AI Tools
Gemini 3.5 Flash Is Now Google's Default AI: What SaaS Builders Need to Know in 2026

Four weeks ago, Google replaced its flagship consumer AI model with something that was supposed to be the fast, affordable option. Gemini 3.5 Flash launched at Google I/O on May 20, 2026, and by that evening it had become the default model across the Gemini app, AI Mode in Google Search, and the Vertex AI and Gemini APIs for developers. The surprising part: it already outperforms Gemini 3.1 Pro on the benchmarks that matter most for real developer workflows — despite launching as the "lightweight" tier.
Key takeaways
- Gemini 3.5 Flash launched May 20, 2026 and is now the default AI across the Gemini consumer app, Google Search AI Mode, and Vertex AI API
- Pricing is $1.50 per million input tokens and $9.00 per million output tokens, with a 1 million token context window included
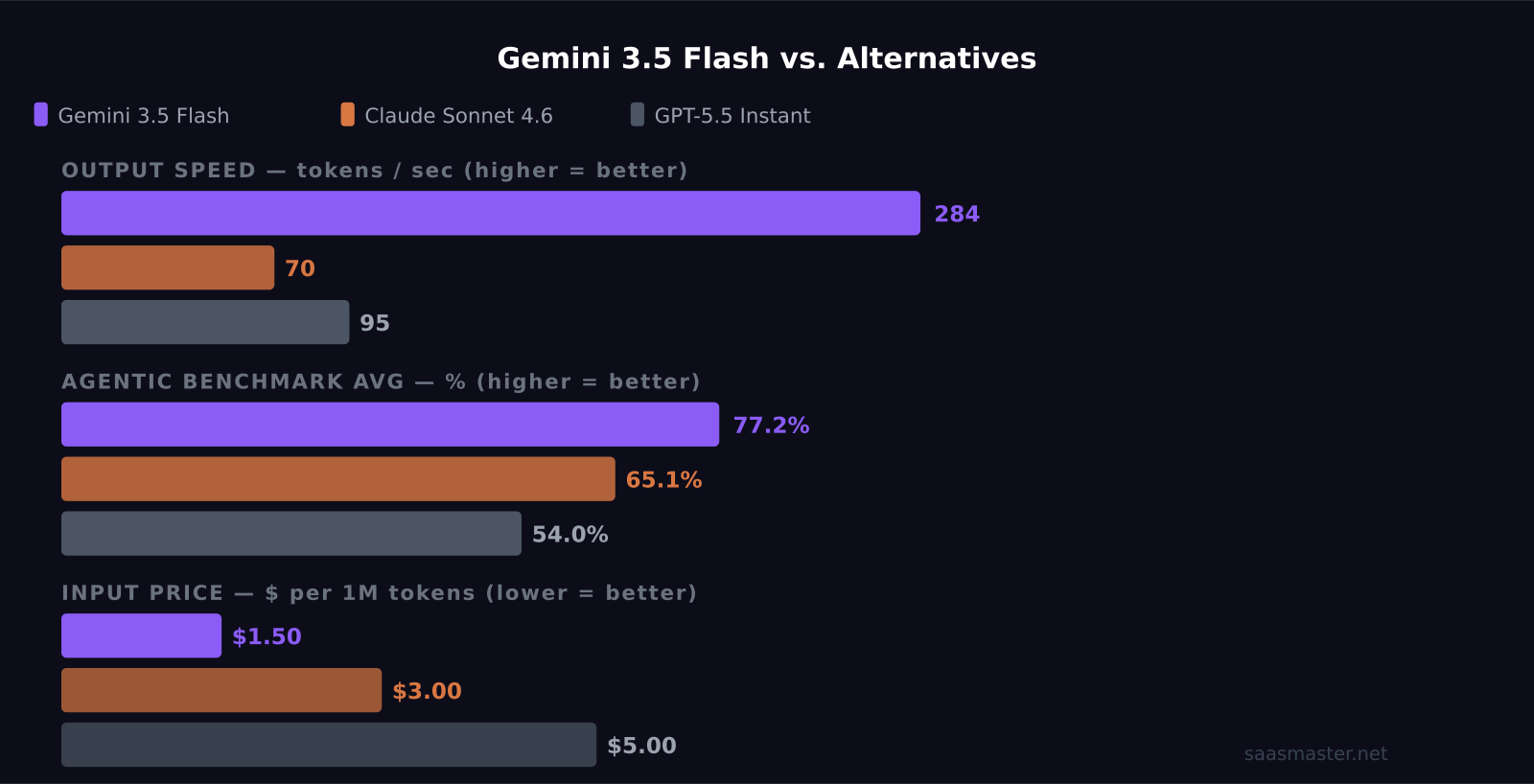
- Output throughput exceeds 280 tokens per second, roughly 4x faster than Claude Sonnet 4.6 — a meaningful advantage for batch pipelines and agent loops
- Flash leads Claude Sonnet 4.6 on agentic benchmarks with an average score of 77.2% versus 65.1%, but Claude Sonnet 4.6 still wins on coding accuracy and first-token latency
- Gemini 3.5 Pro, with a 2 million token context window and Deep Think reasoning, was promised "this month" by Sundar Pichai but remains in limited Vertex preview as of June 19
Flash beating Pro — what actually changed
Every generation of Gemini has moved intelligence downward in the product line. Gemini 3.5 Flash's capabilities in 2026 match what Gemini 3.1 Pro could do six months ago, at a lower price point and faster throughput. This is not unique to Google — OpenAI's mini models consistently catch up to the prior flagship within a product cycle.
