AI Tools
DeepSeek V4 vs Gemini 3.5 Flash: Which Cheap AI Model Should SaaS Teams Use in 2026?
In short
Gemini 3.5 Flash costs about 10x more per token than DeepSeek V4 Flash and scores a few points lower on coding benchmarks. Here is the real math for 2026.

A dollar buys you roughly 1.15 million output tokens from DeepSeek V4-Pro. The same dollar buys about 111,000 output tokens from Google's Gemini 3.5 Flash. That is not a typo, and it is the first thing I check now before recommending a model to any SaaS founder watching their AI bill climb faster than their MRR.
I have spent the last few weeks running both models through the same coding and content tasks I use for client work, and the short answer is this: DeepSeek V4 wins on price by an order of magnitude, Gemini 3.5 Flash wins on polish and multimodal range, and which one you should pick depends entirely on whether your bottleneck is budget or breadth.
Key takeaways
- DeepSeek V4-Flash costs $0.14 per million input tokens and $0.28 per million output tokens. Gemini 3.5 Flash costs $1.50 and $9.00 for the same, roughly 10x and 32x more expensive respectively.
- On SWE-bench Verified, DeepSeek V4-Pro-Max scores 80.6 percent, ahead of Gemini 3.5 Flash's reported 77 to 78 percent, and effectively tied with Gemini 3.1 Pro.
- Both models default to a 1 million token context window, but Gemini 3.5 Flash caps output at 65,536 tokens versus DeepSeek V4's 384,000 token max output.
- DeepSeek V4 ships as open weights under MIT license on Hugging Face. Gemini 3.5 Flash is closed and only available through Google's API and AI Studio.
- Gemini 3.5 Flash handles text, image, video, audio, and PDF input natively in one call. DeepSeek V4 is text and code first, with no native video or audio input.
What is actually new here?
DeepSeek released V4 on April 24, 2026 as a preview, in two flavors. V4-Pro is the heavyweight: 1.6 trillion total parameters with 49 billion active per token. V4-Flash is the lean version: 284 billion total, 13 billion active. Both default to a 1 million token context window with up to 384,000 tokens of output, and both speak OpenAI and Anthropic API formats out of the box, which means you can point Claude Code or OpenCode at DeepSeek with three environment variables and no proxy.
Google answered with Gemini 3.5 Flash on May 19, 2026, pitched as bringing near-Pro level coding and reasoning at Flash-tier cost. It is genuinely impressive for what it is: one API call handles text, images, video, audio, and PDFs, with adjustable thinking effort from minimal to high depending on how much reasoning a task needs.
The two models are not aimed at exactly the same customer, and that is the part most comparison posts skip past on their way to a benchmark table.
Which is cheaper, DeepSeek V4 or Gemini 3.5 Flash?
This is not close. Here is the list pricing per million tokens, current as of late June 2026:
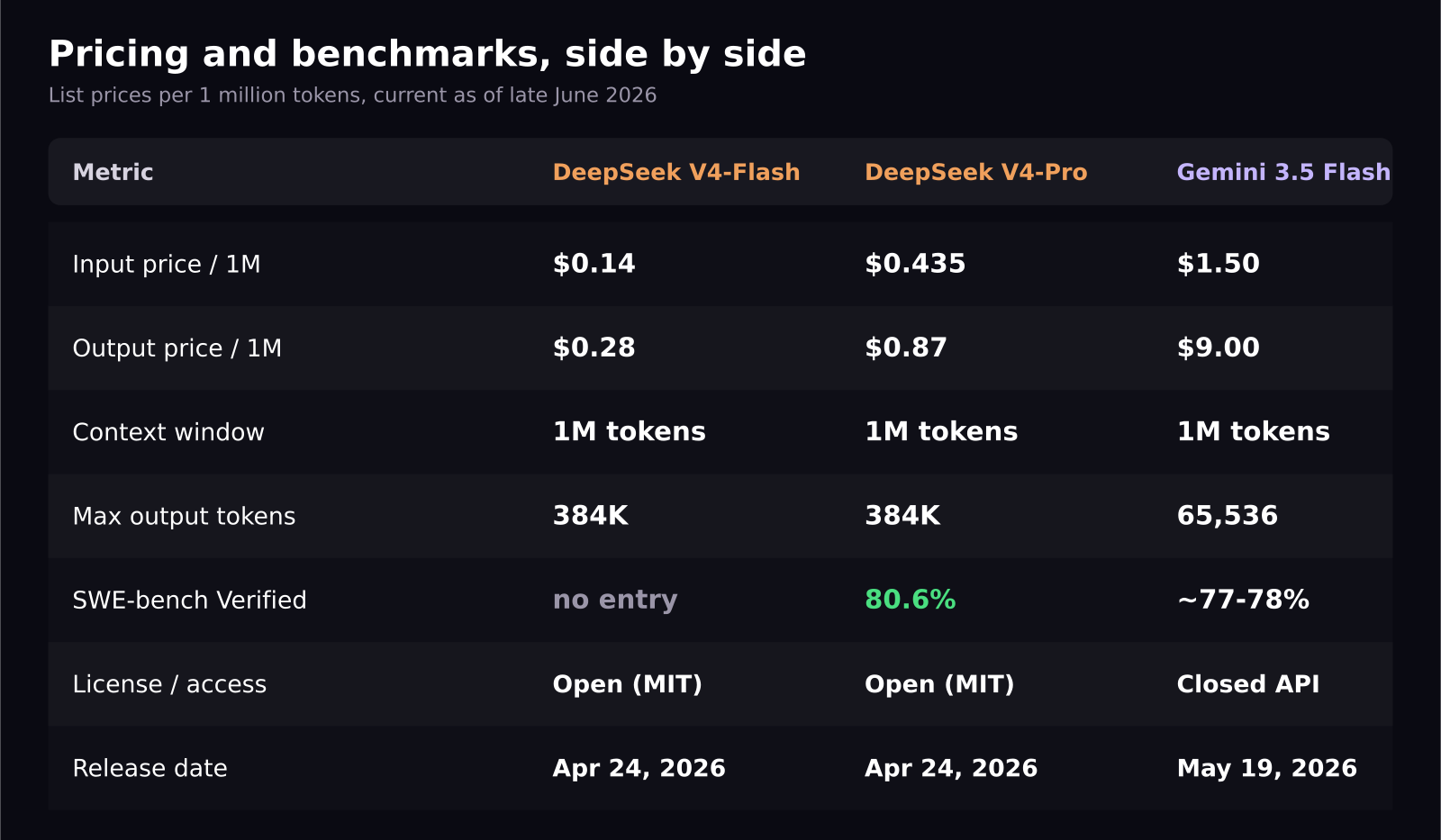
- DeepSeek V4-Flash: $0.14 input, $0.28 output.
