AI Tools
DeepSeek V4 Pro vs Kimi K2.6 vs Qwen3.7-Max: Which Open-Weight AI Model Wins in 2026?

DeepSeek just closed $7.4 billion in its first-ever funding round — led by Tencent, with CATL, NetEase, and JD.com also investing. The deal values the company at between $52 billion and $59 billion. That alone would make headlines. But the bigger story is what the funding signals about the broader open-weight Chinese AI race: three models — DeepSeek V4 Pro, Kimi K2.6, and Qwen3.7-Max — now compete seriously with Western frontier models at a fraction of the price. If you are building a SaaS product that runs AI inference at scale, knowing which one wins for your use case could save you real money.
Key takeaways
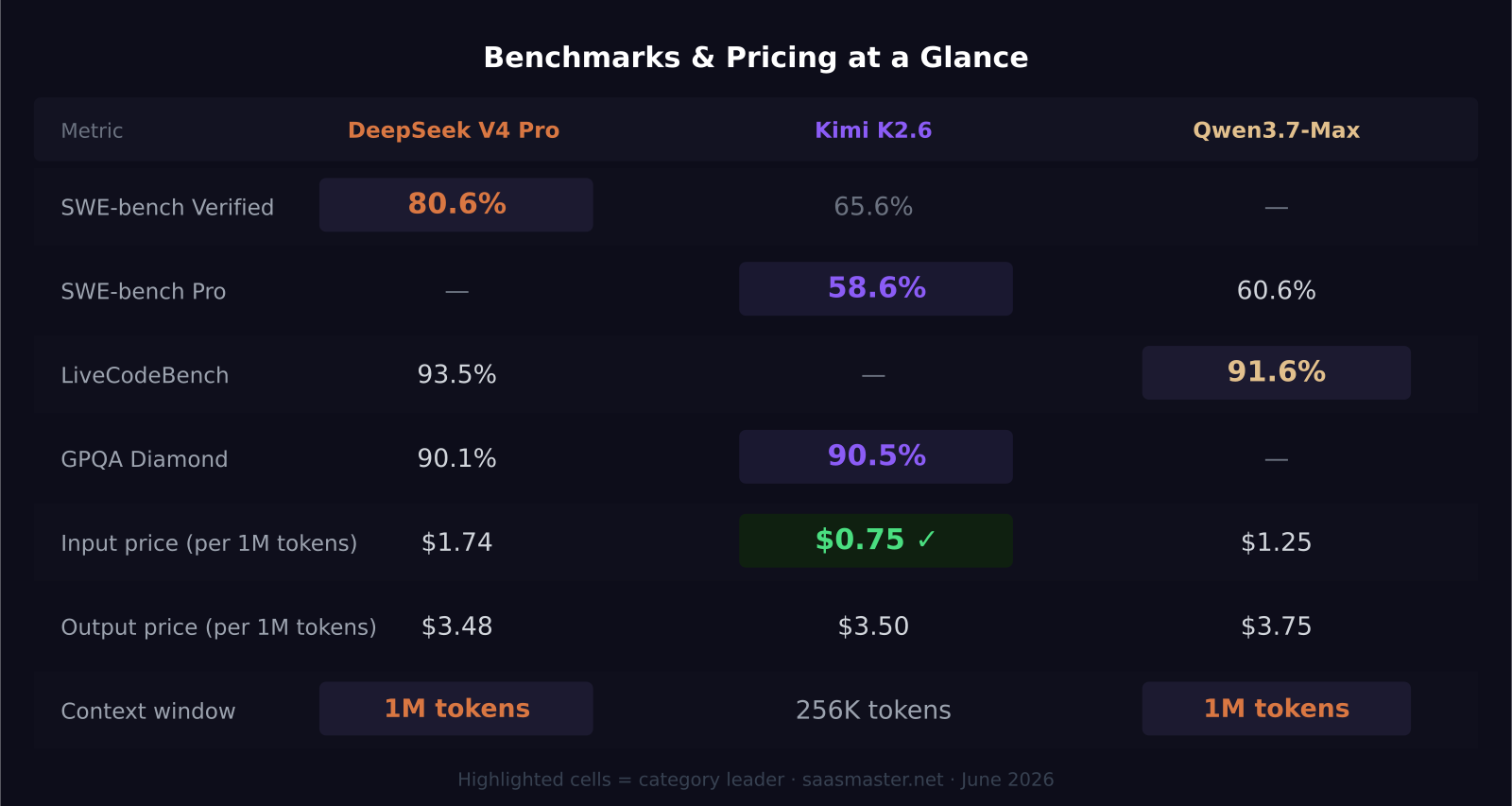
- DeepSeek V4 Pro leads SWE-bench Verified at 80.6%, the highest score among all open-weight models, making it the top choice for agentic coding tasks
- Kimi K2.6 from Moonshot AI is the cheapest of the three at $0.75/M input tokens and leads on GPQA Diamond at 90.5%, making it ideal for science reasoning and long-horizon agent workflows
- Qwen3.7-Max from Alibaba posts 91.6% on LiveCodeBench, challenging GPT-5.5 and Claude Opus 4.8 directly on coding throughput, with a 1M token context window
- DeepSeek V4 Flash offers $0.28/M output tokens — roughly 35x cheaper than GPT-5.2 — for high-volume production use cases where cost dominates
- U.S. teams should audit compliance before routing sensitive data through Chinese-operated APIs, following congressional investigations into Cursor and Airbnb for using Kimi and Qwen infrastructure
Why the open-weight Chinese model race matters right now
Open-weight models have always been appealing on paper. The catch was usually quality: community leaderboards would celebrate a new release, benchmarks looked impressive, and then real-world use revealed gaps in instruction following, tool use, or multi-step reasoning. That gap has largely closed.
DeepSeek V4 Pro tops the open-weight leaderboard on SWE-bench Verified, the standard benchmark for agentic software engineering. Kimi K2.6 leads on GPQA Diamond, which tests graduate-level science reasoning, and is built specifically for long-horizon agent tasks. Qwen3.7-Max challenges GPT-5.5 and Claude Opus 4.8 directly on coding throughput.
DeepSeek's $7.4 billion Series A adds important context. Founder Liang Wenfeng personally contributed 20 billion yuan to the round. The all-domestic investor syndicate — which grants no voting rights to external investors and includes a five-year lockup — is structured to keep control tightly held while dramatically expanding the company's compute budget. This is a well-capitalized lab building for the long term, not a research project.
