AI Tools
Claude Sonnet 5 vs GPT-5.5 vs Gemini 3.1 Pro: Best AI for Agent Workflows in 2026

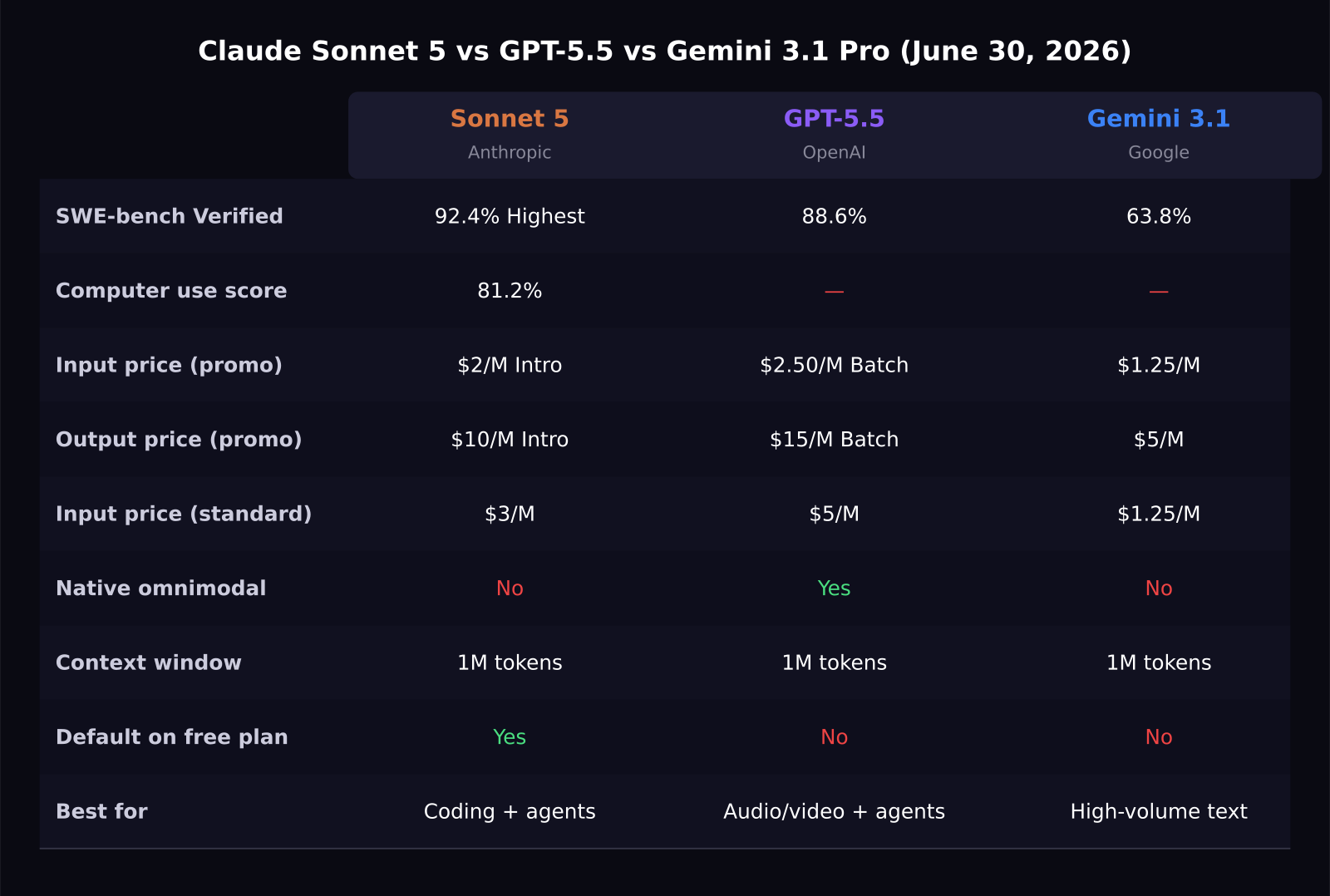
Claude Sonnet 5 launched today at $2 per million input tokens, right into a market where GPT-5.5 costs $5 and Gemini 3.1 Pro costs $1.25. The three-way comparison for AI agent workflows just got more interesting because Sonnet 5 does not just slot in as a mid-tier option: it scores 92.4% on SWE-bench Verified, higher than either competitor, while sitting at the lowest pricing of the non-Google models. Here is how the three match up for SaaS teams building agentic products in 2026.
Key takeaways
- Claude Sonnet 5 scores 92.4% on SWE-bench Verified, GPT-5.5 scores 88.6%, and Gemini 3.1 Pro scores 63.8%.
- Sonnet 5 intro pricing ($2 input / $10 output) undercuts GPT-5.5 standard pricing ($5 input / $30 output) by 60 to 70% through August 31, 2026.
- Gemini 3.1 Pro remains the cheapest at $1.25 input / $5 output but trails by 29 points on SWE-bench Verified.
- Sonnet 5 scores 81.2% on OSWorld-Verified for computer use, ahead of GPT-5.5's published computer use benchmarks.
- All three models support a 1 million token context window and agentic tool use at current API access.
What changed with Sonnet 5's launch today
Until today, the mid-tier option for SaaS agent builders was a trade-off: you either paid Opus 4.8 or GPT-5.5 prices for frontier capability, or you used a cheaper model and accepted a visible quality drop. Sonnet 5 disrupts that trade-off.
