AI Tools
Claude Sonnet 5 vs Chinese AI in 2026: DeepSeek, Kimi, and Qwen Compared

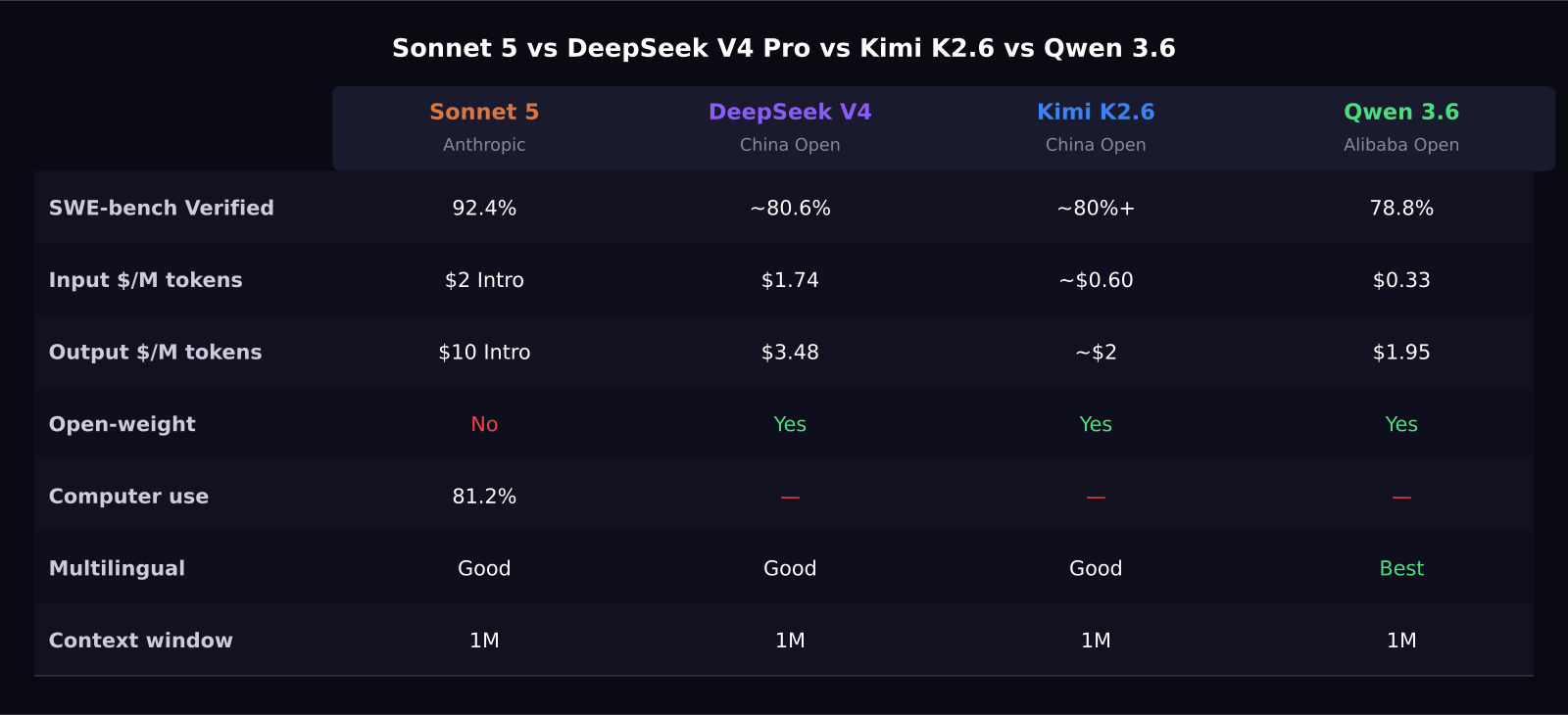
Chinese AI models now hold a serious share of the global AI market in 2026, and three of them, DeepSeek V4 Pro, Kimi K2.6, and Qwen 3.6 Plus, all offer competitive alternatives to Claude Sonnet 5 at significantly lower prices. Claude Sonnet 5 at 92.4% on SWE-bench Verified leads on the most-cited coding benchmark. But DeepSeek V4 Pro at $1.74 per million tokens, Kimi K2.6 under $0.60, and Qwen 3.6 Plus at $0.33 all undercut it sharply. Here is the full four-way comparison.
Key takeaways
- Sonnet 5 leads SWE-bench Verified at 92.4%. DeepSeek V4 Pro leads LiveCodeBench at 93.5%. Qwen 3.6 Plus scores 78.8% on SWE-bench Verified.
