AI & SaaS
MiniMax M3 vs DeepSeek V4-Pro: The Open-Weight Showdown on Price and Coding

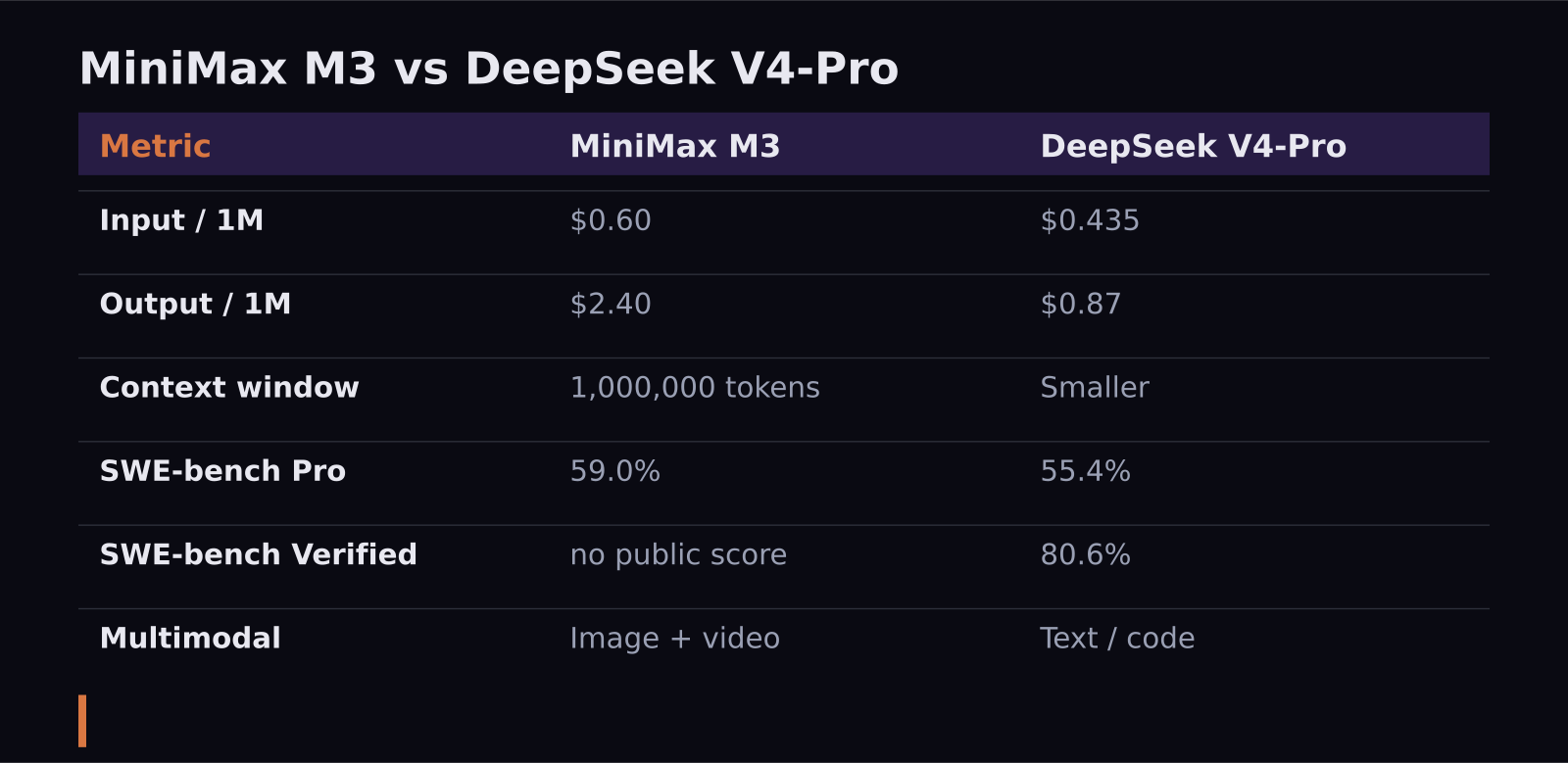
If you want the short version: MiniMax M3 wins on context and coding breadth, while DeepSeek V4-Pro wins on raw price and proven benchmark depth. Both are Chinese open-weight models that deliver near-frontier quality for a fraction of what OpenAI or Anthropic charge — M3 lists at $0.60 per million input tokens and $2.40 output, and DeepSeek V4-Pro undercuts it at $0.435 input and $0.87 output. Which one is right for you comes down to whether you value a million-token context window or the lowest possible bill.
I track these models because they decide what the SaaS teams I work with can actually afford to ship. This matchup is the most interesting in the budget tier right now, so here is the head-to-head with real token prices and benchmark numbers.