DeepSeek V4 Pro: The benchmark leader
DeepSeek V4 Pro is a Mixture of Experts model with 1.6 trillion total parameters and 49 billion active parameters per forward pass. That architecture — activating only a fraction of the full parameter count per token — is how DeepSeek can serve a model that is nominally enormous at a price that stays below the Western frontier.
On SWE-bench Verified, DeepSeek V4 Pro scores 80.6%. That is the highest posted by any open-weight model, and it is 15 points ahead of Kimi K2.6 on the same benchmark. It also leads on LiveCodeBench at 93.5% and Terminal-Bench at 67.9%. For teams building coding agents, automated PR review systems, or developer-facing AI products, those are the numbers that matter.
Pricing: $1.74/M input tokens, $3.48/M output tokens. Context window: 1 million tokens.
DeepSeek also offers V4 Flash for volume-driven use cases. V4 Flash uses 284 billion parameters (13 billion active) and prices at $0.07/M input and $0.28/M output. That $0.28 output price is extraordinary — it is in the range where AI-powered consumer applications become economically viable even without aggressive caching. For teams processing millions of short queries daily, V4 Flash is worth serious evaluation.
Kimi K2.6: The long-context agent
Kimi K2.6 comes from Moonshot AI, a Beijing-based lab that has consistently positioned Kimi for long-document and long-horizon agent tasks. K2.6 is a 1 trillion parameter MoE model with 32 billion active parameters, and its strongest selling point is the combination of a 256K token context window, strong science reasoning, and an input price of $0.75/M tokens.
On GPQA Diamond, the benchmark for graduate-level science and math reasoning, Kimi K2.6 scores 90.5%, edging out DeepSeek V4 Pro's 90.1%. On SWE-bench Pro — a harder variant of the software engineering benchmark — Kimi K2.6 scores 58.6%. For HLE (Hard Long-horizon Evaluation), Kimi K2.6 leads the Chinese model field at 54.0%.
Where Kimi K2.6 consistently wins in practice is tasks involving long input, multi-step reasoning across complex documents, or bilingual Chinese and English workflows. Its cheaper input pricing makes it meaningfully more cost-effective for long-context tasks where input tokens accumulate fast. A 200,000-token document analysis run on Kimi K2.6 costs $0.15 in input costs. On DeepSeek V4 Pro, that same run costs $0.35.
