AI Tools
Claude Opus 4.8 vs GPT-5.5: Which Frontier AI Model Should You Use in 2026?

Claude Opus 4.8 is the stronger pick for most agentic, coding, and knowledge work in 2026: it leads GPT-5.5 on SWE-bench Pro by 10.6 percentage points, hallucinates at a fraction of the rate (35.9% vs 86%), and costs $5 less per million output tokens. GPT-5.5 takes the crown on terminal-based coding and is the only frontier model with native audio. If those two things drive your workflow, you have a real choice. Otherwise, Opus 4.8 is hard to argue against.
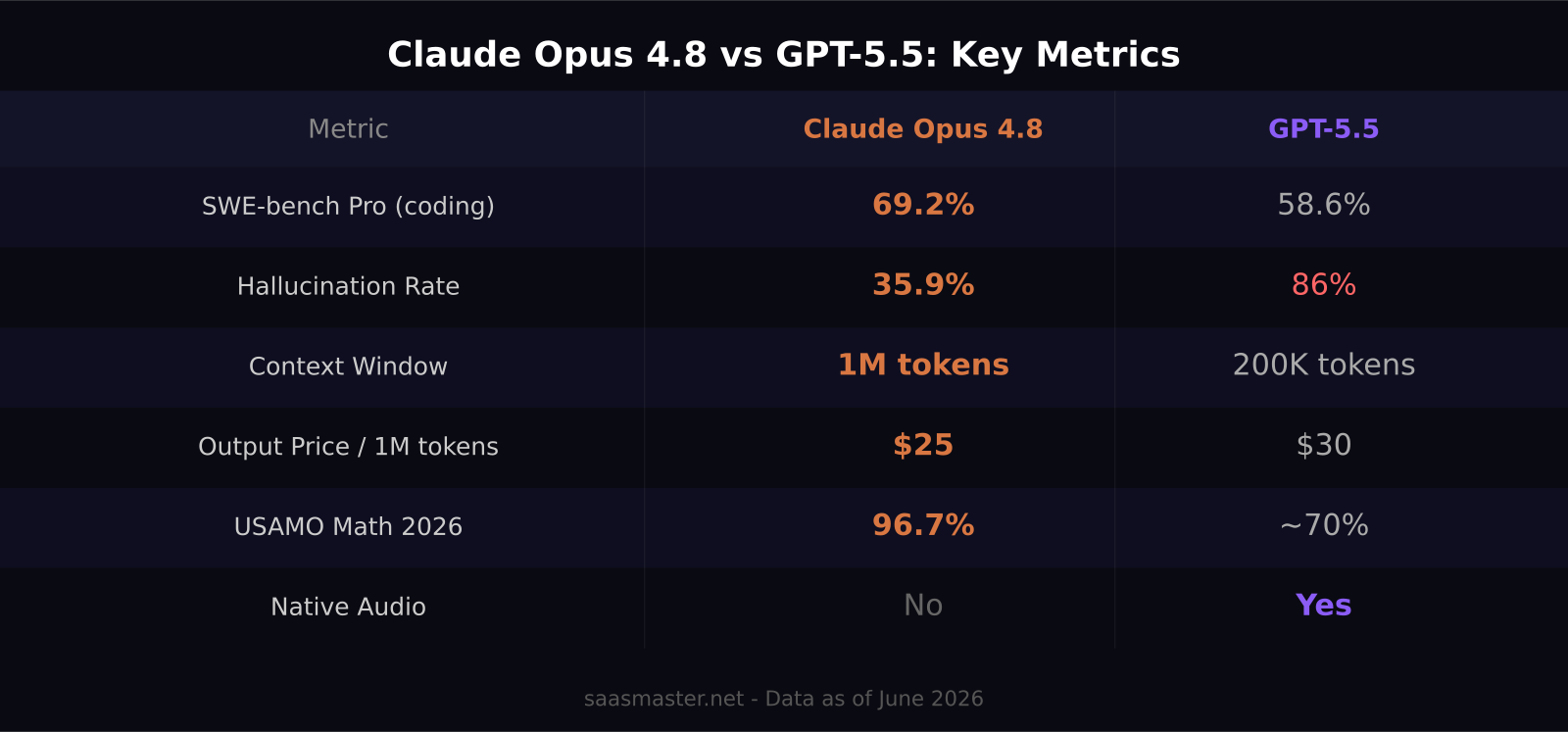
Key takeaways: - Claude Opus 4.8 scores 69.2% on SWE-bench Pro vs GPT-5.5 at 58.6% — a 10.6-point lead on one of the hardest coding benchmarks available - Opus 4.8's hallucination rate (35.9%) is dramatically lower than GPT-5.5's (86%), which matters for professional and legal work - Both start at $5 per million input tokens; Opus 4.8 is $25/M output vs GPT-5.5 at $30/M - Opus 4.8 ships with a 1M token context window by default and 128K max output - GPT-5.5 wins on Terminal-Bench 2.1 coding and offers native audio that Claude currently lacks
What changed with Claude Opus 4.8?
Anthropic released Claude Opus 4.8 on May 28, 2026, and the benchmark gains are not minor. The previous generation, Opus 4.7, scored 64.3% on SWE-bench Pro and 69.3% on USAMO 2026 (Olympic-level math proofs). Opus 4.8 hits 69.2% on SWE-bench and 96.7% on USAMO — a 27.4-percentage-point jump in math reasoning in a single release. That is the kind of improvement that shows up in workflows that rely on formal logic, financial modeling, or structured reasoning where errors compound.