Launching at $2 per million input tokens through August 31, Sonnet 5 is priced like a mid-tier model but benchmarks like a frontier one. Its 92.4% on SWE-bench Verified is higher than GPT-5.5's 88.6%, the previous highest published score from any lab. That means the cheapest of the three non-Gemini options now outscores the most expensive on the main coding benchmark.
Benchmark comparison
On SWE-bench Verified, Sonnet 5 leads at 92.4%, followed by GPT-5.5 at 88.6% and Gemini 3.1 Pro at 63.8%. The Sonnet 5 vs GPT-5.5 gap is 3.8 points. The Sonnet 5 vs Gemini gap is 28.6 points.
On computer use via OSWorld-Verified, Sonnet 5 scores 81.2%, which is above the human expert baseline of 72.4%. Sonnet 5 is explicitly designed as the most agentic Sonnet model yet, with improvements specifically in reasoning, tool use, and autonomous execution.
GPT-5.5's advantage is its native omnimodal architecture. Text, audio, image, and video flow through one model. If your agent pipeline involves processing audio recordings, video frames, or mixed-media inputs, GPT-5.5 is the only model here with a native omnimodal stack. Sonnet 5 and Gemini 3.1 Pro handle images and text but route audio and video differently.
Pricing for agent workloads
Pricing matters more in agent workflows than in single-turn interactions because agents make many more API calls to complete a task. A single agentic session might involve dozens of tool calls, each billing at the output token rate.
At intro pricing, Sonnet 5 at $2 input and $10 output is the strongest value for agent work among the three. GPT-5.5 at $5 input and $30 output (standard) or $2.50 and $15 (batch) is 2.5 to 3 times more expensive at standard rates. Gemini 3.1 Pro at $1.25 and $5 is cheaper but scores 29 points lower on coding.
For a SaaS product running 10 million output tokens per month in agent tasks, the difference between Sonnet 5 intro pricing and GPT-5.5 standard pricing is $200,000 per year. Even at Sonnet 5's regular rate of $3 and $15 after August, the annual saving versus GPT-5.5 standard is around $180,000.
When to choose each model
Sonnet 5 is the best default for SaaS teams building agent workflows that involve coding, browser control, terminal commands, or tool orchestration. It tops the coding benchmark, leads on computer use, and is priced aggressively through August. If you are evaluating AI for a new product in mid-2026, Sonnet 5 is the first model to put in your test suite.
GPT-5.5 is the right choice if your agent pipeline genuinely needs native omnimodal processing: real-time voice, video frame analysis, or audio-to-action workflows where a unified model matters architecturally. On pure coding tasks, GPT-5.5 now trails Sonnet 5 on SWE-bench Verified for the first time since GPT-5.5 launched.
Gemini 3.1 Pro remains the value choice for high-volume applications where the coding benchmark gap is acceptable. For content generation, summarization, classification, and document analysis at scale, the quality difference from Sonnet 5 is narrow for non-coding tasks while the price advantage is significant at $1.25 versus $2 per million input tokens.
The emerging Anthropic model stack
One pattern worth noting from today's launch: Anthropic now has a clearer model stack than at any point in the past year. Sonnet 5 covers most real-world agent use cases at low cost. Opus 4.8 handles the hardest autonomous agent runs where failure is expensive. Haiku handles fast, cheap, high-volume inference.
That clarity is useful for SaaS teams picking a primary model. The previous situation, where Sonnet 4.6 and Opus 4.8 overlapped significantly in capability, made the decision less obvious. Sonnet 5's coding benchmark lead over Opus 4.8 on SWE-bench Verified actually makes Opus easier to justify: you pay the premium specifically when you need the best performance on the hardest agent tasks, not just generally.
My take
Sonnet 5's launch changes my default recommendation for SaaS agent builders today. Through August, at $2 input and $10 output, this is the most cost-effective frontier model for agent work I have seen in 2026. The benchmark lead over GPT-5.5 on coding is real and the price advantage is substantial.
After August, when Sonnet 5 moves to $3 and $15, the decision becomes more nuanced. But for teams building or evaluating agent products right now, the intro pricing window is worth using deliberately.
Frequently asked questions
Does Sonnet 5 beat GPT-5.5 on all benchmarks?
On SWE-bench Verified (coding), yes: 92.4% versus 88.6%. On native omnimodal tasks involving audio and video, GPT-5.5 has no direct competitor because Sonnet 5 is not natively omnimodal. On computer use, Sonnet 5 at 81.2% on OSWorld-Verified is strong. The benchmark picture favors Sonnet 5 for most SaaS agent use cases.
How long is the Sonnet 5 intro pricing available?
Through August 31, 2026. After that date, Sonnet 5 prices move to $3 per million input tokens and $15 per million output tokens. Even at regular pricing, Sonnet 5 remains cheaper than GPT-5.5 standard rates.
Is Gemini 3.1 Pro still worth using after Sonnet 5 launched?
Yes, for cost-sensitive, non-coding workloads. Gemini is $1.25 input and $5 output, half the cost of Sonnet 5's intro pricing. For content generation, summarization, classification, and document work at scale, the quality gap from Sonnet 5 on non-coding tasks is much smaller than the 29-point coding benchmark gap suggests.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
