AI Tools
Grok 4.3 vs Claude Opus 4.8 vs GPT-5.5: Which Frontier AI Model Wins in 2026?

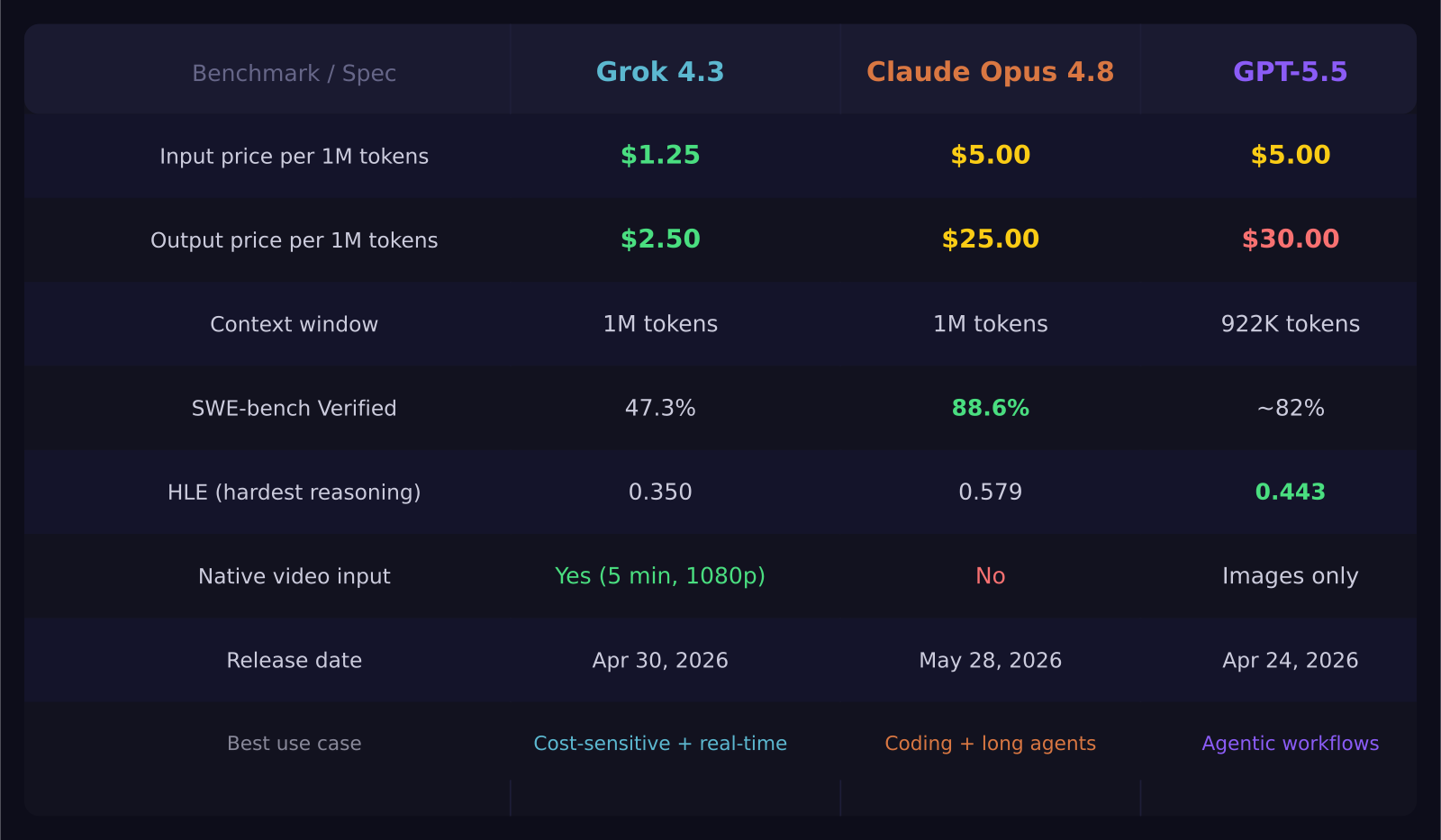
Grok 4.3 costs $1.25 per million input tokens and $2.50 per million output tokens. Claude Opus 4.8 costs $5 per million input tokens and $25 per million output. GPT-5.5 costs $5 per million input and $30 per million output. In June 2026, all three are frontier-class models that most developers will never genuinely push to their limits — which means the real question is not which one scores highest on benchmarks, but which one fits the work you are actually trying to do.
Key takeaways: - Grok 4.3 is the cheapest frontier model at $1.25 per million input tokens — 4x cheaper than Claude Opus 4.8 and GPT-5.5 - Claude Opus 4.8 leads on coding with SWE-bench Verified at 88.6% and USAMO 2026 math at 96.7% - GPT-5.5 leads on broad agentic workflows and multimodal tasks, scoring 84.9% on GDPval - Grok 4.3 is the only model here with native video input support (up to 5 minutes, 1080p) - Released May 28, 2026 alongside Anthropic's $65B Series H, Claude Opus 4.8 represents the high-watermark of the coding model category
What are these three models, exactly?
Grok 4.3 launched on April 30, 2026 from xAI, Elon Musk's AI company. It is a frontier reasoning model with a 1 million token context window, configurable reasoning effort levels (none, low, medium, high — default low), and a pricing structure designed to undercut every major competitor. It went live on Amazon Bedrock on June 15, 2026, roughly six weeks after the direct xAI API release. Its standout hardware capability is native video input — the first xAI model to support video natively, up to five minutes at 1080p in mp4, mov, or webm format.