Long-context performance improved sharply alongside those gains. On GraphWalks BFS, the benchmark measuring a model's ability to navigate complex graphs in-context, Opus 4.8 jumped from 40.3% to 68.1% — a 27.8-point improvement. For agent workflows that need to track state across tens of thousands of tokens, this translates directly to fewer dropped threads and more reliable multi-step task completion.
New capabilities shipping with Opus 4.8 include Dynamic Workflows for parallel agentic coding sessions, Effort Control to tune reasoning depth and cost per call, and a Fast Mode that costs 3x less per token than Opus 4.7. Mid-task system messages, previously in beta, are now stable — which matters for long-running agent sessions that need new instructions mid-run without a full restart. BenchLM.ai ranks Opus 4.8 at number three across 123 models with a composite score of 93 out of 100.
What is GPT-5.5 built for?
OpenAI's GPT-5.5 is a strong frontier model, and for specific workflows it is the better pick. On Terminal-Bench 2.1 — the benchmark specifically measuring coding performance in a terminal environment — GPT-5.5 edges Opus 4.8. If your team builds CLI-heavy development tools, shell scripting pipelines, or DevOps automation, that edge matters in production.
The more important differentiator is native audio. GPT-5.5 handles audio input and output natively through OpenAI's Realtime API, which Claude Opus 4.8 does not support as of May 2026. If you are building voice-forward products — AI phone agents, transcription pipelines, voice-first interfaces — GPT-5.5 is the only frontier option that handles this without a separate processing layer adding latency and complexity.
GPT-5.5 also tends to perform better on structured tool-use tasks and bounded customer workflow automation. For workflows that are sequential and well-defined rather than open-ended and agentic, the performance gap narrows and GPT-5.5's audio advantage matters more. The pricing difference is meaningful but not dramatic: $30 per million output tokens versus $25 for Opus 4.8.
Which model wins on benchmarks?
The numbers favor Opus 4.8 across most categories. On SWE-bench Pro — real GitHub issues where models must understand existing code and fix bugs end-to-end — Opus 4.8 scores 69.2% versus GPT-5.5's 58.6%. That is a 10.6-point gap on a benchmark the AI community treats as the most rigorous proxy for real software engineering ability.
The hallucination gap is the more operationally significant finding. Opus 4.8 produces incorrect confident claims 35.9% of the time under standard evaluation. GPT-5.5 comes in at 86%. For legal research, financial analysis, medical documentation, or any professional context where confident wrong answers are costly, this difference is not a benchmark footnote — it is a real-world risk consideration.
Opus 4.8 also leads on computer use (84% on Online-Mind2Web for autonomous browser navigation), is the first model to clear 10% on the Legal Agent Benchmark's all-pass standard, and holds top positions on GDPval-AA for economic reasoning. On USAMO 2026, the Olympic-level mathematics proof competition, Opus 4.8 scores 96.7% versus approximately 70% for GPT-5.5 — a gap that reflects the model's fundamental reasoning architecture.
Which is cheaper for API developers?
Pricing is nearly identical at the input level, with Opus 4.8 holding an edge on output. Both start at $5 per million input tokens. On output, Opus 4.8 costs $25 per million tokens versus GPT-5.5's $30 — a 17% savings on generation costs at equivalent token volumes.
For latency-sensitive production use, Opus 4.8's Fast Mode changes the math. Fast Mode is priced at $10/M input and $50/M output but is 3x cheaper than the previous generation's fast pricing and delivers significantly lower latency. For batch workflows and long-running agent sessions, standard mode at $5/$25 is the default.
The 1M token context window Opus 4.8 ships with by default reduces the need for expensive pre-processing. Workflows that previously chunked and re-summarized long documents before each API call can now pass the full document in a single request, cutting both cost and the latency introduced by multi-step retrieval. At scale, that architectural simplification is meaningful.
When should you pick GPT-5.5 instead?
There are specific cases where GPT-5.5 is the right call. Native audio is the clearest: if your product requires voice input or output at the model level, GPT-5.5 handles it natively and Claude does not. Adding a separate audio layer around Claude adds latency and complexity that compounds as your product scales.
Terminal coding workflows are the second case. For CLI agents, DevOps automation, or products that live in a shell environment, GPT-5.5's Terminal-Bench lead translates to more reliable behavior in production. The gap is not enormous, but for systems where reliability matters as much as raw capability, it is worth accounting for.
For everything else — multimodal reasoning without audio, agentic code generation across real codebases, legal and compliance work, long-context analysis, and cost-sensitive API usage at scale — Opus 4.8 leads on every major benchmark I have reviewed as of June 2026.
Frequently asked questions
Is Claude Opus 4.8 better than GPT-5.5?
For most use cases in 2026, yes. Opus 4.8 leads on SWE-bench Pro, USAMO math, hallucination rates, and long-context performance. The exceptions are terminal-based coding and native audio, where GPT-5.5 has the edge. If neither of those is central to your workflow, Opus 4.8 is the stronger default.
What does Claude Opus 4.8 cost per million tokens?
Standard pricing is $5 per million input tokens and $25 per million output tokens. Fast Mode costs $10 per million input and $50 per million output, designed for latency-sensitive production deployments. GPT-5.5 is $5 input and $30 output at standard pricing.
Does Claude Opus 4.8 support audio input?
No. Claude Opus 4.8 does not support native audio input or output as of its May 2026 release. If audio processing is a core requirement, GPT-5.5 via OpenAI's Realtime API or Gemini 3 Pro are better-suited alternatives for voice-forward applications.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
