, and Windsurf all run their default agentic coding prompts against Sonnet 4.6. That means the model has been optimized through real developer usage patterns, not just benchmark-oriented training. In practice, you see fewer hallucinated APIs, more consistent tool call formatting, and better behavior on ambiguous coding instructions.
For a developer running 50 to 100 coding queries per day across an IDE, the cost differential is real but not extreme. Ten thousand output tokens per day — a moderate session — costs about $0.15 with V4 Flash, $0.50 with V4 Pro, and roughly $1.50 with Sonnet 4.6. The practical question is whether the integration quality gap closes that gap.
Which is cheapest for one million output tokens?
Here is the cost per million output tokens across all four options:
- DeepSeek V4 Flash: $0.28
- DeepSeek V4 Pro: $0.87
- Kimi K2.7 Code: $4.00
- Claude Sonnet 4.6: approximately $15.00
If output cost is driving your decision and your use case is straightforward code generation, completion, or review, V4 Flash wins by a factor of 50 over Sonnet 4.6. That spread widens further if you compare against Opus 4.8.
Kimi K2.7 Code sits between the two DeepSeek variants and Sonnet in price. The premium over V4 Pro is 4.6 times on output. That premium makes sense only in specific scenarios: MCP-heavy agent pipelines where the 81.1 MCP Mark score translates to real reliability gains, or workflows where Kimi's Modified MIT license lets you self-host or fine-tune in ways DeepSeek's license does not allow.
When should you actually use each model?
For agentic coding with MCP: start with Kimi K2.7 Code. The MCP Mark score is the highest published number in that environment. The 256K context is sufficient for most single-feature or single-service workflows. If your agent is running file reads, test executions, and code edits in a loop, the efficiency gains from fewer thinking tokens compound over hundreds of iterations.
For production at scale with cost as the primary constraint: route to DeepSeek V4 Flash for routine tasks and V4 Pro for complex ones. Published routing experiments suggest routing 70 percent of queries to Flash and 25 percent to Pro achieves aggregate performance indistinguishable from all-Pro routing at roughly 40 percent of the cost. The 1M context window means you never hit a ceiling on codebase size.
For daily IDE-integrated development: Claude Sonnet 4.6 remains the most reliable choice. The integration quality in Cursor, Windsurf, and Claude Code is the result of months of production optimization. Raw benchmark scores do not capture how often a model formats a function call correctly on the first attempt, or how well it handles a half-written comment as the start of a task.
Frequently asked questions
Is Kimi K2.7 Code open source? Kimi K2.7 Code is released under a Modified MIT license, which permits commercial use with certain conditions listed in the model card. Weights are available on Hugging Face. You can self-host or fine-tune, making it useful for teams that need full control over their coding model deployment.
How does Kimi K2.7 compare to DeepSeek V4 Pro on SWE-bench? As of June 15, 2026, Kimi K2.7 Code has not published standalone SWE-bench Verified results. Only Moonshot's internal benchmark scores are available. DeepSeek V4 Pro has a third-party-verified score of 80.6 percent on SWE-bench Verified, the highest open-weight result published.
Which coding model has the largest context window in June 2026? DeepSeek V4 (both Flash and Pro) and Claude Sonnet 4.6 all support 1 million token context windows. Kimi K2.7 Code supports 256K tokens — smaller but still sufficient for most single-service agentic coding tasks. For whole-repository analysis across large codebases, the 1M context models have a practical advantage.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
