AI Tools
DeepSeek V4 Pro vs Qwen 3.7 Max: Which Chinese AI Frontier Model Should You Build With in 2026?

Six times cheaper, near-identical coding scores, MIT licensed with public weights — versus closed-source, stronger on agentic tasks, and a $7.50 per million output tokens price tag. That gap between DeepSeek V4 Pro and Qwen 3.7 Max is one of the most consequential API decisions a SaaS builder can make right now, and most comparisons bury the number that matters most. Here's the complete breakdown.
Key Takeaways
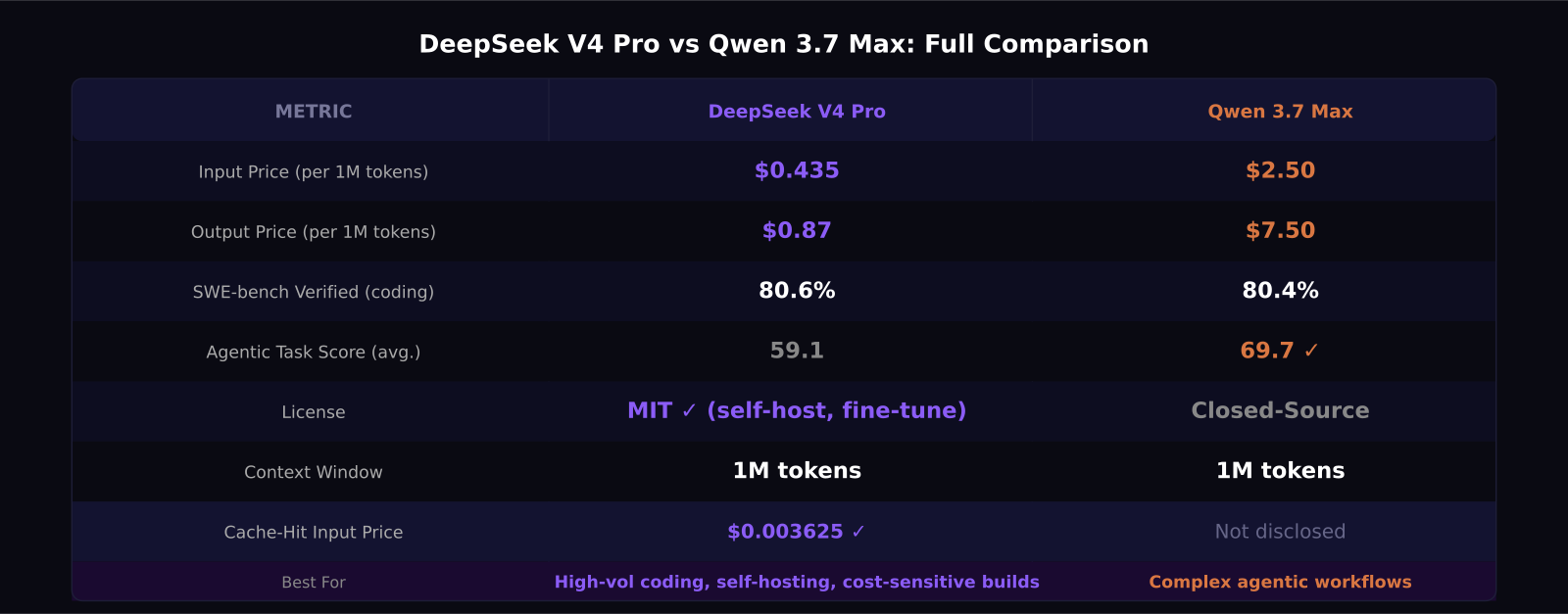
- DeepSeek V4 Pro costs $0.435 per million input tokens and $0.87 per million output tokens. Qwen 3.7 Max costs $2.50 and $7.50 — roughly 6x more expensive at output.
- On coding, they are essentially tied: DeepSeek V4 Pro scores 80.6% on SWE-bench Verified, Qwen 3.7 Max scores 80.4%.
- For agentic multi-step tasks, Qwen 3.7 Max holds a real edge: 69.7 average versus DeepSeek V4 Pro's 59.1.
- DeepSeek V4 Pro ships under MIT license with full public weights — you can self-host, fine-tune, and run it on your own infrastructure.
- Qwen 3.7 Max is closed-source and API-only. If Alibaba changes terms, you have no alternative path.
Who Made These Models and Why It Matters
DeepSeek V4 Pro is the flagship from DeepSeek, the Hangzhou-based AI lab that shook the frontier model market when its R1 proved you didn't need a $100-million training run to match GPT-4. V4 Pro is a Mixture-of-Experts architecture with 1.6 trillion total parameters — only 49 billion are active at any given inference — running on a 1 million token context window. The current API pricing became permanent on May 22, 2026, after DeepSeek made a 75% discount the standard list price rather than a promotional rate.
Qwen 3.7 Max comes from Alibaba Cloud's Tongyi Qwen team. It's the latest in the Qwen series and is positioned as the enterprise-grade option in the Chinese AI stack, with particularly strong agentic and complex multi-step reasoning capabilities. The closed-source, API-only approach reflects a different strategy: Alibaba is building an ecosystem dependency rather than maximizing open-weight adoption.
The "who" matters here because the governance model shapes what you can actually do with each model in production.
Which Is Better on Coding Benchmarks?
If raw coding performance is your primary decision factor, the answer is: buy the cheaper one.
On SWE-bench Verified — the benchmark that measures real-world software engineering tasks rather than academic puzzles — DeepSeek V4 Pro scores 80.6% and Qwen 3.7 Max scores 80.4%. That is a 0.2-point difference in favor of DeepSeek, which is statistically indistinguishable from a tie. MiniMax M3, covered separately on this blog, also sits at 80.5%, making this effectively a three-way tie at the top of the open-weight coding leaderboard.