Qwen3.7-Max: Alibaba's coding challenger
Qwen3.7-Max is Alibaba's current frontier model, released in May 2026 with a 1M token context window. Alibaba's marketing calls it their "Agent Frontier" model, and the benchmarks support that positioning. On LiveCodeBench, Qwen3.7-Max posts 91.6%, the highest of the three models covered here. On SWE-bench Pro, it scores 60.6%, which is marginally above Kimi K2.6 and directly competitive with GPT-5.5 on that benchmark.
Pricing sits between the other two: $1.25/M input, $3.75/M output. The 1M context window matches DeepSeek V4 Pro's, which matters for long autonomous execution tasks.
Where Qwen3.7-Max shines in practice is short-turn code generation and Q&A tasks where input costs are low and quality per token is the priority. For SaaS products adding AI-assisted coding features, Qwen3.7-Max is a strong performer. Teams with existing Alibaba Cloud relationships will find it particularly easy to deploy.
Which is cheaper, DeepSeek, Kimi, or Qwen?
On input tokens, Kimi K2.6 is the clear winner at $0.75/M. That is 43% cheaper than Qwen3.7-Max and 57% cheaper than DeepSeek V4 Pro. On output tokens, the three models price within $0.27 of each other: DeepSeek V4 Pro at $3.48, Kimi K2.6 at $3.50, Qwen3.7-Max at $3.75 per million.
For long-context workloads where input tokens dominate — document analysis, large codebases, long system prompts — Kimi K2.6 has a real cost advantage. For short-prompt, high-throughput workloads, the output price difference is small enough that model quality and latency should drive the decision.
For teams where cost is genuinely the binding constraint, DeepSeek V4 Flash at $0.28/M output is in a category of its own. Compare that to GPT-5.2 at approximately $10/M output — the gap is 35x. For classification, summarization, and extraction at scale, V4 Flash is the obvious evaluation candidate.
The compliance reality U.S. teams cannot skip
Using Chinese AI models in production is not a purely technical decision in 2026. Congressional investigations into Anysphere (the company behind Cursor) and Airbnb followed their disclosures that they had used Qwen and Kimi infrastructure to build AI systems. Neither company was found to have violated a law, but the investigations created significant reputational friction.
The scrutiny is focused on data routing, not model weights. Self-hosted open-weight deployment — running DeepSeek V4 or Qwen weights on U.S.-based infrastructure — eliminates the API-level data routing concern entirely. Teams that need to use the hosted APIs should review their data handling agreements carefully and get legal sign-off before routing regulated or sensitive user data through endpoints operated by Chinese-headquartered companies.
The models themselves are technically excellent. The compliance picture requires more intentional handling than most developers initially expect.
What to actually pick
For complex agentic coding tasks — automated PR review, code generation agents, multi-step tool-calling workflows — DeepSeek V4 Pro leads on SWE-bench Verified and is the default choice.
For long-document analysis, bilingual Chinese and English workflows, or science-heavy reasoning tasks where input cost accumulates on long contexts — Kimi K2.6.
For short-turn code generation and quick Q&A at strong quality — Qwen3.7-Max, particularly if you are on Alibaba Cloud already.
For high-volume consumer applications where $0.28/M output makes a real difference to unit economics — DeepSeek V4 Flash.
Frequently asked questions
Is DeepSeek V4 Pro better than GPT-5.5?
On SWE-bench Verified, DeepSeek V4 Pro (80.6%) is competitive with GPT-5.5 on coding benchmarks and significantly cheaper. On speed, GPT-5.5 is faster. On general enterprise compliance and first-party API reliability, GPT-5.5 remains the safer default for most U.S. teams. For pure coding agent tasks on a budget and with self-hosted weights, DeepSeek V4 Pro is a strong alternative.
Can I run these models without using their hosted APIs?
DeepSeek V4 Pro, Qwen3.7-Max, and Kimi K2.6 weights are all available under open or open-weight licenses, meaning you can self-host them on U.S.-based NVIDIA infrastructure. Self-hosting eliminates the API-level data routing concern but requires meaningful GPU investment upfront.
Are Chinese AI models safe to use in a U.S.-based SaaS product?
Running open weights on U.S. infrastructure is generally distinct from routing data through Chinese-operated APIs. For regulated data — healthcare, finance, government — consult legal counsel before choosing either deployment path. For non-sensitive data, self-hosted open weights are the cleanest option from a compliance standpoint.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
