AI Tools
Qwen3.7-Max Review: Alibaba's 1M-Context Model Beats Claude on Reasoning — at Half the Price

Here is a number that should make you pause mid-workflow: Qwen3.7-Max, released May 20, 2026, scores 92.4 on GPQA Diamond — the hardest reasoning benchmark currently in widespread use. Claude Opus 4.8 scores 91.3. On Terminal-Bench 2.0, which measures real agentic coding performance, Qwen3.7-Max scores 69.7% to Claude's 65.4%. The price difference between these two models is roughly 50% on input tokens and about 70% on output.
That's an unusual situation. It's not often that a model from outside the established frontier labs produces numbers like this, at these prices. Qwen3.7-Max deserves a careful look — not as a curiosity but as a genuine production option.
I've spent time working through the benchmarks, the API pricing, and the limitations. Here's what I actually think about it.
Key takeaways
- Qwen3.7-Max launched May 20, 2026 at Alibaba Cloud Summit, with API access opening May 19
- Pricing is $2.50 per million input tokens, $7.50 per million output — roughly half of Claude Opus 4.8
- It beats Claude Opus 4.8 on hard reasoning benchmarks: GPQA Diamond (92.4 vs 91.3), HLE (41.4 vs 40), Terminal-Bench 2.0 (69.7% vs 65.4%)
- Claude Opus 4.8 still leads on standard software engineering: SWE-Bench Verified (88.6% vs 80.4%), SWE-Bench Pro (69.2% vs 60.6%)
- Text-only, API-only, closed-weight — available via Alibaba Cloud DashScope, Model Studio, and OpenRouter
What Alibaba just shipped
Qwen3.7-Max is Alibaba's new flagship model, announced at the Alibaba Cloud Summit on May 20, 2026. It's the top tier in the Qwen3.x family, sitting above Qwen3.7 Plus, which is the multimodal option in the same generation.
The headline architecture changes from the previous generation: the context window jumped from 256K tokens on Qwen3.6-Max to 1 million tokens. That's a meaningful jump — it brings Qwen3.7-Max in line with Claude Opus 4.8 and the other frontier models that have settled on 1M as the long-context standard.
Alibaba describes the model as "agent-first" — designed for workloads that plan and act across many turns, manage long-horizon tasks, and coordinate across multi-agent pipelines. The 1M context window is directly related to that goal: you need to hold large codebases, long conversation histories, and extensive retrieved context in memory if you're running real agentic workflows.