- Qwen 3.6 Plus is the cheapest at $0.33 input. Kimi K2.6 is next at under $0.60. DeepSeek V4 Pro at $1.74 is closest to Sonnet 5's $2 intro rate.
- All three Chinese models are open-weight. Sonnet 5 is closed.
- Sonnet 5 leads on computer use, full agentic stack, and Western compliance guarantees.
- For Chinese or multilingual markets, Qwen 3.6 Plus is the native-language choice.
Why Chinese AI is a real comparison now
A year ago, Chinese AI models were interesting but clearly below Western frontier models on most benchmarks. In mid-2026, DeepSeek V4 Pro and Kimi K2.6 are within 10 to 12 points of Sonnet 5 on SWE-bench Verified while costing 3 to 6 times less. Qwen 3.6 Plus trails more on coding but leads on multilingual tasks that matter for specific markets.
This is not a charity comparison. These are production-ready models that real SaaS teams are choosing today based on cost and use-case fit.
Benchmark snapshot
On SWE-bench Verified: Sonnet 5 at 92.4% leads, followed by DeepSeek V4 Pro at approximately 80.6%, Kimi K2.6 at 80%+, and Qwen 3.6 Plus at 78.8%. All three Chinese models cluster in the same range that was considered top-tier six months ago.
On LiveCodeBench, which tests competitive algorithm coding: DeepSeek V4 Pro leads at 93.5%, followed by Sonnet 5 at 88.8%. Kimi K2.6 and Qwen 3.6 Plus do not have widely published LiveCodeBench scores.
On multilingual tasks: Qwen 3.6 Plus is the clear leader, ranking in the top 25 models globally for multilingual performance. Sonnet 5, DeepSeek V4 Pro, and Kimi K2.6 all handle major languages but lack Qwen's Chinese-native training advantage.
Pricing comparison across all four
At current pricing, the order from cheapest to most expensive on input tokens is: Qwen 3.6 Plus at $0.33, Kimi K2.6 at approximately $0.60, DeepSeek V4 Pro at $1.74, and Sonnet 5 at $2 intro. After August, Sonnet 5 moves to $3, widening the gap with all three.
On output tokens, the gap is even larger: Sonnet 5 at $10 intro versus DeepSeek V4 Pro at $3.48, Qwen at $1.95, and Kimi at approximately $2. For agentic workloads that generate significant output, these differences are material at scale.
The open-weight advantage
All three Chinese models are open-weight and self-hostable. This matters for three categories of SaaS companies: those with strict data residency requirements that prohibit sending data to US cloud providers; those with infrastructure where compute cost per token is lower than API pricing; and those in markets where using US-controlled AI infrastructure is politically or contractually constrained.
Sonnet 5 offers no self-hosting option. You use the API and Anthropic handles your data according to its terms of service.
When Sonnet 5 wins and when it does not
Sonnet 5 is the right choice when you need the best documented agentic stack, computer use capabilities, full tool calling reliability, and commercial support from a US-based vendor. On the hardest SaaS coding agent tasks where reliability compounds over many steps, Sonnet 5's benchmark lead is meaningful in production.
The Chinese models win on cost, openness, and for Qwen, multilingual native markets. If your primary AI tasks are standard coding, content generation, or multilingual work at scale, and you can accept a benchmark gap of 10 to 15 points on SWE-bench Verified, any of the three offers dramatic cost savings.
Frequently asked questions
Which Chinese AI model is best for SaaS coding?
DeepSeek V4 Pro leads on competitive coding and is the most mature option for production coding agents among the three. Kimi K2.6 is close on SWE-bench Verified and cheaper. For most SaaS teams, DeepSeek V4 Pro is the starting point for Chinese AI comparisons.
Is it safe for Western SaaS companies to use Chinese AI models?
This depends on your data type, jurisdiction, and company policy. Open-weight models can be self-hosted outside Chinese infrastructure entirely, which eliminates most data sovereignty concerns. Sending data to Chinese-operated APIs carries compliance risk in some industries and jurisdictions.
How does Qwen 3.6 Plus compare to the others for a global SaaS product?
For multilingual products, Qwen 3.6 Plus is in a different tier. Its Chinese-native training and multilingual benchmark lead make it the best choice for content in Asian languages. For primarily English coding or agent work, DeepSeek V4 Pro or Kimi K2.6 are closer to Sonnet 5's capability level.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