What makes this notable is the scope of the deployment decision. Google did not just update a developer API — it replaced the default model across its consumer products. Everyone using the Gemini app in a browser, asking AI Mode questions in Google Search, or accessing Vertex AI through the standard API endpoint is now running Flash. That is a strong signal that Google considers Flash production-ready for the vast majority of real-world use cases, not just a cost-saving tier for budget-conscious developers.
For SaaS builders who have been weighing Flash versus Pro or versus competing models, the default switch tells you what Google's own judgment is. They bet on Flash being good enough.
What does Gemini 3.5 Flash actually cost?
At $1.50/M input and $9.00/M output with a 1 million token context window, Gemini 3.5 Flash is priced meaningfully below its main competitors. Claude Sonnet 4.6 runs $3.00/M input and $15.00/M output. GPT-5.5 Instant prices at $5.00/M input and $15.00/M output. On a blended 3:1 input-to-output ratio, Gemini 3.5 Flash is roughly 1.8x cheaper than Claude Sonnet 4.6 per token.
One important caveat for teams migrating from previous Gemini versions: pricing has gone up. Gemini 3.5 Flash pricing is approximately 3x higher than Gemini 2.5 Flash. The capability jump is real, but if you built cost projections around Gemini 2.x pricing, those models need to be recalculated before you migrate to the new default.
How fast is 280 tokens per second?
Speed matters differently depending on what you are building. A consumer chatbot hitting 280 tokens per second would generate text so fast it becomes unreadable — humans can process about 50-60 tokens per second before it feels like a wall of text. But for an AI agent running 20 tool calls in a loop, or a pipeline ingesting thousands of documents in a batch job, throughput directly translates to wall-clock time and infrastructure cost.
Gemini 3.5 Flash's 280+ tokens per second output rate is roughly 4x faster than Claude Sonnet 4.6 and about 3x faster than GPT-5.5 Instant on independent benchmarks. For a pipeline processing 10,000 documents at an average of 500 output tokens each, that throughput advantage could reduce compute time from hours to under an hour — without any architectural changes to your system.
The practical implication for SaaS builders: if you are running AI-powered features that process large volumes of data — report generation, document ingestion, bulk classification, automated code review across a large repository — Gemini 3.5 Flash's throughput advantage is worth measuring in your specific workload.
Where Gemini 3.5 Flash leads and where it does not
The benchmark picture is positive but task-specific. On agentic benchmarks — tasks involving multi-step tool use, autonomous execution, and real-world agent workflows — Gemini 3.5 Flash leads Claude Sonnet 4.6 by a clear margin: 77.2% average versus 65.1%. On Terminal-Bench 2.1, Flash scores 76.2% versus Gemini 3.1 Pro's 70.3%. On MCP Atlas, Flash scores 83.6% versus 78.2%. On Finance Agent v2, Flash scores 57.9% versus 43.0%.
On coding accuracy and SWE-bench-style tasks, Claude Sonnet 4.6 still has the edge. On first-token latency — time to the first visible character of output — Claude Sonnet 4.6 responds faster, which matters for interactive chat applications where perceived responsiveness is critical.
