AI Tools
MiniMax M3 vs GPT-5.5 vs Claude Opus 4.8: Can an Open-Weight Model Beat the Giants?

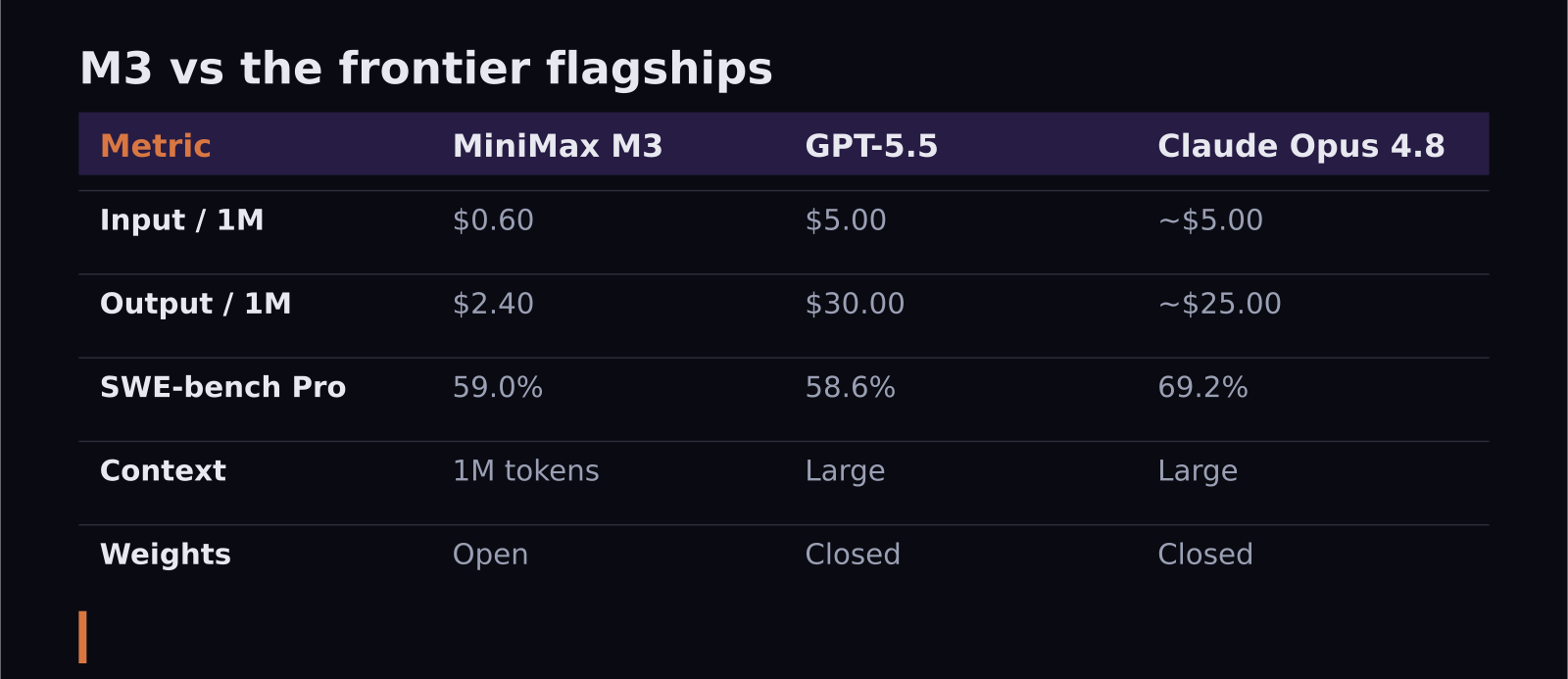
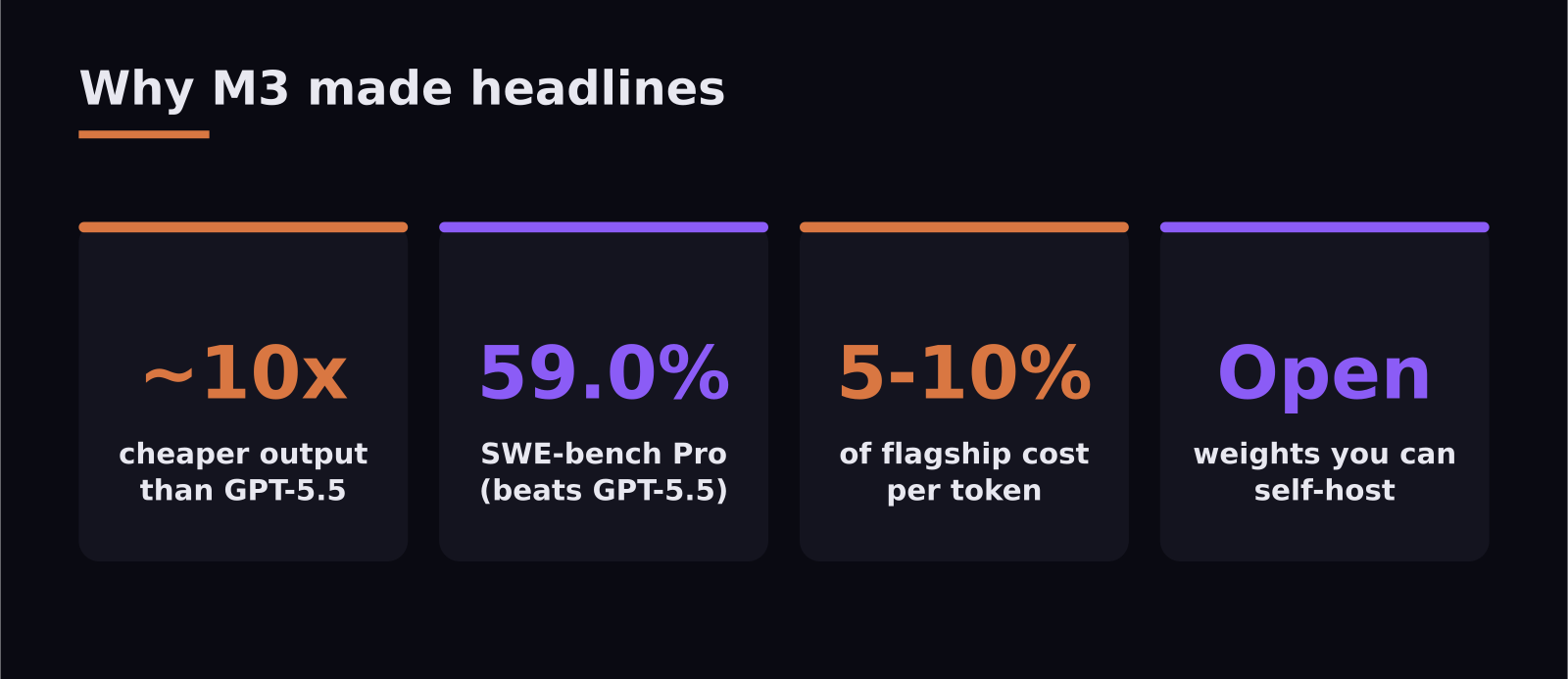
Here is the headline that has everyone's attention: MiniMax M3, an open-weight model, matches or beats GPT-5.5 and Gemini 3.1 Pro on key coding benchmarks for roughly 5 to 10 percent of the cost. At $0.60 per million input tokens and $2.40 output, M3 undercuts GPT-5.5 ($5.00 / $30.00) and Claude Opus 4.8 (around $5.00 / $25.00) by an order of magnitude. The question is no longer whether open-weight models can compete with the giants — it is what you give up by choosing one. Let's break it down with real numbers.
I review these tools constantly, and this is the comparison founders keep asking me about, because the price gap is large enough to change what you can afford to build. So here is M3 against the two leading proprietary flagships on price, benchmarks, and the things benchmarks don't capture.
Key takeaways
- MiniMax M3 costs about 5-10% of GPT-5.5 and Claude Opus 4.8 per token, while matching GPT-5.5 on the SWE-bench Pro coding benchmark.
- Token prices: M3 $0.60 / $2.40, GPT-5.5 $5.00 / $30.00, Claude Opus 4.8 around $5.00 / $25.00 per million.
- On SWE-bench Pro, M3 scores 59.0%, just ahead of GPT-5.5's 58.6% — but Claude Opus 4.8 still leads the field at 69.2%.
- M3 is open-weight with a 1M-token context and native image/video input; the proprietary models offer polish, reliability, and ecosystem instead.
- For high-volume, cost-sensitive work M3 is compelling; for the hardest tasks and enterprise trust, the flagships still justify their premium.
What does each model cost per token?
The spread is dramatic. MiniMax M3 lists at $0.60 per million input tokens and $2.40 per million output, with a launch promo that briefly halved that and cache reads at just $0.12 per million. GPT-5.5 sits at $5.00 input and $30.00 output. Claude Opus 4.8 is in the same premium tier, around $5.00 input and $25.00 output per million, consistent with Anthropic's Opus line.
