AI Tools
MiniMax M3 Review: The Open-Weight AI That Beats GPT-5.5 at 1/10th the Cost

MiniMax M3 launched on June 1, 2026 with a claim that would have sounded implausible six months ago: an open-weight AI model that beats GPT-5.5 and Gemini 3.1 Pro on a major coding benchmark, supports a 1 million token context window with native multimodal input, and starts at $0.30 per million input tokens at promotional pricing. After spending time with it and reviewing the architecture and available evaluations, I think the claim holds up — with one important caveat about how some benchmark results were measured.
Key takeaways
- MiniMax M3 scores 59% on SWE-Bench Pro, beating GPT-5.5 and Gemini 3.1 Pro on that evaluation as of June 2026
- It is the first open-weight model to combine frontier coding capability, a 1M token context window, and native image understanding in one package
- The MSA architecture delivers more than 9x faster prefill and 15x faster decoding at 1M context compared to the previous generation
- Promotional pricing: $0.30 per million input tokens, $1.20 per million output tokens (50% discount at launch)
- Open weights are releasing on Hugging Face within 10 days of the June 1 launch — enabling self-hosting
- Some benchmarks were run on MiniMax's own infrastructure with custom agent scaffolding; independent verification is still pending
What is MiniMax M3?
MiniMax is a Chinese AI company building frontier-level models since 2022. M3 is their most capable release — and notably, the one they chose to open-weight rather than keep closed. The decision to release weights on Hugging Face puts it in the same category as Llama and Mistral rather than GPT or Gemini: a model you can download, run, fine-tune, and deploy on your own infrastructure.
The technical architecture that makes M3 interesting is MiniMax Sparse Attention. Standard attention mechanisms scale quadratically with context length, which is why running a model at 1M tokens is expensive and slow. MSA cuts per-token compute at 1M context to one-twentieth of the prior generation. The result is more than 9x faster prefill and 15x faster decoding at that scale. For SaaS teams running long agentic loops or processing large documents, this is a meaningful practical advantage, not just a specification number.
How does MiniMax M3 perform on benchmarks?
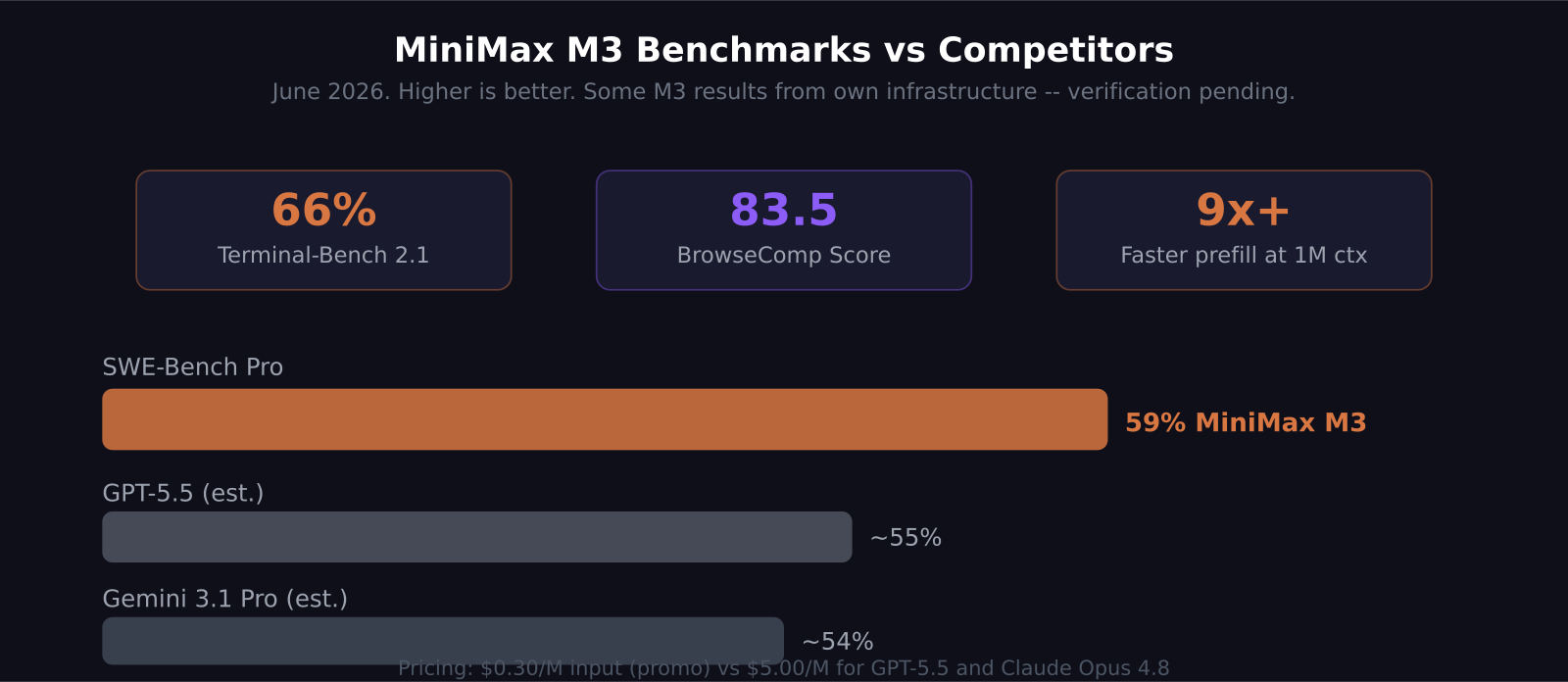
The headline number is 59% on SWE-Bench Pro — the harder, more recent version of the standard SWE-bench evaluation. GPT-5.5 and Gemini 3.1 Pro sit below 59% on this same benchmark. Claude Opus 4.8 is the closest comparison on coding, though it reports SWE-bench Verified rather than SWE-Bench Pro, complicating direct comparison.
