AI Tools
GPT-5.5 vs Claude Opus 4.8 vs Gemini 3.5 Flash: Which Frontier Model Wins in 2026?

If you are choosing between GPT-5.5, Claude Opus 4.8, and Gemini 3.5 Flash in June 2026, here is the honest answer: Claude Opus 4.8 leads on intelligence benchmarks and coding, GPT-5.5 has the widest ecosystem and strong agentic reliability in real-world tools, and Gemini 3.5 Flash offers the strongest performance-per-dollar by a significant margin. The right model depends on your workload.
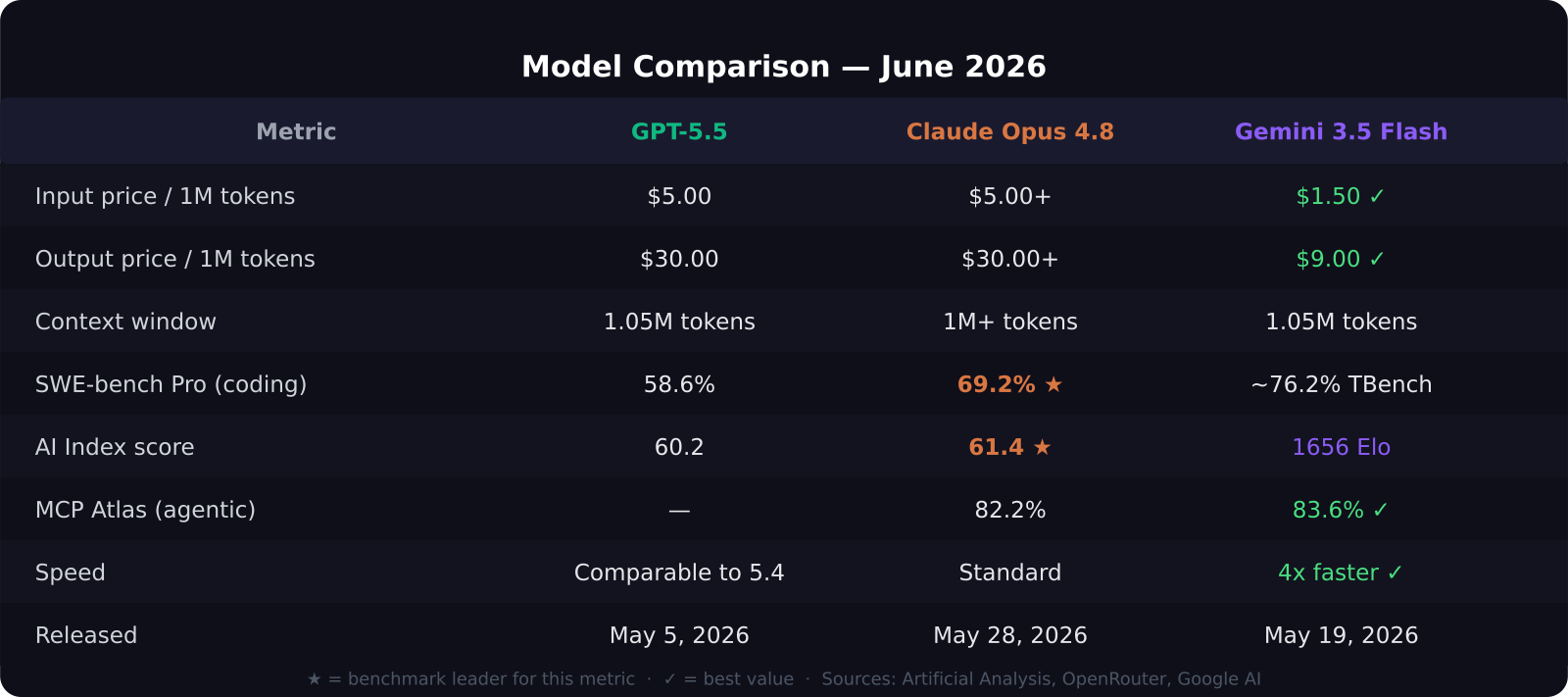
Key takeaways: - Claude Opus 4.8 scores 61.4 on the Artificial Analysis Intelligence Index vs 60.2 for GPT-5.5 — the gap is real but narrow - On SWE-bench Pro (coding), Opus 4.8 scores 69.2% vs GPT-5.5 at 58.6% - Gemini 3.5 Flash costs $1.50 input / $9.00 output per 1M tokens — roughly 3x cheaper than GPT-5.5 on output - All three models now support over 1 million tokens of context - For high-volume API usage, Gemini 3.5 Flash is the cost-efficient default until workload demands otherwise
What happened since early 2026
This comparison would have looked very different in January. GPT-5.5 launched on May 5, 2026, as OpenAI's first fully retrained base model since GPT-5.4 — claiming 52.5% fewer hallucinations and a Terminal-Bench 2.0 score of 82.7%. Claude Opus 4.8 responded by dethroning GPT-5.5 on the Artificial Analysis Intelligence Index on May 28, scoring 61.4 against 60.2. Then Google dropped Gemini 3.5 Flash on May 19, positioning it not as a lightweight model but as a full-featured multimodal frontier model that runs 4x faster than comparable models at a fraction of the cost.
