AI Tools
Claude Sonnet 5 vs DeepSeek V4 Pro: Which Is Better for SaaS Builders in 2026?

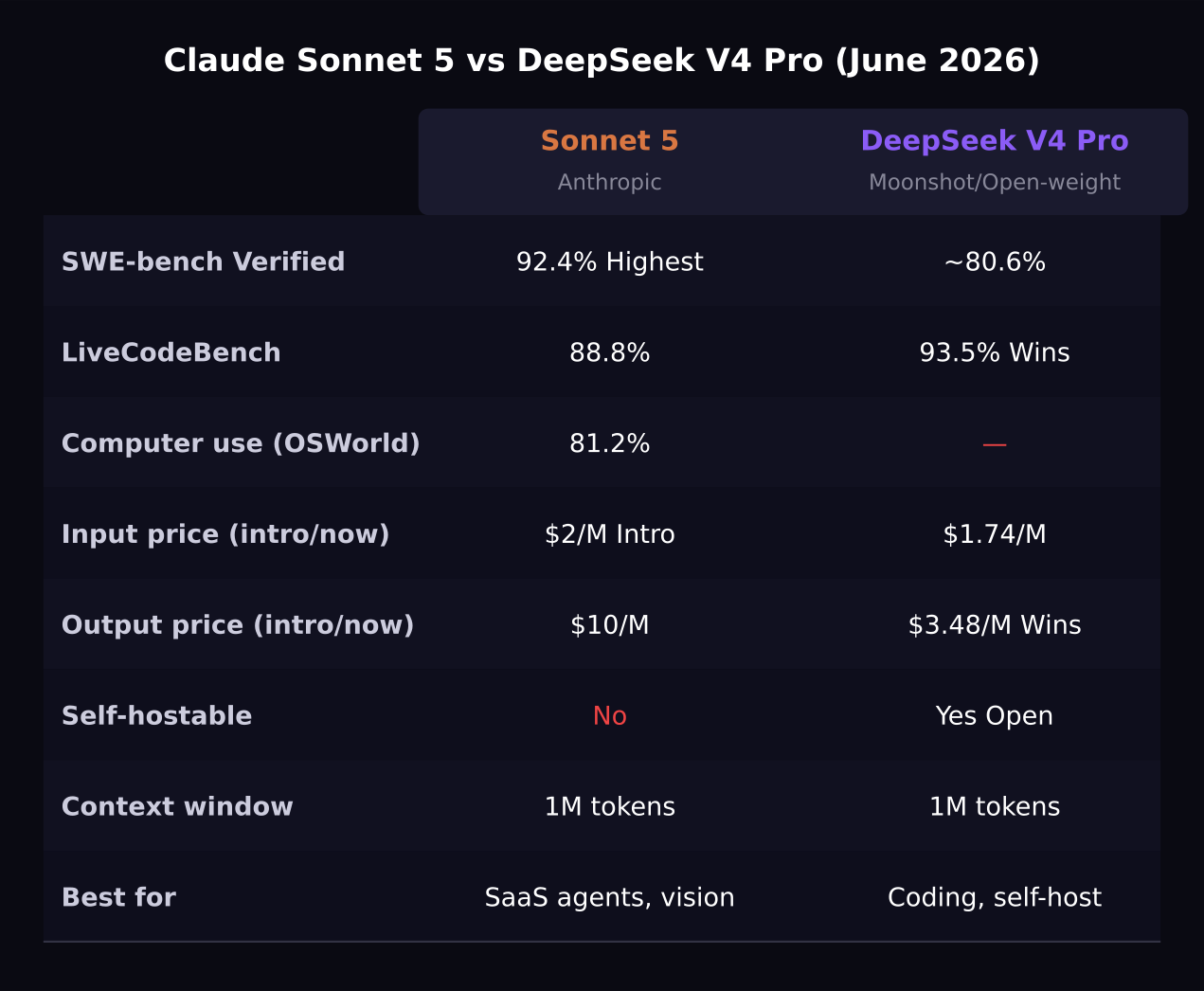
Claude Sonnet 5 and DeepSeek V4 Pro are two of the most interesting models to put side by side in mid-2026. Sonnet 5 is the Western frontier benchmark leader at 92.4% on SWE-bench Verified. DeepSeek V4 Pro is the Chinese open-weight challenger at $1.74 per million input tokens with a 93.5% score on LiveCodeBench. They are roughly tied on real-world coding quality while separated by a significant gap in price and deployment flexibility.
Key takeaways
- Claude Sonnet 5 scores 92.4% on SWE-bench Verified. DeepSeek V4 Pro scores 93.5% on LiveCodeBench, a different benchmark, and approximately 80.6% on SWE-bench Verified.