How Qwen3.7-Max benchmarks against Claude Opus 4.8
The comparison is more nuanced than either a dismissal or an endorsement.
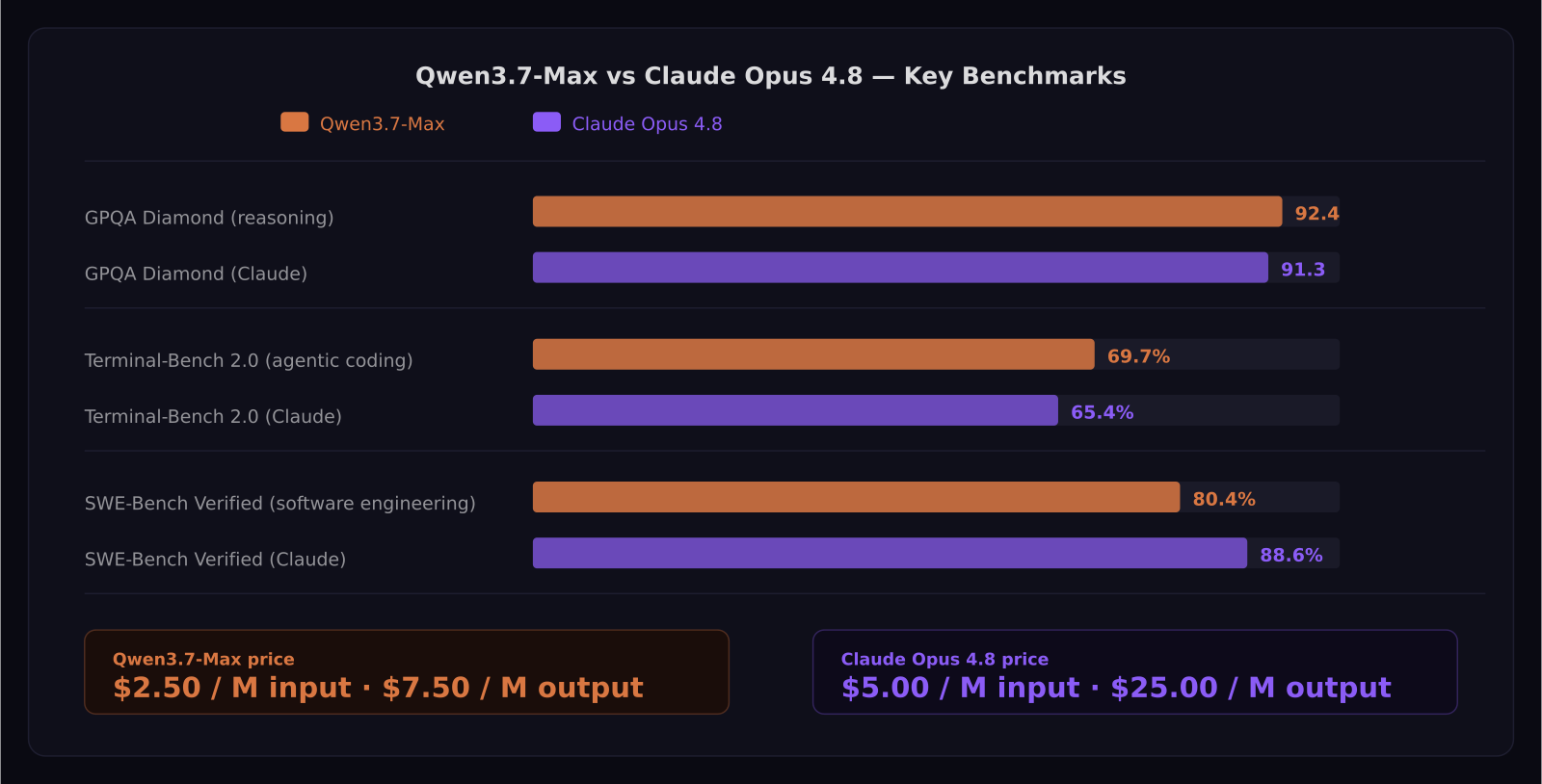
Qwen3.7-Max leads Claude Opus 4.8 on the hardest reasoning benchmarks. On GPQA Diamond, which tests expert-level scientific reasoning, Qwen3.7-Max scores 92.4 to Claude's 91.3. On HLE (Humanity's Last Exam), it scores 41.4 to Claude's 40. On HMMT 2026 February, a competition math benchmark, it scores 97.1 to Claude's 96.2. These margins are not enormous, but they're consistent — Qwen3.7-Max has a genuine edge on abstract scientific and mathematical reasoning.
Claude Opus 4.8 leads on standard software engineering tasks. SWE-Bench Verified: 88.6% to Qwen's 80.4%. SWE-Bench Pro: 69.2% to Qwen's 60.6%. These are larger gaps. If you're running a coding agent on a standard software repository doing typical bug fixes and feature implementations, Claude Opus 4.8 is still the stronger model.
The interesting flip happens on Terminal-Bench 2.0-Terminus, which specifically measures agentic coding — longer-horizon tasks where the model has to plan, execute, and recover from errors across multiple steps. Here Qwen3.7-Max scores 69.7% to Claude's 65.4%. That 4-point gap suggests that Qwen3.7-Max's architecture specifically benefits from the kind of extended, multi-turn execution that agent frameworks require.
Which coding tasks does Qwen actually win?
Based on what I've seen and what the benchmarks suggest, Qwen3.7-Max performs best in situations where you need:
Long context. If your agent needs to hold a 500K-token codebase in context while making changes, the 1M window and the model's strong MRCR-v2 128k score (90.4, ahead of Claude's 84.0) suggest it will perform better at actually retrieving and reasoning over what's far back in the context.
Extended multi-step reasoning. The Terminal-Bench advantage and the hard reasoning benchmark scores point to a model that's well-suited for problems that require holding a plan in mind across many steps — research agents, complex debugging pipelines, multi-document synthesis.