Key takeaways
- MiniMax M3 costs $0.60 in / $2.40 out per million tokens; DeepSeek V4-Pro is cheaper at $0.435 in / $0.87 out.
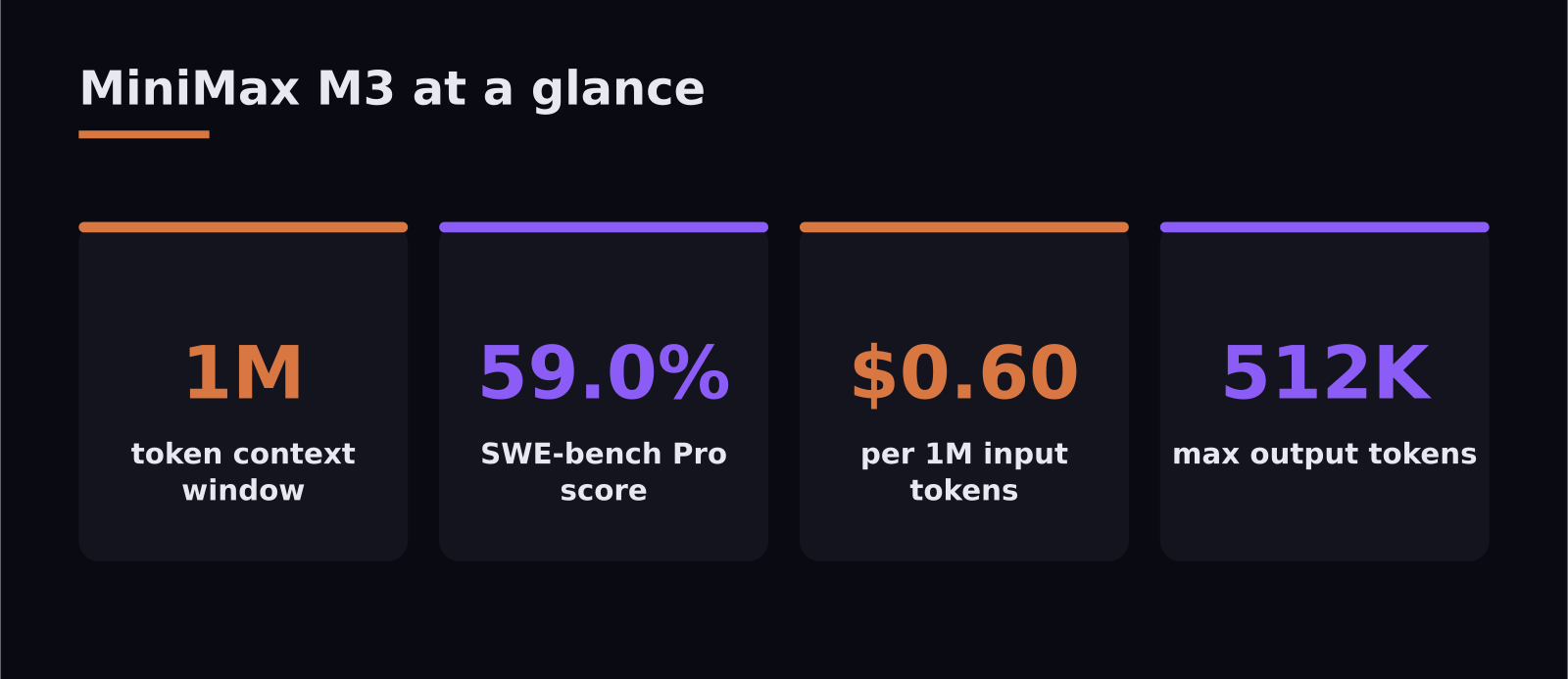
- M3 ships a 1,048,576-token (1M) context window with up to 512K output and native image/video input — DeepSeek does not match that context.
- On SWE-bench Pro, M3 scores 59.0%, edging DeepSeek V4-Pro Max's 55.4% and even GPT-5.5's 58.6%.
- On the stricter SWE-bench Verified, DeepSeek V4-Pro leads at 80.6% and has published scores on more benchmarks overall.
- Both are open-weight, so you can self-host either — the choice is context and multimodality (M3) versus lowest cost and benchmark breadth (DeepSeek).
How much does each cost per token?
This is where both models embarrass the frontier labs. MiniMax M3 lists at $0.60 per million input tokens and $2.40 per million output tokens for prompts up to 512K tokens. At launch in June 2026 it ran a seven-day promo of $0.30 / $1.20, and cache reads are just $0.12 per million with cache writes free. One catch worth knowing: if a single request crosses 512K tokens, the whole call is billed at double the rate, so the long-context superpower has a price.
