AI Tools
Kimi K2.7 Code vs DeepSeek V4: The Open-Source Coding AI Showdown (2026)

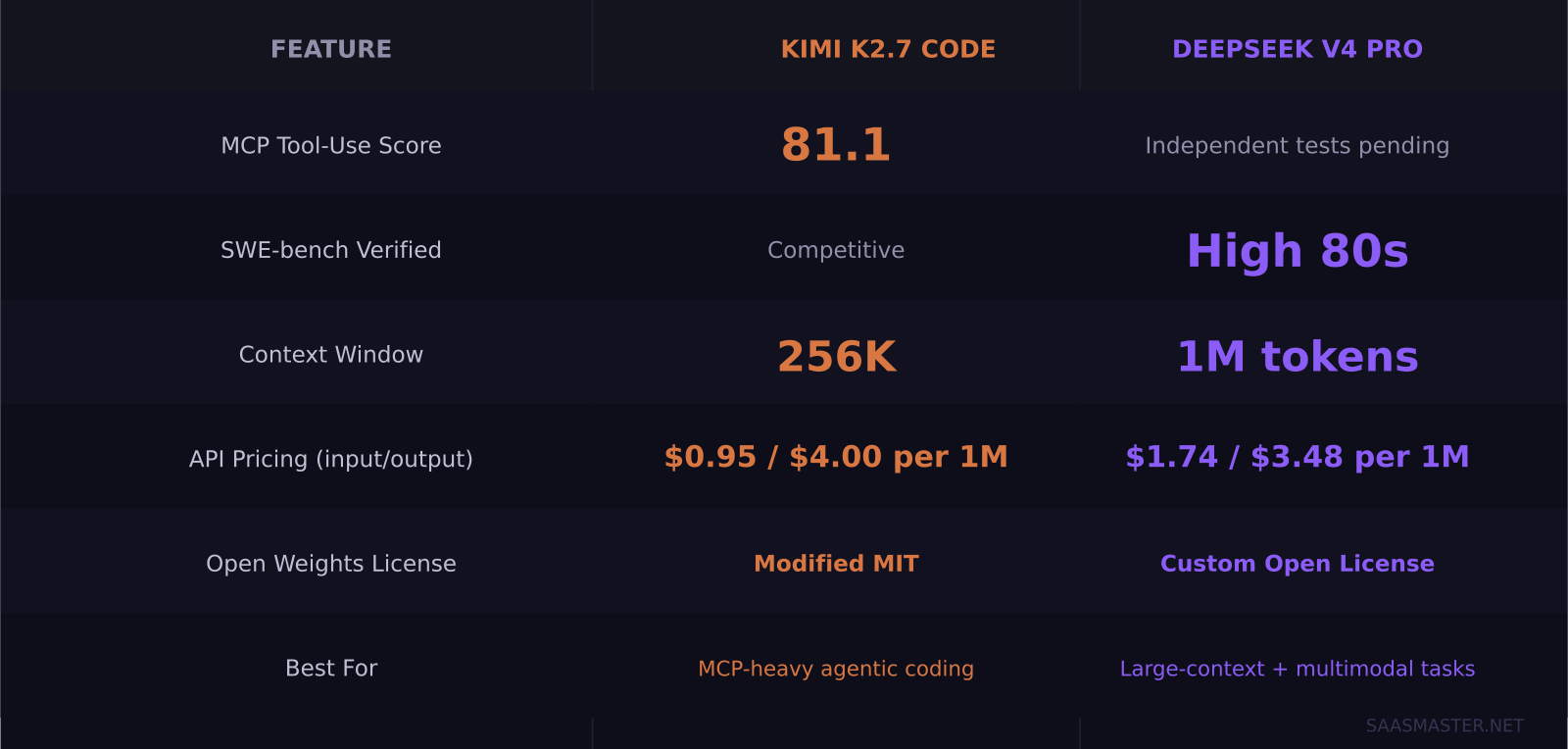
Kimi K2.7 Code scored 81.1 on MCP Mark Verified when Moonshot AI released it on June 12, 2026 — beating Claude Opus 4.8's 76.4 on the same benchmark. For an open-weights model available under a Modified MIT license, that is a significant result. DeepSeek V4, released two months earlier on April 24, continues to post SWE-bench Verified scores in the high 80s and offers a 1 million token context window that no closed model can match at its price point. If you want the best open-source coding AI right now and want real options beyond OpenAI and Anthropic, these two are the ones worth seriously evaluating in mid-2026.