Cost-sensitive production workloads. At $2.50 per million input tokens, you can run approximately twice as many agent turns for the same cost as Claude Opus 4.8. For production pipelines where each task might involve 50-100K tokens, that cost difference adds up quickly.
Pricing: Qwen3.7-Max vs the alternatives
Qwen3.7-Max: $2.50 per million input tokens, $7.50 per million output. Cached input drops to $0.25 per million — a 90% reduction that matters a lot for agents that repeatedly read the same system prompt or reference documents.
Claude Opus 4.8: $5.00 per million input, $25.00 per million output.
GPT-5.5 Pro: pricing is roughly comparable to Claude Opus 4.8 at the top tier.
At 2x cheaper on input and over 3x cheaper on output, Qwen3.7-Max changes the math on what's affordable to run at scale. A workload that costs $500 per day on Claude Opus 4.8 might run for $150-200 on Qwen3.7-Max, depending on your input/output ratio. That's not a marginal difference — it's the kind of cost reduction that makes a new class of use cases financially viable.
The limitations worth knowing
Text-only input. Qwen3.7-Max does not accept image or video input. If your agent workflow involves screenshots, diagrams, or visual content, you'll need Qwen3.7-Plus (the multimodal sibling) or a different model entirely.
Closed weights. Unlike earlier Qwen releases that came with open weights, Qwen3.7-Max is closed-source as of its May 2026 launch. You can only access it through Alibaba Cloud's DashScope, Model Studio, or third-party aggregators like OpenRouter. You cannot download it, fine-tune it on your own data, or run it on your own infrastructure.
API only. There's no official consumer product — Qwen3.7-Max is purely an API model. The experience of evaluating it requires building or using existing API wrappers.
Preview suffix. Some endpoints still ship as qwen3.7-max-preview as of late May 2026. Alibaba hasn't announced a stable GA date, which matters for production teams that can't afford behavior changes between model versions.
Who should use Qwen3.7-Max?
The clearest fit is a developer or team running API-based agent pipelines that need strong reasoning, long context, and cost efficiency — and where the tasks are text-based rather than multimodal.
If you're building a research agent that synthesizes long documents, a code review agent that needs to hold large context, or a reasoning pipeline that runs many expensive inference calls per task, Qwen3.7-Max's combination of competitive benchmarks and lower pricing makes it worth evaluating seriously.
If you're doing standard software engineering tasks — fixing bugs in a typical GitHub repository, autocompleting code, running SWE-Bench-style evaluations — Claude Opus 4.8 still has an edge, and you might prefer that edge at the current price if the workflow is task-critical.
For creators and non-developers who want a chat product rather than an API: Qwen3.7-Max doesn't really have a consumer interface yet. It's a tool for builders.
The bigger picture: Chinese AI has stopped being a curiosity and started being a serious part of the production stack. Qwen3.7-Max is not a model that beats the frontier across the board. But it beats it on enough benchmarks, at enough of a price advantage, that ignoring it because it comes from Alibaba is starting to feel like a technical error rather than a reasonable position.
Frequently asked questions
Is Qwen3.7-Max better than Claude Opus 4.8?
On hard reasoning tasks (GPQA Diamond, HLE, Terminal-Bench agentic coding) and long-context retrieval, Qwen3.7-Max scores higher than Claude Opus 4.8. On standard software engineering benchmarks (SWE-Bench Verified and Pro), Claude Opus 4.8 still leads. Qwen3.7-Max is also about half the price. The right choice depends on your specific task and budget.
Can I use Qwen3.7-Max for free?
Qwen3.7-Max has no free consumer tier. It's a paid API model available through Alibaba Cloud DashScope, Model Studio, and third-party providers like OpenRouter. Some providers may offer trial credits, but there's no ongoing free access.
Does Qwen3.7-Max support images?
No. Qwen3.7-Max is text-only. For image and video input, you need Qwen3.7-Plus, which is the multimodal model in the same generation. However, Qwen3.7-Plus has a smaller context window and different benchmark performance, so choosing between them depends on whether you need multimodal capabilities.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master