On Terminal-Bench 2.1, M3 scores 66%. On BrowseComp, which tests web browsing and navigation in agentic setups, it scores 83.5. These are strong numbers for any model, and exceptional for an open-weight one.
The caveat: MiniMax ran several benchmarks on their own infrastructure with their own agent scaffolding rather than standard evaluation setups. Scaffold quality in agentic benchmarks can shift scores by 5-10 percentage points. Independent evaluations on standardized setups are still underway as of late June 2026. I treat the numbers as directionally accurate while waiting for third-party confirmation.
What can MiniMax M3 actually do?
Multimodal input is native, not an add-on. You send images alongside text and M3 reasons about the visual content. For SaaS applications that handle screenshots, documents, dashboards, or diagrams, this works out of the box.
Context handling at 1M tokens is where M3's architecture advantage becomes tangible in production. Sending a 1M token document — an entire codebase, a year of customer communications, a large technical specification — is fast with M3 in a way it is not with models that support 1M tokens but were not designed for that scale. The MSA architecture was built for this.
Structured output generation is clean and reliable, which matters for SaaS backends that depend on predictable JSON or schema-compliant responses. For workflows that use AI to populate databases, trigger automations, or return typed data, reliable structured output is a prerequisite worth testing on your specific schema.
How does the pricing compare to alternatives?
Full list price is $0.60 per million input tokens and $2.40 per million output tokens. At the current 50% promotional discount, that falls to $0.30 input and $1.20 output — below every other frontier-tier competitor by a significant margin.
For comparison: Claude Opus 4.8 charges $5.00 input / $25.00 output per million tokens. GPT-5.5 runs $5.00 input / $15.00 output. Grok 4.3, the budget-conscious frontier option, charges $1.25 input / $2.50 output. MiniMax M3 at promotional pricing is more than 4x cheaper on output tokens than Grok 4.3.
Once open weights are available on Hugging Face, self-hosting eliminates API costs for teams with the infrastructure to run it. For high-volume use cases generating hundreds of millions of tokens per month, the economics of self-hosting become compelling quickly.
Who should actually use MiniMax M3?
Developers and SaaS teams evaluating whether they can replace a more expensive model without sacrificing acceptable quality: M3 is worth testing immediately while promotional pricing holds. The API is live on OpenRouter, the context window means you do not need to chunk long inputs, and the barrier to evaluation is low.
Research and data teams working with large document sets: the 1M context with genuinely fast prefill is the practical reason to look at M3 specifically. Many models support 1M tokens in theory; M3 was built to make it fast in practice.
Teams considering self-hosting to reduce AI infrastructure costs long-term: the open-weight release changes the calculus. Once you can download and run M3 on your own hardware, the cost model shifts from per-token billing to infrastructure alone.
Teams that need Claude-level benchmark performance for high-stakes coding, or Grok-style native video input, should look elsewhere. M3 is not the answer for every use case. But as a cost-efficient, open-weight frontier model with a 1M context window and strong multimodal reasoning, it occupies a niche that nothing else currently fills.
Frequently asked questions
When are MiniMax M3 open weights actually available?
MiniMax announced weights would release on Hugging Face within 10 days of the June 1, 2026 launch. As of late June, the release is imminent or may already be live. Search for MiniMax M3 on Hugging Face for the current download link and license terms.
How does MiniMax M3 compare to Llama and other open-weight models?
MiniMax M3 operates at a substantially higher capability tier than current Llama releases. Its 59% SWE-Bench Pro score puts it well above any available Llama version on coding. The 1M context window and native multimodal input are not features available in the Llama family. For teams currently using Llama as a cost-saving option, M3 represents a meaningful step up in capability at still-competitive pricing.
Is MiniMax M3 safe to deploy in production?
MiniMax has published standard safety documentation and the model has been evaluated on common safety benchmarks. Like all frontier models, it benefits from system prompts that constrain behavior for your specific use case. Running it with monitoring in production until you have validated its behavior on your specific inputs is the right approach — the same advice applies to any model, open or closed.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
