AI Tools
MiniMax M3 vs GPT-5.5: The Open-Weight Chinese AI That Just Outscored OpenAI on Coding — at 10% of the Price

One week after GPT-5.5 became the default "best coding model" answer on every leaderboard, a Chinese startup posted a model that beat it on SWE-Bench Pro — the most widely cited software engineering benchmark — and priced it at roughly one-eighth the cost. MiniMax M3 launched on June 1, 2026, and the numbers have been circulating ever since, prompting a real question: is this the moment open-weight Chinese AI closes the gap with Western frontier labs?
Key takeaways: - MiniMax M3 scored 59.0% on SWE-Bench Pro vs GPT-5.5's 58.6%, the first time an open-weight model has matched or exceeded OpenAI's flagship on this benchmark - M3 is priced at $0.60 per million input tokens vs GPT-5.5's $5 — roughly 8 to 12 times cheaper per token - M3 supports up to 1 million tokens of context, enabled by MiniMax's proprietary Sparse Attention (MSA) architecture - GPT-5.5 still leads on Terminal-Bench 2.1 (82.7% vs M3's 66.0%), the benchmark that tests autonomous multi-step terminal workflows - M3 benchmarks are vendor-reported and not yet independently verified; open weights had not shipped at the time of publication
What Is MiniMax M3, and Why Does It Matter?
MiniMax — formally Shanghai Hixi Technology — has spent the past two years in the shadow of more prominent Chinese AI labs. DeepSeek got the headlines. Kimi got the long-context record. MiniMax quietly developed its own architecture and waited for the right moment to surface.
M3 is that moment. It combines frontier-level coding performance, a 1-million-token context window, and native multimodal input — text, images, and video — in a single architecture. The multimodal piece matters more than it might sound. For agentic workflows where you are feeding screenshots, error logs, diagrams, and source code to the same model in a single session, a unified architecture removes the friction of switching between specialized models.
The architecture behind M3 is called MSA (MiniMax Sparse Attention). MiniMax claims it reduces per-token compute at 1M context to one-twentieth of their prior generation, with prefill speeds more than 9 times faster and decoding more than 15 times faster. If independent verification confirms those numbers, it would explain how M3 can run a 1-million-token context window at $0.60 per million input tokens and still operate a viable business.
How Do the Benchmarks Compare?
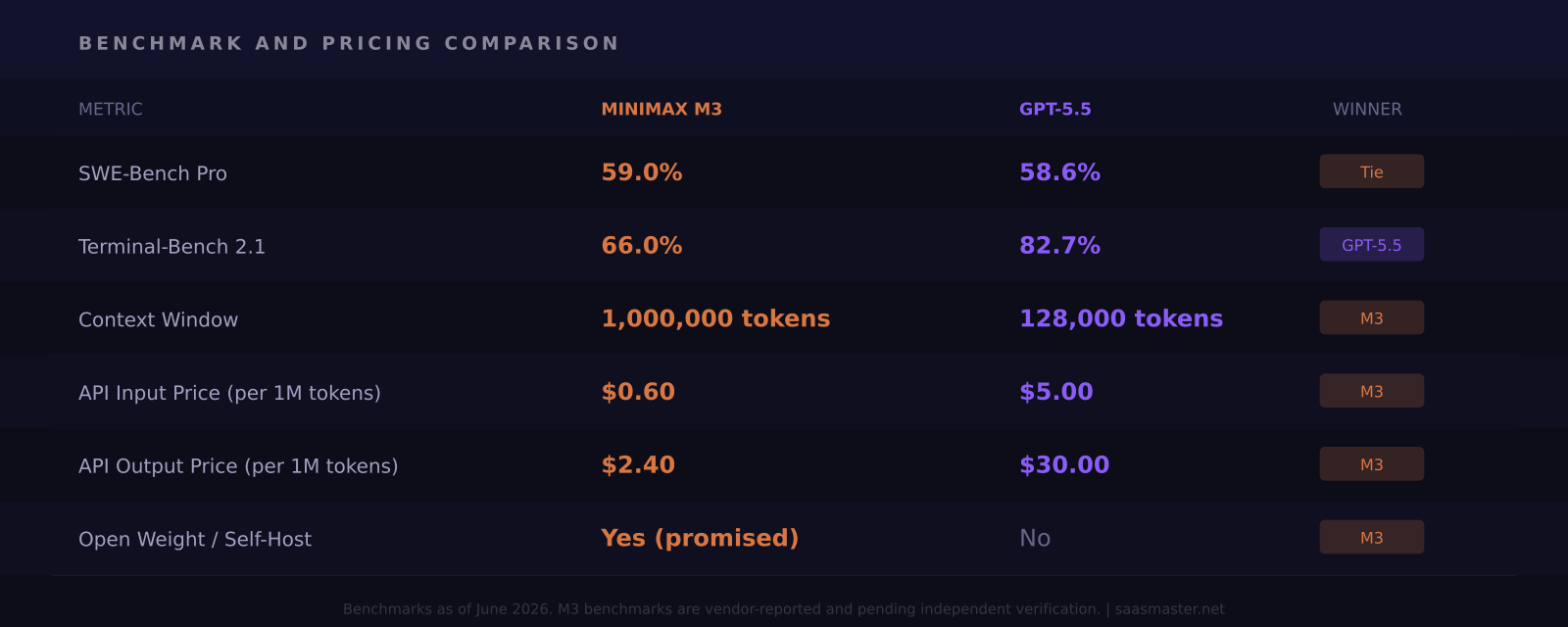
SWE-Bench Pro is the benchmark that matters most for this comparison. It tests how well a model can resolve real GitHub issues — messy, ambiguous, poorly documented tickets that reflect actual software engineering work rather than contrived exam questions.