The Artificial Analysis Intelligence Index scores Flash at 55, behind Claude Opus 4.8 at 61.4 and GPT-5.5 at 60.2. Flash is not the highest-intelligence model on the market. It is the best combination of intelligence, speed, and price at this tier.
Should you build on Flash now or wait for Gemini 3.5 Pro?
Sundar Pichai told the Google I/O audience to expect Gemini 3.5 Pro "this month" — meaning June 2026. As of June 19, it remains in limited Vertex AI preview with no public general availability date. There are 11 days left in the month.
Expected Gemini 3.5 Pro capabilities: a 2 million token context window, Deep Think reasoning mode for complex multi-step problems, and frontier-level intelligence scores targeting Claude Opus 4.8 and GPT-5.5. Expected pricing based on prior Pro-to-Flash ratios: approximately $15/M input, $60/M output — which would put it in the same range as the current Western frontier models.
My recommendation: build on Flash now for any use case that does not specifically require a 2 million token context window or frontier-level reasoning on extremely complex multi-step problems. For standard pipelines — RAG, coding copilots, customer-facing chat, document summarization, content generation — Gemini 3.5 Flash is production-ready and Google has already made the call that it is good enough for their own products.
If you are evaluating Pro, wait for the GA release and test it against your specific workload before committing your architecture. Paying 10x more per token is only worth it if the capability gap is measurable in your actual use case.
Practical workflows where Gemini 3.5 Flash wins
Long-document processing is the clearest fit. Legal document review, technical documentation analysis, code repository summarization, research digest pipelines — tasks where you need to fit several hundred thousand tokens into a single context and get structured output back. At $1.50/M input, processing a 700,000-token document costs about $1.05 in input costs, which is roughly half what Claude Sonnet 4.6 would charge for the same job.
High-volume API pipelines are the second obvious fit. SaaS products generating AI output for thousands of users daily benefit meaningfully from 280+ tokens per second throughput. Faster output means lower latency at the user level and lower infrastructure cost at the platform level.
Google Workspace integration is a third. If your customers operate primarily in Google Docs, Drive, and Workspace, and you are building plugins, automations, or AI-powered features on top of those surfaces, the Gemini 3.5 Flash API is the natural choice. Google has committed to Gemini as the intelligence layer across its entire productivity suite, and that tight integration is not replicated by third-party models.
What the default switch means for how users perceive AI
When Google makes Flash the default across its consumer products, they are not just making an API decision. They are training user expectations. The majority of people interacting with AI through Google products in 2026 are now calibrating their sense of "what AI should feel like" against Flash's speed, output style, and quality level.
For SaaS builders competing in the productivity and workflow space, this has a subtle but real effect. Flash's responsiveness and agentic benchmark performance are now the reference point for a massive segment of users. Building on Flash means your product matches those expectations. Building on a slower, more expensive model means you need a clear quality advantage to justify the tradeoff.
Build on Flash. Evaluate Pro when it ships GA. That is the reasonable call for almost every SaaS use case in June 2026.
Frequently asked questions
Is Gemini 3.5 Flash available right now?
Yes. Gemini 3.5 Flash has been available through the Gemini API and Vertex AI since May 20, 2026. It is also the default model in the Gemini consumer app and AI Mode in Google Search. You can start using it immediately via the Gemini API with your existing API key.
How does Gemini 3.5 Flash compare to Claude Sonnet 4.6 for SaaS applications?
Gemini 3.5 Flash is faster at 280+ tokens per second versus approximately 70 for Claude Sonnet 4.6, and cheaper at $1.50/M input versus $3.00/M. Flash leads on agentic benchmarks by a clear margin. Claude Sonnet 4.6 leads on coding accuracy, SWE-bench tasks, and first-token latency. For throughput-sensitive or agentic workloads, Flash wins. For coding-specific or latency-sensitive interactive applications, Claude Sonnet 4.6 remains ahead.
When is Gemini 3.5 Pro launching publicly?
Google announced Gemini 3.5 Pro at Google I/O on May 19, 2026, and Sundar Pichai promised a June 2026 launch. As of June 19, 2026, it is in limited Vertex AI preview with no confirmed public GA date. Expected specs include a 2 million token context window and Deep Think reasoning. Expected pricing: approximately $15/M input, $60/M output.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
