AI Tools
Grok 4.3 vs Claude Opus 4.8 vs MiniMax M3: Best AI Developer Model in 2026

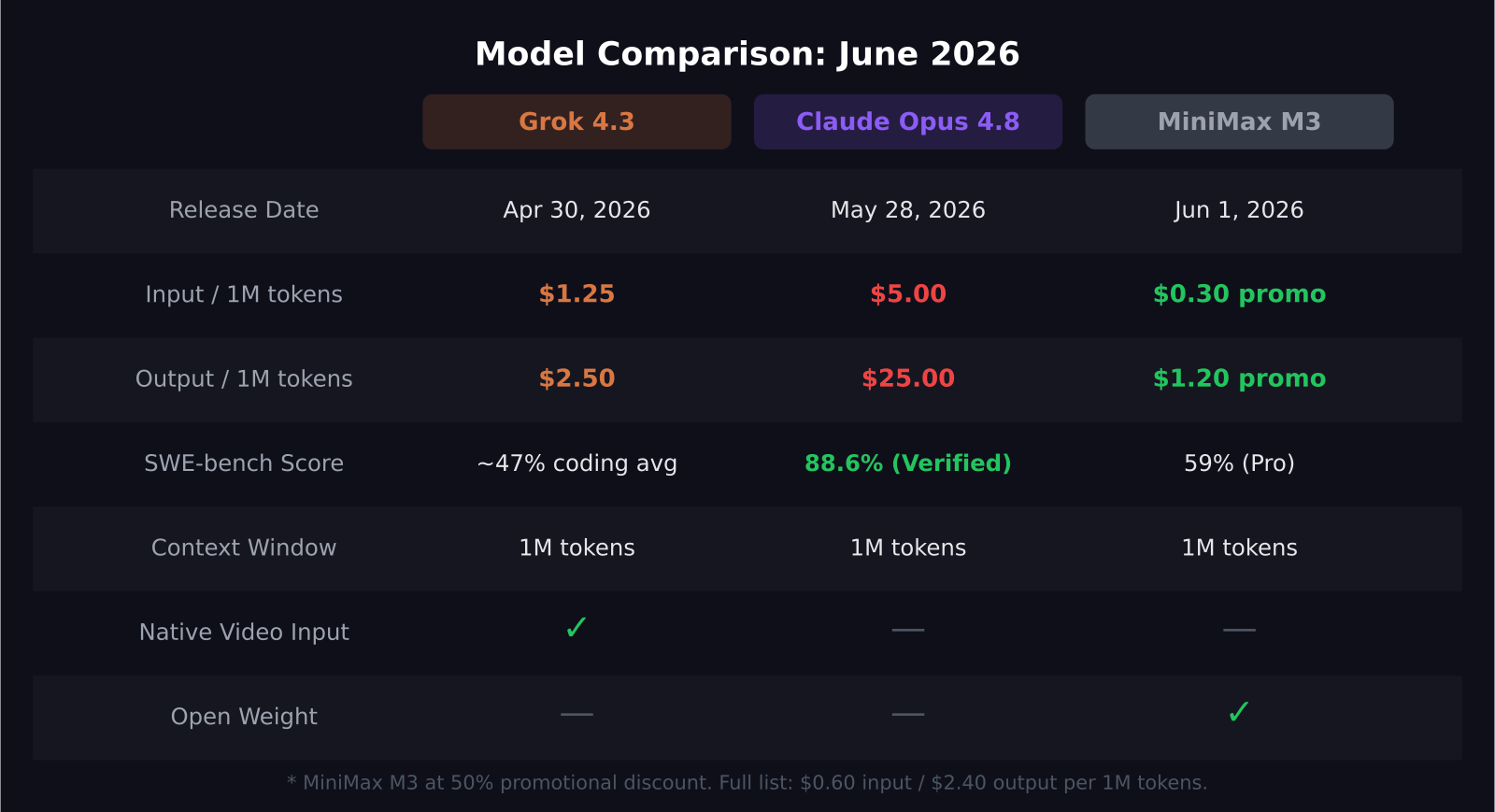
If you are choosing an AI model for SaaS development work in June 2026, three names keep coming up: Grok 4.3, Claude Opus 4.8, and MiniMax M3. Each launched within the last two months, and each represents a different philosophy about what frontier AI should cost and where it should excel. The short version: Claude Opus 4.8 is the most capable, MiniMax M3 is the best value, and Grok 4.3 sits in between — with one unique advantage neither competitor can match: native video input.
Key takeaways
- Claude Opus 4.8 leads aggregate benchmarks at 93 and SWE-bench Verified at 88.6%, but costs $5.00 per million input tokens
- Grok 4.3 launched via API on April 30, 2026 at $1.25 input / $2.50 output per million tokens — one-fourth of Claude's input cost
- MiniMax M3 (June 1, 2026) beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro with a score of 59%, at a promotional $0.30 per million input tokens
- All three support 1M token context windows, but MiniMax M3's MSA architecture makes it 9x faster at prefill at that scale
- Grok 4.3 is the only model of the three that accepts native video input up to five minutes at 1080p
What makes each model different?