Claude Opus 4.8 launched on May 28, 2026, the same day Anthropic announced its $65 billion Series H round at a $965 billion valuation. It is Anthropic's flagship coding and reasoning model, building on Opus 4.7 with a 27-percentage-point leap on USAMO 2026 math (from 69.3% to 96.7%) and a new dynamic workflows feature in Claude Code for tackling large-scale, multi-step software problems.
GPT-5.5 launched on April 24, 2026 from OpenAI. It is OpenAI's frontier professional model with a 922K input token context, designed for complex knowledge work, multimodal analysis, and agentic workflows. OpenAI positions it for enterprise tasks requiring high instruction-following reliability and deep reasoning across long documents.
Which is cheaper — and by how much?
The cost gap between Grok 4.3 and the other two is not marginal. At $1.25 per million input tokens, Grok 4.3 is 4x cheaper on input than both Claude Opus 4.8 and GPT-5.5. On output, Grok at $2.50 per million is 10x cheaper than Claude at $25 and 12x cheaper than GPT-5.5 at $30. For production applications passing millions of tokens per day, this pricing difference translates to thousands of dollars per month.
Where Grok's cost advantage narrows is in task complexity. If you need a model to complete a software engineering task in one or two model calls, Claude Opus 4.8's coding accuracy may save more in developer time than Grok saves in token cost. The right cost comparison is total cost to get a correct output, not just cost per token.
How do the benchmarks actually compare?
On coding — the most common professional use case for frontier models in 2026 — Claude Opus 4.8 leads clearly. Its SWE-bench Verified score of 88.6% outpaces Grok 4.3 (47.3% in the same benchmark comparison) by a wide margin. The Terminal-Bench 2.1 score of 74.6% and SWE-bench Pro score of 69.2% confirm that Opus 4.8 is the tool to reach for when the task is writing, debugging, or refactoring real-world code in complex repositories.
GPT-5.5 ranks second in the coding benchmark index among 317 models tracked by OpenRouter, and leads on agentic workflow tasks. Its GDPval score of 84.9% — a test of professional knowledge work across 44 occupations — is the highest in this comparison. OSWorld-Verified at 78.7% confirms it can operate real computer environments autonomously. If you are building agents that need to move across multiple tools, analyze data, and produce documents independently, GPT-5.5 is the current leader.
Grok 4.3 leads on multimodal and grounded tasks, averaging 78.1 versus 76.1 for Claude Opus 4.8 on that category. It records the lowest hallucination rate among frontier models in the Artificial Analysis comparison, ranks first on the Omniscience benchmark, and is the top performer on Vals AI Case Law and Corporate Finance benchmarks. For legal research, financial analysis, or any task requiring real-time data access via X, Grok 4.3 punches well above its price.
What makes each model unique?
Grok 4.3 has the only native video input among the three, supports configurable reasoning effort (which lets you dial down compute for faster cheap responses), and responds to real-time X queries in under 2 seconds. If your application involves recent news, live market data, or processing video content, Grok 4.3 covers use cases the other two cannot.
Claude Opus 4.8 has the best published benchmark suite in this comparison and the most reliable performance on multi-step tool use, browser agents (Online-Mind2Web at 84%), and surgical code patches. The dynamic workflows feature in Claude Code adds a new category of large-scale automated engineering work. It is also the most trusted model in enterprise legal and compliance workflows, where the first model to break 10% on the Legal Agent Benchmark all-pass standard is a meaningful credential.
GPT-5.5 has the highest instruction-following scores (IFBench at 0.759) and long-context reliability (0.743 at 922K tokens), which matters when you are processing entire codebases or legal document sets in a single pass. The integration with OpenAI's operator ecosystem and existing enterprise tooling makes it the lowest-friction choice for teams already built on the OpenAI stack.
Which should you use?
If you are building a production application that needs coding or code review at scale and cost matters, Grok 4.3 is the right default for most requests, with Claude Opus 4.8 called in for complex engineering tasks where accuracy justifies the higher cost.
If coding quality and agentic software development is the primary job, Claude Opus 4.8 is the current leader and the price premium is justified by fewer failed attempts.
If you are building broad professional agents — the kind that write documents, operate software, analyze data, and respond to complex instructions reliably over long sessions — GPT-5.5 is the current leader and worth the output cost.
Frequently asked questions
Can Grok 4.3 replace Claude Opus 4.8 for coding tasks?
For simple to medium-complexity coding tasks, yes. For complex multi-file engineering work where SWE-bench accuracy matters, Claude Opus 4.8 significantly outperforms Grok 4.3. The 4x cost advantage makes Grok worth trying first, but not at the expense of code quality in production.
Is GPT-5.5 worth the highest output cost of the three?
If your application involves broad professional agentic workflows requiring strong instruction-following across long sessions, the output cost is frequently offset by fewer correction rounds. For pure coding tasks, Claude Opus 4.8 delivers better benchmark performance at the same input cost.
Which model launched most recently?
Claude Opus 4.8 on May 28, 2026 is the most recent release in this comparison, followed by GPT-5.5 on April 24, 2026 and Grok 4.3 on April 30, 2026.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