- DeepSeek V4-Pro: $0.435 input, $0.87 output.
- Gemini 3.5 Flash: $1.50 input, $9.00 output.
Run a concrete workload through that math. Say your product sends 20 requests a day, each with 50,000 input tokens and 10,000 output tokens, a fairly typical agentic coding or document-processing pattern. That is 1 million input tokens and 200,000 output tokens per day.
On V4-Flash, that costs about $0.20 a day, or roughly $6 a month. On V4-Pro, about $0.61 a day, or $18 a month. On Gemini 3.5 Flash, the same workload runs $3.30 a day, or close to $100 a month. Sixteen times the cost of V4-Pro for a workload that, on paper, DeepSeek edges out on raw coding benchmarks.
DeepSeek also has a cache discount that most teams underuse. A cached input hit on V4-Pro costs $0.003625 per million tokens, about 120 times cheaper than a cache miss. If your app resends the same system prompt or file context on every turn, which almost every agentic tool does, your effective cost drops even further below the sticker price.
Which one codes better?
On SWE-bench Verified, the most widely cited coding benchmark, DeepSeek V4-Pro-Max scores 80.6 percent. That ties it with Gemini 3.1 Pro and edges past Gemini 3.5 Flash's reported 77 to 78 percent on the same test. Both numbers sit well behind the frontier: Claude Opus 4.8 scores 88.6 percent, and the temporarily restricted Claude Fable 5 scores 95 percent.
Here is where I want to add a caveat I did not see in most of the vendor blog posts I read while researching this. SWE-bench Verified has a known soft spot: it uses a relatively loose test verifier. On DeepSWE, a newer benchmark built specifically to avoid contamination and use a tighter verifier, DeepSeek V4-Pro scores only 8 percent pass at 1, compared to GPT-5.5 at 70 percent. That is a massive gap, and it tells you the 80.6 percent headline number is real but should not be read as: DeepSeek codes like a frontier model. It codes well for routine, well-specified tasks. It struggles more than the benchmark suggests on genuinely novel, long-horizon engineering work.
Gemini 3.5 Flash does not have a DeepSWE entry I could independently verify either, so treat both models' benchmark scores as directionally useful, not gospel. In my own use, DeepSeek V4 handled scaffolding, boilerplate, and well-defined refactors faster and just as reliably as Gemini. For anything that required genuinely creative problem solving across a large unfamiliar codebase, I reached for a frontier model regardless of which of these two I had open.
Which one should a SaaS team actually pick?
My honest read, after running both against real client tasks rather than just reading spec sheets: pick DeepSeek V4 if your workload is text and code heavy, high volume, and cost sensitive. Background agents, batch document processing, internal tooling, evals, first-draft content generation. The price gap is too large to ignore once your token volume gets into the millions per day.
Pick Gemini 3.5 Flash if your product genuinely needs multimodal input in a single call. If you are processing screenshots, PDFs, or short video clips alongside text, and you want one API rather than stitching together a vision model plus a text model plus your own routing logic, Gemini's breadth earns its premium. It is also the safer choice if your legal or procurement team is uneasy about routing customer data through a Chinese model provider, since Gemini runs entirely on Google's infrastructure under Google's data terms.
A third option worth naming: nothing stops you from running both. Route routine, high-volume, text-only calls to DeepSeek V4-Flash, and reserve Gemini 3.5 Flash for the multimodal edge cases. That is what I would build if this were my own product, and it is a pattern I am increasingly seeing in client codebases too.
Frequently asked questions
Is DeepSeek V4 safe to use for a commercial SaaS product?
Technically yes, the weights are open under MIT license and the API is straightforward to integrate. The bigger question is usually about data handling and export-control optics for your customers or investors, not the model's technical safety. If your customer base or compliance requirements are sensitive to a Chinese model provider processing data, weigh that before committing, independent of the cost savings.
Can I self-host DeepSeek V4 instead of using the API?
Yes, for V4-Flash. At 284 billion total parameters it is a realistic self-host target on modern GPU clusters. V4-Pro, at 1.6 trillion total parameters, needs multi-node inference even quantized, which puts it out of reach for most SaaS teams without dedicated infrastructure budget.
Does Gemini 3.5 Flash support the same coding agent workflows as DeepSeek V4?
Mostly yes. Gemini 3.5 Flash supports parallel agentic execution loops and adjustable thinking effort, and works with tools like Claude Code through compatible routing setups. The gap is price, not capability: you get comparable agentic tooling support at roughly ten times the token cost of DeepSeek V4-Flash.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