Claude Opus 4.8 is Anthropic's current flagship, released May 28, 2026. It carries Anthropic's reputation for careful, controllable behavior and consistently posts the strongest numbers on multi-step coding, tool use, and agentic tasks. The 88.6% SWE-bench Verified score is among the best in the industry. On HLE — Humanity's Last Exam — it scores 57.9%. If you have relied on Claude before and valued its precision under pressure, Opus 4.8 is that pushed to its current ceiling.
Grok 4.3 is xAI's flagship as of its API release on April 30, 2026. Its defining feature for practical workflows is being the first major frontier model to accept native video — up to five minutes of mp4, mov, or webm at 1080p. It can transcribe speech, segment speakers, track objects, and reason about motion within video. On GPQA Diamond it scores 90.1%, reflecting genuine strength in hard science and reasoning tasks. The pricing is aggressive: $1.25 input / $2.50 output, about 38% cheaper on input than the previous Grok 4.20.
MiniMax M3 launched June 1, 2026 and is built on MiniMax Sparse Attention architecture, which cuts per-token compute at 1M context to one-twentieth of the prior generation — resulting in more than 9x faster prefill and 15x faster decoding at that scale. It is the first open-weight model to combine frontier coding capability, a 1M context window, and native multimodal input in a single package. Weights are releasing on Hugging Face within 10 days of launch, enabling self-hosting.
How do the benchmarks actually compare?
Claude Opus 4.8 scores 93 on the Artificial Analysis aggregate benchmark and 88.6% on SWE-bench Verified. On HLE it scores 57.9%. These are the best numbers in this group and among the best from any model as of late June 2026.
Grok 4.3 sits at 53 on the Artificial Analysis Intelligence Index. Its coding average runs around 47.3, but its GPQA Diamond score of 90.1% is genuinely competitive on science and math reasoning. The benchmark profile is that of a model optimized for broad capability and affordability rather than peak coding performance.
MiniMax M3 scores 59% on SWE-Bench Pro, 66% on Terminal-Bench 2.1, and 83.5 on BrowseComp. One caveat: some results were run on MiniMax's own infrastructure with agent scaffolding, and independent verification is still pending as of late June 2026. That said, the numbers are strong enough to take seriously — beating GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro is a meaningful claim.
Which model is cheapest to actually run at scale?
Claude Opus 4.8 costs $5.00 input / $25.00 output per million tokens. This price only makes sense when quality is non-negotiable — customer-facing AI features or anything where a wrong output carries real cost.
Grok 4.3 runs $1.25 input / $2.50 output per million tokens, with costs doubling past 200,000 input tokens. A meaningful reduction from Claude and useful for applications that do not need peak coding accuracy.
MiniMax M3 lists at $0.60 input / $2.40 output per million tokens. At the current 50% promotional discount, that falls to approximately $0.30 input / $1.20 output. Once open weights land on Hugging Face, self-hosting brings the cost down to infrastructure alone.
For context: running 100 million output tokens per month costs roughly $2,500 with Claude Opus 4.8, $250 with Grok 4.3, and about $120 with MiniMax M3 at promotional pricing.
Which model handles long context and video best?
All three support 1M token context windows, but MiniMax M3's MSA architecture is purpose-built for this scale: over 9x faster prefill means sending a 1M token document takes seconds rather than minutes. Grok 4.3 doubles its per-token cost past 200,000 tokens — worth factoring into long-context budgets.
For video, Grok 4.3 stands alone: it accepts up to five minutes of native video at 1080p. If your SaaS product involves analyzing user-uploaded video, screen recordings, or product demos, no other model in this comparison touches it. Claude Opus 4.8 and MiniMax M3 handle images, not video.
My honest take on which model fits your team
For customer-facing AI features where errors are costly: Claude Opus 4.8. The benchmark gap is large enough to matter in production.
For video analysis, science reasoning, or teams that want frontier capability at a lower monthly bill: Grok 4.3. The native video input is a genuine differentiator and the GPQA Diamond score of 90.1% shows it is not just cheap — it is strong on hard reasoning.
For cost-sensitive API integrations, exploratory builds, or teams open to self-hosting: MiniMax M3. The promotional pricing window will not last indefinitely, and the MSA architecture at 1M context is genuinely impressive in practice. Start here while the discount holds, and step up to Grok or Claude only for the workflows that require it.
Frequently asked questions
Is MiniMax M3 reliable for production use?
As of June 2026, independent benchmark verification is still pending for some MiniMax M3 results. The model shows strong performance on available evaluations, and the open-weight release adds credibility. Running it in parallel with a fallback model until you have validated it on your specific use cases is the right approach at this stage.
Does Grok 4.3 work well for general SaaS development tasks?
Grok 4.3 is solid for general reasoning and science tasks, but its coding average of approximately 47.3 on benchmark evals is noticeably lower than Claude Opus 4.8's 76.4. For typical SaaS development — writing functions, reviewing pull requests, debugging — the gap will show. Grok 4.3 earns its place where native video input or budget constraints are the deciding factor.
Which model has the best developer ecosystem right now?
Claude Opus 4.8 has the broadest ecosystem: it powers Cursor, Windsurf, and Claude Code, with deep integrations across developer tools. Grok 4.3 integrates well with the xAI API and SuperGrok apps. MiniMax M3's ecosystem is growing — available on OpenRouter now, with the Hugging Face release lowering the barrier for self-hosted deployments.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