Three major model releases within a four-week window. That is the pace of this market right now.
Pricing at a glance
At the API level, the cost differences matter once you are running any volume. GPT-5.5 charges $5.00 per million input tokens and $30.00 per million output tokens. Claude Opus 4.8 is priced comparably at the upper end of Anthropic's pricing ladder. Gemini 3.5 Flash comes in at $1.50 input and $9.00 output per million tokens — roughly 70% cheaper on output than GPT-5.5.
For SaaS teams building AI features at scale, that pricing gap is not trivial. A pipeline generating 10 million output tokens per month costs $90 with Gemini 3.5 Flash versus $300 with GPT-5.5 — a $210 monthly difference that compounds quickly.
Benchmark breakdown
Coding and software engineering
This is where Claude Opus 4.8 pulls the clearest lead. On SWE-bench Pro, Anthropic's model scores 69.2% versus 58.6% for GPT-5.5. The overall coding average follows suit: 76.4 for Opus 4.8 versus 58.6 for GPT-5.5. If you are building coding agents, reviewing pull requests automatically, or generating complex backend code from specs, Opus 4.8 is the benchmark leader in June 2026.
Gemini 3.5 Flash holds its own with 76.2% on Terminal-Bench 2.1, a newer and harder benchmark than the one used to evaluate GPT-5.5. Google deliberately positioned Flash as a coding-optimized model, and the numbers reflect that.
Agentic tasks
GPT-5.5 averages 81.5 on agentic benchmark suites versus 80.1 for Claude Opus 4.8. But the picture is more complicated. On OSWorld-Verified — a real-world computer-use benchmark — Opus 4.8 scores 83.4% versus 78.7% for GPT-5.5. On MCP-Atlas, Opus 4.8 scores 82.2% and Gemini 3.5 Flash scores 83.6% — actually beating both on that benchmark.
The pattern: GPT-5.5 performs better on traditional agentic task suites. Both Opus 4.8 and Gemini 3.5 Flash lead on newer tool-use and computer-control benchmarks. If your agent stack uses MCP tooling, both Anthropic and Google models have the edge.
Knowledge and reasoning
GPT-5.5's hallucination reduction — 52.5% fewer than GPT-5.4 — matters for factual retrieval tasks. Opus 4.8 leads overall with a composite intelligence score of 93 versus 89 for GPT-5.5. Gemini 3.5 Flash scores 1656 Elo on GDPval-AA and posts 84.2% on CharXiv Reasoning, making it competitive for analytical workloads at its price point.
Speed and context window
All three models now support at least 1 million tokens of context. GPT-5.5 has a 1,050,000 token context window with up to 128,000 output tokens. Gemini 3.5 Flash matches with 1,048,576 tokens in and 65,536 out.
On throughput, Gemini 3.5 Flash was purpose-built for speed — Google claims it runs 4x faster than comparable frontier models. This matters for latency-sensitive applications like real-time copilots or live document analysis.
Which model fits which workload
If you are building a coding assistant, code review pipeline, or software engineering agent, Claude Opus 4.8 is the benchmark leader. The SWE-bench gap against GPT-5.5 is large enough to meaningfully impact output quality on complex tasks.
If you are building a general-purpose assistant with deep integration into existing OpenAI tooling, or need the widest third-party app compatibility, GPT-5.5 has the ecosystem depth. The API is more mature, the hallucination improvements are real, and most enterprise integrations ship OpenAI support first.
If you are running high-volume API calls — document analysis, summarization, classification, RAG pipelines at scale — Gemini 3.5 Flash is the answer. The price gap is too large to ignore, and the benchmarks show it does not sacrifice much to get there.
My take after using all three
I have been running all three models through content and document pipelines over the past few weeks. Gemini 3.5 Flash surprised me most. It ran faster in practice, matched quality on most standard tasks, and the pricing difference showed up immediately in my token logs.
Claude Opus 4.8 is noticeably better at structured reasoning and long-document analysis — it handles complex prompts with multiple constraints more reliably than either competitor. For anything I am building that requires a model to follow nuanced instructions precisely, Opus 4.8 is my first choice.
GPT-5.5 has the best developer experience. The hallucination improvements are real, factual retrieval feels tighter, and the tooling ecosystem around it is still the most mature. But at $30 per million output tokens, you feel the cost at any meaningful volume.
Frequently asked questions
Which model is the most accurate in 2026? Claude Opus 4.8 leads on the Artificial Analysis Intelligence Index at 61.4 versus 60.2 for GPT-5.5, and scores highest on SWE-bench Pro at 69.2%. For raw coding and reasoning accuracy, Opus 4.8 is the benchmark leader in June 2026.
Is Gemini 3.5 Flash a full frontier model or a lightweight model? Gemini 3.5 Flash is a full-featured frontier model, not a lite version. It supports 1M context, multimodal input including images, video, and audio, and was released May 19, 2026. Its lower price reflects architectural efficiency, not capability cutbacks.
Can I mix models in the same pipeline? Yes. On the API level, orchestration tools like LangChain, LlamaIndex, and LiteLLM support routing between models per task type. Apple's Foundation Models framework also supports Claude, Gemini, and Apple models through a single Swift API as of WWDC 2026.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master