Key takeaways
- Kimi K2.7 Code (June 12) beats Claude Opus 4.8 on MCP tool-use with 81.1 vs 76.4 on MCP Mark Verified
- DeepSeek V4 Pro leads on context window (1M tokens vs 256K) and SWE-bench Verified scores in the high 80s
- Kimi K2.7 is priced at $0.95/$4.00 per 1M tokens; DeepSeek V4 Pro at $1.74/$3.48 — V4-Flash drops to $0.14/$0.28
- Both are open-weights and can be self-hosted, fine-tuned, or used commercially
- Pick K2.7 for MCP-heavy agentic stacks; pick V4 for large-context tasks, multimodal coding, or cost-sensitive pipelines
What is Kimi K2.7 Code?
Kimi K2.7 Code is a 1 trillion parameter Mixture-of-Experts model released by Moonshot AI on June 12, 2026 under a Modified MIT license. Only 32 billion parameters are active per forward pass, which keeps inference viable on manageable hardware. You can self-host, fine-tune, and build commercial products on top of it without licensing restrictions.
The model's standout claim is MCP (Model Context Protocol) tool use. On MCP Mark Verified — a benchmark that tests real tool calls against live servers including Notion, GitHub, Postgres, Filesystem, and Playwright — K2.7 Code scores 81.1. That compares to Claude Opus 4.8's 76.4 on the same test. The gap matters for agentic coding workflows where the model needs to chain tool calls across a long task: read a file, run tests, edit code, commit changes, then update documentation without losing context or dropping steps.
The model uses what Moonshot calls an "always-thinking" design — it reasons internally before every response rather than requiring an explicit reasoning mode toggle. The upside is better accuracy on complex multi-step problems. The tradeoff is that reasoning tokens cost money at $4.00 per million output tokens. Compared to K2.6, K2.7 reduces thinking token usage by about 30%, which translates to meaningfully lower effective cost per completed task even though the sticker price is the same.
Coding benchmark gains over K2.6 are substantial: +21.8% on Kimi Code Bench v2 (62.0 vs 50.9), +11.0% on Program Bench, and +31.5% on MLS Bench Lite. These are Moonshot's own benchmarks and independent verification is still accumulating, but the direction is consistent.
What is DeepSeek V4?
DeepSeek V4 went live on April 24, 2026, as the latest from the Hangzhou-based lab that made headlines with DeepSeek-R1 in early 2025. V4 comes in two variants: V4-Flash at $0.14/$0.28 per 1M tokens and V4-Pro at $1.74/$3.48. The Pro version adds multimodal input and the full 1 million token context window.
On SWE-bench Verified, DeepSeek V4 posts scores in the high 80s. For reference, the benchmark's upper range separates frontier models from everything else — GPT-4o scored around 49% at launch. The high-80s range puts V4 Pro among the top coding models available, open or closed, for single-shot code problem solving.
The 1 million token context window is V4 Pro's strongest practical differentiator. For refactoring tasks, large codebase migrations, or any workflow that requires ingesting an entire repository before making changes, 1M tokens is a genuinely different capability than 256K. Smaller-context models handle these tasks by chunking and lose coherence across distant dependencies; V4 Pro does not have that problem.
DeepSeek V4-Flash at $0.14 input / $0.28 output is the cheapest serious option in this comparison by a wide margin. For high-volume automated code reviews, test generation, or documentation pipelines, the cost difference against V4-Pro or K2.7 is significant at scale.
Head-to-head: benchmarks and specs
The benchmark picture reveals two models optimized for different workflows rather than a clean winner. K2.7 Code leads on agentic, real-world tool use. V4 leads on classic single-shot code generation benchmarks and raw context capacity.