- DeepSeek V4 Pro costs $1.74 per million input tokens and $3.48 per million output tokens. Sonnet 5 intro pricing is $2 and $10 through August 31.
- DeepSeek V4 Pro is open-weight and can be self-hosted. Claude Sonnet 5 is closed and API-only.
- Sonnet 5 leads on agentic tool use, computer use at 81.2% OSWorld, and vision. DeepSeek V4 Pro leads on isolated coding speed and competitive programming.
- For production SaaS agents, Sonnet 5 is the safer choice. For cost-sensitive, self-hosted coding infrastructure, DeepSeek V4 Pro is compelling.
Benchmark breakdown
The benchmarks here are meaningful but require context. SWE-bench Verified tests models on real GitHub issues, measuring their ability to understand a codebase and fix actual bugs. Sonnet 5's 92.4% is the highest published score on this benchmark from any lab. DeepSeek V4 Pro's published SWE-bench Verified score sits around 80.6%, close to where Claude Opus 4.8 scored before Sonnet 5 raised the bar.
DeepSeek V4 Pro's strength is on LiveCodeBench, which tests competitive programming problems. Its 93.5% score exceeds Sonnet 5's 88.8% on the same benchmark. For pure algorithm and competitive coding tasks, DeepSeek V4 Pro is the stronger model. For debugging real production codebases, Sonnet 5 leads.
On Terminal-Bench 2.0, which tests autonomous terminal command execution, DeepSeek V4 Pro scored 67.9%. Sonnet 5's equivalent agentic benchmark performance is strong based on its OSWorld computer use score of 81.2%, though direct Terminal-Bench numbers for Sonnet 5 are not yet published.
Pricing reality
At intro pricing, the gap between the two models on input is $0.26 per million tokens ($2 Sonnet 5 vs $1.74 DeepSeek). On output it is $6.52 per million ($10 vs $3.48). The output cost difference is where DeepSeek V4 Pro's advantage is most pronounced in agentic workloads, where each agent step generates significant output.
At Sonnet 5's standard pricing after August, the input gap stays small ($3 vs $1.74) but the output gap grows ($15 vs $3.48). For high-output agent pipelines at scale, DeepSeek V4 Pro becomes meaningfully cheaper.
The open-weight advantage
DeepSeek V4 Pro is open-weight and can be self-hosted on your own infrastructure. For companies with data residency requirements, air-gapped environments, or cost structures that favor compute over API spend, this is a genuine advantage. You pay for GPU time instead of per-token.
Sonnet 5 cannot be self-hosted. It is available through the Anthropic API, Amazon Bedrock, and Google Cloud Vertex AI, but the model weights are not distributed.
Agentic reliability
For production SaaS agents that run multi-step tasks, Sonnet 5 is currently the better-documented choice. Claude's tool use reliability, computer use at 81.2% on OSWorld, and the Zapier case study of completing two-part automations end-to-end without stalling suggest strong agentic execution.
DeepSeek V4 Pro's agentic behavior is competitive on benchmarks but less documented in production SaaS agent frameworks. If you need reliability guarantees and commercial support, Sonnet 5 is the safer deployment path.
My recommendation
For most SaaS teams building API-based products through August 2026, Sonnet 5 at intro pricing is the default. After August, the decision depends on your output volume. If you generate more than 50 million output tokens per month, the $11.52 per million output token difference becomes significant and DeepSeek V4 Pro deserves a real test.
For teams with self-hosting infrastructure or strict data residency requirements, DeepSeek V4 Pro is one of the few open-weight models that can realistically compete with Sonnet 5 on coding quality.
Frequently asked questions
Can DeepSeek V4 Pro replace Claude Sonnet 5 for SaaS agents?
On pure coding tasks, it is competitive. On agentic tool use, computer use, and vision tasks, Sonnet 5 currently leads. For production agents where reliability and full-stack capability matter, Sonnet 5 is the safer choice.
Is DeepSeek V4 Pro really open-weight?
Yes. The weights for DeepSeek V4 Pro are publicly available. You can run it on your own hardware, through third-party API providers like Together AI, or access it through official DeepSeek APIs. The licensing terms allow commercial use with some restrictions.
Which model is better for competitive programming?
DeepSeek V4 Pro leads on LiveCodeBench at 93.5% versus Sonnet 5's 88.8%. For competitive programming specifically, DeepSeek V4 Pro is the stronger model. For real-world SaaS debugging on actual codebases, Sonnet 5's SWE-bench Verified lead is more relevant.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