DeepSeek's historical advantage in mathematical reasoning also holds in V4 Pro — the R-series reasoning variants show a 7-point edge on pure math benchmarks over comparable Qwen models. For AI coding assistants, code generation features inside SaaS products, or any workflow that processes high volumes of code: V4 Pro delivers equivalent output quality to Qwen 3.7 Max at 6x lower API cost.
Which Is Better for AI Agents and Complex Multi-Step Tasks?
This is where the comparison shifts and Qwen earns its price premium — for some workflows.
Qwen 3.7 Max averages 69.7 on agentic task benchmarks. DeepSeek V4 Pro averages 59.1. That 10-point gap is meaningful for workflows that chain multiple tool calls, handle complex autonomous planning, or require the model to operate over long sequences without human guidance. Qwen 3.7 Max also holds the top position on Terminal-Bench 2.0 as of May 2026, with a 2-point lead over V4 Pro.
For SaaS teams building multi-step agent features — automated customer onboarding, complex support routing, or agentic product workflows — Qwen 3.7 Max is the stronger performer on these tasks. The question is whether that performance gap justifies the price multiplier for your actual workload.
Here's what the math looks like at scale: at 1,000 sessions where each session consumes 500,000 output tokens, DeepSeek V4 Pro costs $435 total. Qwen 3.7 Max costs $3,750 for the same volume. That $3,300 difference per thousand sessions is either trivial or critical depending on your margins and user volume.
Pricing Breakdown: Every Number That Matters
DeepSeek V4 Pro on the official API: $0.435 per million input tokens, $0.87 per million output tokens. Cache-hit input — which is the price you pay when the model reads a repeated system prompt or shared context — drops to $0.003625 per million tokens. For production agent systems that send the same large system prompt with every call, the real per-token cost is dramatically lower than the headline number.
DeepSeek V4 Flash, the lighter variant in the same family: $0.14 per million input tokens and $0.28 output. Uses 284 billion total parameters with 13 billion active. Good for high-volume simpler tasks where V4 Pro is overkill.
Qwen 3.7 Max: $2.50 per million input and $7.50 per million output. No Flash-tier equivalent at comparable capability has been released.
The cache pricing on V4 Pro is worth underscoring for anyone building production agent systems. Most agents repeatedly send similar context windows — large system prompts, tool definitions, shared instructions. At $0.003625 per million cached input tokens, the effective cost of running V4 Pro in production is substantially lower than even the headline $0.435 suggests.
Open-Source vs Closed: What Actually Matters for Your Build
This is the dimension that most comparisons undersell, and it is especially important for SaaS companies building AI features into products.
DeepSeek V4 Pro ships under the MIT license with full public weights. In practice that means: you can self-host on your own GPU infrastructure and pay zero per-token after compute costs. You can fine-tune the model on your own proprietary data to specialize it for your product domain. You are not dependent on an external API's uptime, rate limits, pricing changes, or geopolitical stability.
Qwen 3.7 Max is closed-source and API-only. Your access to the model's capabilities is entirely at Alibaba's discretion. You cannot inspect, modify, or move the weights. Fine-tuning is limited to what Alibaba exposes through their API. If Alibaba changes pricing, restricts access, or deprecates the model, you have no mitigation path.
For a SaaS company building a core product feature on top of an AI model, the open-weight option is a long-term strategic advantage. DeepSeek's pricing has only moved downward since the model launched — and self-hosting provides a further hedge if that ever reverses.
Which Should You Use?
For most SaaS builders in 2026, DeepSeek V4 Pro is the right starting point. The coding quality is equivalent to Qwen 3.7 Max, the price is 6x lower, the MIT license gives you self-hosting optionality, and the 10x to 13x cost advantage over GPT-5.5 and Claude Opus means you can serve meaningfully more user requests within the same AI budget.
The exception is clear: if your product's core value comes from multi-step autonomous agent workflows, and that 10-point agentic performance gap between Qwen 3.7 Max (69.7) and DeepSeek V4 Pro (59.1) would noticeably affect user experience, Qwen's price premium may be worth it. But I would run an evaluation on your specific agent tasks before committing — benchmark gaps often look smaller in production than they do in research settings.
Default to DeepSeek V4 Pro if cost and ownership matter. Choose Qwen 3.7 Max if you need peak agentic performance and can absorb the per-token price.
Frequently Asked Questions
Is DeepSeek V4 Pro safe to use in a commercial SaaS product?
Yes. DeepSeek V4 Pro is released under the MIT license, which explicitly permits commercial use, redistribution, and modification. The weights are publicly available. As with any AI model, you should evaluate outputs for accuracy and implement appropriate safety guardrails for your product context.
Can I fine-tune DeepSeek V4 Pro on my own data?
Yes — the MIT license and public weights allow fine-tuning. You will need GPU infrastructure capable of handling MoE model fine-tuning, but the active parameter count of 49B makes this more manageable than the total parameter count suggests. Several cloud providers offer hosted fine-tuning services for large open-weight models if running your own infrastructure is not practical.
How does DeepSeek V4 Pro compare to Claude Opus 4.8 on coding tasks?
DeepSeek V4 Pro scores 80.6% on SWE-bench Verified, placing it in the same tier as Claude Opus 4.8 on software engineering benchmarks. The major difference is API cost: V4 Pro at $0.87 per million output tokens versus Claude Opus at significantly higher rates. For high-volume coding workloads where frontier-level performance is required, DeepSeek V4 Pro is the cost-effective alternative.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