MCP tool use is emerging as the most relevant benchmark for agentic coding systems — it tests whether a model can complete an autonomous coding task using external tools, not whether it can answer a coding question in isolation. K2.7's 81.1 gives it a meaningful edge heading into the second half of 2026 as MCP adoption continues to expand. Independent V4 MCP scores are expected as more teams publish evaluations.
SWE-bench Verified tests a different skill: given a real GitHub issue, can the model produce a correct fix in a single pass? DeepSeek's high-80s score here is strong and reflects genuine code generation quality, not just tool-chaining ability.
Which is cheaper?
At standard API rates, Kimi K2.7 Code costs $0.95 per million input tokens and $4.00 per million output tokens. DeepSeek V4 Pro costs $1.74 input and $3.48 output. K2.7 is cheaper on input; V4 is cheaper on output. For most agentic coding workloads, output tokens outnumber input tokens significantly, which means V4 Pro edges ahead on raw cost for output-heavy tasks.
DeepSeek V4-Flash at $0.14/$0.28 is the clear winner if your use case can tolerate slightly lower quality benchmarks in exchange for dramatically lower cost. At that price point, DeepSeek is genuinely competing with budget API tiers that previously had no serious open-source option.
Self-hosting is available for both — and matters for privacy-sensitive or air-gapped environments where sending code to any external API is not acceptable. Running a 1T MoE model like K2.7 requires substantial GPU hardware, but quantized versions bring it within reach of setups that cannot afford a cluster of A100s.
Which should you use?
Pick Kimi K2.7 Code if your workflow is MCP-heavy. If you are running agentic coding sessions that involve Notion, GitHub, databases, custom MCP servers, or any setup where the model needs to chain tool calls reliably across a long session, K2.7's leading benchmark numbers translate to fewer dropped steps and more complete task execution. The 256K context window covers most single-repository projects.
Pick DeepSeek V4 Pro if you need to ingest large codebases (1M context matters here), if you are doing multimodal tasks that involve reading screenshots or diagrams alongside code, or if SWE-bench-style single-shot generation quality is your primary benchmark. V4-Flash is the right call for cost-sensitive, high-volume pipelines where you need proven quality at the lowest available price.
From my own evaluation of models for software walkthrough and tutorial content — the kind where you feed a model a GitHub repository and ask it to document a feature — K2.7 Code handles multi-step agentic research loops better. DeepSeek V4 Pro tends to produce stronger output when the task is generate-once with a large context window.
Where to access each model
Kimi K2.7 Code is available through the Kimi API platform at platform.kimi.ai, via OpenRouter, and through the Kimi Code CLI for the full agentic experience with native MCP integration. Weights are public on Hugging Face under the Modified MIT license.
DeepSeek V4 is available at api.deepseek.com and on OpenRouter. Weights are public on Hugging Face. Third-party providers also offer DeepSeek API access at rates that can undercut even the official pricing for certain configurations.
Frequently asked questions
Is Kimi K2.7 Code better than Claude Opus 4.8 for coding?
On MCP tool-use benchmarks specifically, yes — K2.7 Code scores 81.1 versus Claude Opus 4.8's 76.4 on MCP Mark Verified. On broader reasoning, output quality, and instruction-following tasks, Opus 4.8 still holds a meaningful edge. K2.7 is the better choice for agentic workflows that depend heavily on MCP tool chains; Opus 4.8 is stronger for complex reasoning, nuanced output, and tasks where quality matters more than tool-use benchmark scores.
Can I run either model locally without a GPU cluster?
Both publish open weights. Running K2.7's full 1T MoE model requires substantial hardware — multiple A100 80GB GPUs at minimum. Quantized versions are available that run on less demanding setups at some quality cost. DeepSeek V4-Flash's effective active parameter count is more practical for local deployment. If running locally is a hard requirement, DeepSeek V4-Flash in a quantized format is the most accessible starting point.
Are Chinese open-source AI models safe for enterprise use?
Both Kimi K2.7 Code and DeepSeek V4 publish open weights, which means you can audit the model and self-host it without sending data to any external server. That addresses the data privacy concern directly. The license terms — Modified MIT for K2.7, custom open license for V4 — both permit commercial use. For regulated industries or sensitive codebases, self-hosting the open weights is the recommended approach regardless of which model you choose.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master