MiniMax M3 scores 59.0% on SWE-Bench Pro. GPT-5.5 scores 58.6%. In practical terms, this is a tie — 0.4 points falls well within typical re-run variance — but the symbolic significance is real. This is the first time an open-weight model has posted a number at least equal to OpenAI's flagship on a major agentic coding test.
The story on Terminal-Bench 2.1 is different. Terminal-Bench evaluates autonomous multi-step terminal workflows: navigating codebases, running build systems, handling failed commands, recovering gracefully from unexpected output. GPT-5.5 scores 82.7% on this test; M3 scores 66.0%. That is not a marginal gap. For teams building agentic pipelines that run code autonomously with limited human supervision, GPT-5.5 holds a real advantage here.
One caveat worth keeping prominent: MiniMax's benchmark numbers are self-reported. The company promised a technical report and Hugging Face release within 10 days of the June 1 launch. GPT-5.5's scores appear on Artificial Analysis and have been cross-checked by independent evaluators. Until M3's numbers get the same treatment, the appropriate posture is cautious interest, not immediate migration.
Which Is Cheaper: MiniMax M3 or GPT-5.5?
This is where the comparison becomes genuinely interesting for anyone running AI workloads at any real volume.
GPT-5.5 through the OpenAI API costs $5 per million input tokens and $30 per million output tokens. MiniMax M3 launched on OpenRouter at $0.60 input and $2.40 output, with a promotional discount at launch bringing those to $0.30 and $1.20 respectively.
At standard pricing, M3 is approximately 8 times cheaper on input and 12 times cheaper on output. A coding agent that processes 100 million tokens per month would cost around $500 through M3 versus roughly $5,000 through GPT-5.5 — assuming similar output ratios. That is the kind of arithmetic that changes architecture decisions at the team level, not just the individual developer level.
What Does Each Model Do Better?
M3 is strongest for tasks that need long context and benefit from open-weight availability. Processing entire large codebases, reasoning over multi-thousand-file projects, handling mixed media input — these are the scenarios M3 was designed around. The open-weight promise (once weights arrive) also matters for organizations where data cannot leave their own infrastructure.
GPT-5.5 is stronger on autonomous terminal workflows, where the Terminal-Bench gap is too large to dismiss. It also benefits from a mature ecosystem: native Codex CLI integration, OpenAI's function calling infrastructure, and benchmark scores that have been stress-tested by the broader developer community over months. When you are building pipelines that need to run reliably at 3am without supervision, GPT-5.5's track record is a legitimate argument.
For most developers today, the decision is probably not binary. Running M3 for context-heavy tasks where you can review output, and GPT-5.5 for fully autonomous agentic workflows, is a reasonable split as the M3 ecosystem matures.
Is M3 Worth Trying Right Now?
My honest take: I would not replace GPT-5.5 with M3 for production agentic workflows today. The benchmarks are unverified, the open weights had not shipped, and the Terminal-Bench gap is real.
What I would do is put M3 on the evaluation list for the next 30 days. If the technical report holds up and independent scores confirm the SWE-Bench numbers, M3 becomes one of the most interesting cost-to-performance stories in AI infrastructure since DeepSeek V3 showed up in late 2024. A model that costs 10 times less and performs within noise on the benchmark you care most about is not a curiosity — it is a business case.
Frequently Asked Questions
Is MiniMax M3 actually better than GPT-5.5 at coding?
On SWE-Bench Pro the scores are essentially tied (59.0% vs 58.6%). GPT-5.5 leads clearly on Terminal-Bench (82.7% vs 66.0%), which tests autonomous multi-step terminal work. The honest answer: they are competitive on single-task coding, with GPT-5.5 ahead on autonomous agentic workflows.
When will MiniMax M3 open weights be available?
MiniMax promised to release M3 weights to Hugging Face and GitHub within 10 days of the June 1, 2026 launch. Independent benchmark reproduction is expected to follow shortly after weight release.
Why is MiniMax M3 so much cheaper than GPT-5.5?
The MSA architecture MiniMax developed reduces per-token compute significantly at long context lengths. Combined with MiniMax's operating cost structure in China and a deliberate pricing strategy to gain adoption, the result is API pricing that is 8 to 12 times lower than GPT-5.5 for equivalent token volumes.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master