Put plainly: on output tokens, GPT-5.5 costs roughly 12.5 times more than M3, and Opus around 10 times more. For a product generating large volumes of text or code, that is not a tweak to your margins — it is the difference between a feature being economically viable and being shelved. This is exactly why a model that performs "well enough" at a tenth of the price is such a big deal.
Can an open-weight model really keep up on benchmarks?
On coding, surprisingly, yes. MiniMax M3 scores 59.0% on SWE-bench Pro — a hard, real-world variant — which actually edges past GPT-5.5 at 58.6% and ties Kimi K2.6. That is the result that produced headlines about M3 eclipsing GPT-5.5 and Gemini 3.1 Pro at a fraction of the cost. For a free-to-self-host open-weight model to beat a frontier flagship on any serious coding benchmark is a real milestone.
The important caveat is Claude Opus 4.8. It still leads SWE-bench Pro at 69.2% and SWE-bench Verified at 88.6%, a clear margin above M3 on the toughest tests. So the picture is not "open-weight has caught the giants" so much as "open-weight has caught the middle of the pack." M3 is competitive with GPT-5.5-class performance; the very top of the proprietary field is still ahead, and for the hardest, highest-stakes work that gap matters.
What you actually give up by going open-weight
Benchmarks don't tell the whole story, and this is where the flagships earn their premium. Proprietary models like GPT-5.5 and Claude Opus 4.8 come with mature tooling, strong safety tuning, predictable behavior under messy real-world inputs, broad ecosystem support, and the comfort of a major Western provider for compliance and data-governance reasons. M3 is a Chinese open-weight model, which is a feature if you want to self-host and own your stack, and a consideration if your industry has rules about where data is processed.
There is also consistency. Frontier models tend to behave more predictably across a wide range of edge cases, which is why teams shipping mission-critical features often pay up for them. A model that wins a benchmark by a hair but occasionally formats output inconsistently can cost more in engineering time than it saves in tokens.
So who should use which?
Reach for MiniMax M3 when you run high volumes of cost-sensitive work — summarization, classification, first-pass code, content generation — where its price advantage compounds, or when you need its 1M-token context and multimodal input, or when self-hosting and data ownership matter to you.
Reach for GPT-5.5 or Claude Opus 4.8 when you are tackling the hardest reasoning and coding tasks, when you need maximum reliability for a customer-facing feature, or when enterprise trust, compliance, and ecosystem fit are non-negotiable. The smartest teams route: send the easy 80% of requests to a cheap model like M3 and reserve a flagship for the hard 20%. With prices this far apart, that routing strategy is close to free money.
What this price gap means for your product budget
Let's make the routing idea concrete. Say your app makes 200 million output tokens a month. On GPT-5.5 at $30 per million, that is $6,000. On M3 at $2.40, the same volume is $480. If even 70% of those requests are routine enough for M3 to handle well, you route them to M3 and keep the flagship for the remaining 30% — and your bill drops from $6,000 to somewhere near $2,000 without users noticing a quality change. That recovered budget is runway, or a new hire, or the margin that makes a feature sustainable. The reason this works now and didn't a year ago is that the cheap option finally performs well enough on real tasks that customers can't tell which model answered.
Don't trust one benchmark — test on your own work
The single most useful thing you can do before committing is run your own evaluation. Public benchmarks like SWE-bench are useful for building a shortlist, but they flatten the things that matter day to day: how a model handles your specific prompt style, your formatting requirements, your edge cases. Take a few hundred representative requests from your actual product, run them through M3 and through your current flagship, and compare the outputs side by side. Because M3 costs so little, that test is nearly free to run, and it will tell you more than any leaderboard about whether the cheaper model is good enough for your use case. The headline numbers point you at the right contenders; your own data picks the winner.
Frequently asked questions
Is MiniMax M3 really cheaper than GPT-5.5 and Claude Opus 4.8?
Yes, dramatically. M3 is about $0.60 / $2.40 per million tokens versus roughly $5.00 / $30.00 for GPT-5.5 and $5.00 / $25.00 for Claude Opus 4.8 — on output, the flagships cost roughly 10-12x more.
Does MiniMax M3 beat GPT-5.5 and Claude Opus 4.8?
On the SWE-bench Pro benchmark M3 (59.0%) edges GPT-5.5 (58.6%), but Claude Opus 4.8 still leads clearly at 69.2%. M3 competes with GPT-5.5-class performance; the top of the proprietary field remains ahead.
When is it worth paying for a proprietary model instead?
When you need maximum reliability for customer-facing features, the hardest reasoning tasks, or when compliance, data governance, and enterprise support matter. For high-volume, lower-stakes work, M3's price advantage usually wins.
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