DeepSeek V4-Pro is cheaper still at roughly $0.435 per million input tokens and $0.87 per million output, after DeepSeek made its 75% discount permanent in May 2026. Its cache-hit price is among the lowest anywhere. For pure cost-per-token on everyday-length prompts, DeepSeek is the cheaper of the two — notably on output, where it is under half M3's rate.
Which one writes better code?
The benchmark picture is genuinely close, and it depends on which test you trust. On SWE-bench Pro — a harder, real-world variant — MiniMax M3 posts 59.0%, edging out DeepSeek V4-Pro Max at 55.4%, and impressively beating GPT-5.5 (58.6%) and Kimi K2.6 (58.6%) too. On that measure M3 trails only Claude's Opus 4.8 and 4.7.
But on SWE-bench Verified, the stricter and more widely cited variant, DeepSeek V4-Pro leads at 80.6%, putting it neck-and-neck with Kimi K2.6 at 80.2%. DeepSeek also has published results across more benchmarks — GPQA, LiveCodeBench, Codeforces and others — where M3 simply has no public score yet. Under Terminal-Bench, DeepSeek edges ahead again at 67.9% execution accuracy versus M3's 66.0%.
The honest read: M3 wins where the two overlap on the newest coding benchmark, but DeepSeek has the deeper, more complete track record. If you need a model with a long, verifiable history of strong scores, DeepSeek has more to show. If you care about the latest real-world coding benchmark, M3 has the edge.
Where M3 pulls clearly ahead
Context and multimodality. M3 carries a 1,048,576-token context window — a full million tokens — with output up to 512K, and it natively accepts image and video input. That combination matters enormously for certain jobs: feeding an entire codebase, a long legal contract, or hours of transcript into a single prompt without chunking, or building tools that reason over screenshots and clips. DeepSeek V4-Pro is a strong text-and-reasoning model, but it does not match that million-token window or native video input. M3 was positioned at launch as the first open-weight model to combine frontier coding, 1M context, and native video/image input in one system, and that is its real differentiator.
So which should you choose?
Pick DeepSeek V4-Pro if your priority is the lowest possible cost on normal-length prompts, you want a model with proven scores across many benchmarks, and your work is mostly text and code. The output pricing alone makes it the cheaper choice at scale.
Pick MiniMax M3 if you need the million-token context window, you work with images or video, or your tasks involve very long documents that you would otherwise have to split up. You pay a bit more per token, but for the right workload the context window saves you far more engineering effort than the price difference costs.
Because both are open-weight, the most thorough teams simply test both on their own prompts before committing — and since both are this cheap, running a real evaluation costs almost nothing.
A real-cost example at scale
Token prices feel abstract until you run them against real volume, so picture a product that processes 300 million input and 60 million output tokens a month — a busy summarization or coding feature. On MiniMax M3 at $0.60 / $2.40, that is about $180 input plus $144 output, roughly $324 a month. On DeepSeek V4-Pro at $0.435 / $0.87, the same volume runs about $130 input plus $52 output, around $182 a month. DeepSeek comes out nearly 45% cheaper on this profile, almost entirely because of its lower output price.
But flip the workload. If your requests routinely run hundreds of thousands of tokens long — whole codebases, long transcripts, big documents — M3's 1M context lets you do in one call what would take DeepSeek several chunked calls plus the engineering to stitch them together. In that scenario M3's slightly higher token price is dwarfed by the time and complexity it removes. The lesson: the cheaper model on paper is not always the cheaper model in practice. Match the model to the shape of your prompts.
The bigger picture for open-weight AI
Step back and the real story is not which of these two wins — it is that two Chinese open-weight models are trading blows with proprietary flagships while costing a fraction as much. A year ago, "open-weight" usually meant "good enough for hobby projects." In 2026 it means a model you can self-host, audit, and run at frontier-adjacent quality. For founders, that changes the build-versus-buy math: you are no longer choosing between an expensive API and a weak free model. You can have strong performance and own your stack. Whichever of these two you pick, the category itself is the thing worth paying attention to.
Frequently asked questions
Is MiniMax M3 or DeepSeek V4-Pro cheaper?
DeepSeek V4-Pro is cheaper per token at about $0.435 input and $0.87 output per million, versus M3's $0.60 and $2.40. The gap is largest on output. M3's advantage is its 1M-token context, not its price.
Does MiniMax M3 really beat GPT-5.5 at coding?
On the SWE-bench Pro benchmark, yes — M3 scores 59.0% to GPT-5.5's 58.6%, at a small fraction of the cost. On other benchmarks the frontier models still lead, so it depends on the specific test and task.
Can I self-host MiniMax M3 and DeepSeek V4-Pro?
Both are open-weight models, so you can run either on your own infrastructure rather than only through an API. That gives you control over data and, at high volume, potentially lower cost than paying per token.
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
