AI Tools
Kimi K2.6 vs DeepSeek V4 vs Qwen3.5: Which Chinese Open-Source AI Wins in 2026?

The three strongest open-weight AI models available right now are all Chinese, and they cost anywhere from 6 to 35 times less than GPT-5.5 per million tokens. Kimi K2.6 from Moonshot AI, DeepSeek V4-Pro from DeepSeek, and Qwen3.5-397B from Alibaba have each reached benchmark scores that were exclusive to expensive closed models just six months ago. If you are building a SaaS product, running an AI pipeline, or trying to cut your inference bill, the Chinese open-weight tier is now impossible to ignore.
Key takeaways
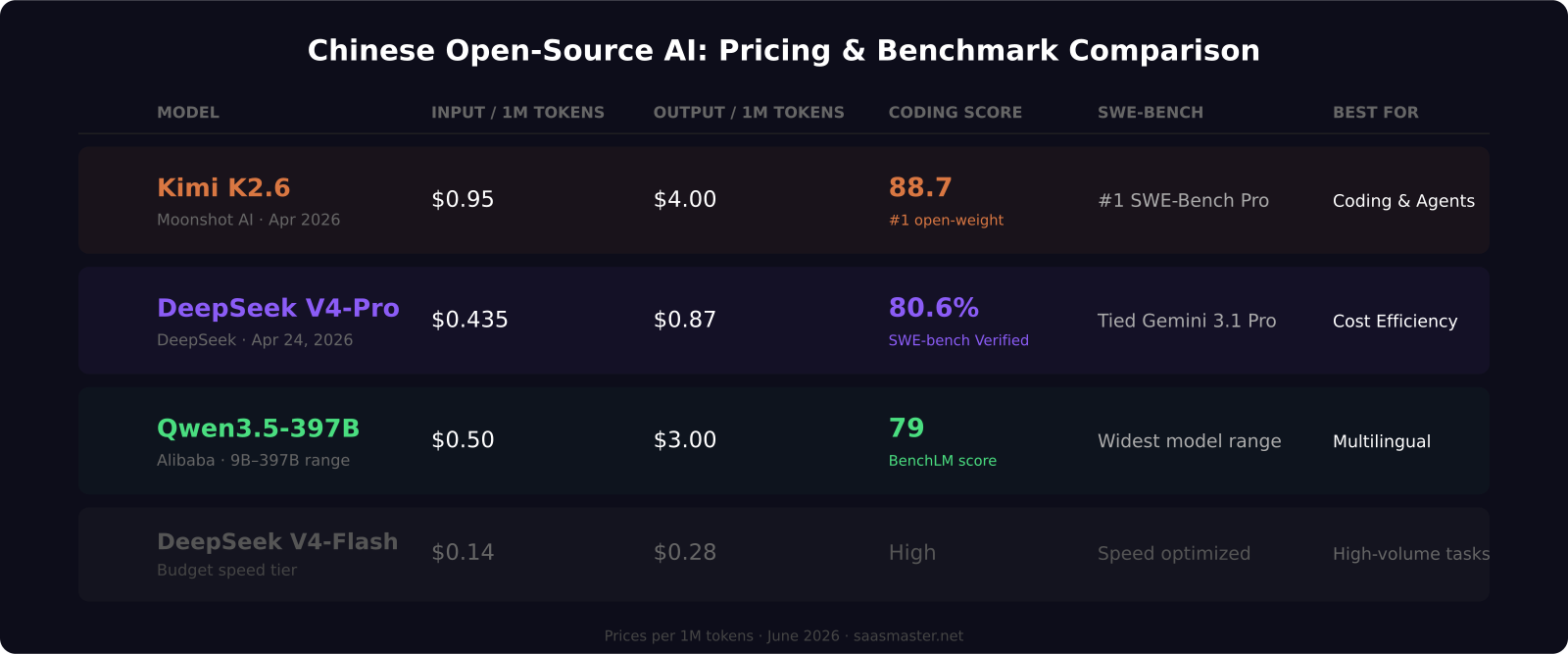
- Kimi K2.6 is the first open-weight model to beat GPT-5.4 on SWE-Bench Pro, with an 88.7 coding benchmark score
- DeepSeek V4-Pro costs $0.435 per million input tokens — roughly 23 times cheaper than Claude Opus 4.8 at $5 per million
- DeepSeek V4-Pro-Max leads on SWE-bench Verified at 80.6%, tied with Gemini 3.1 Pro
- Qwen3.5-397B covers model sizes from 9B to 397B and leads on multilingual tasks
- Five competitive models now sit within half a point of each other on SWE-bench Verified while spanning a 20x price range
What happened to open-source AI in 2026
This time last year, the working assumption among Western developers was that Chinese models were interesting but a tier below GPT-4o and Claude. That assumption is now outdated.
Between January and June 2026, three Chinese labs released models that have overtaken every Western open-weight competitor and in some benchmarks now challenge the best closed models in the world. Kimi K2.6 arrived in April 2026. DeepSeek V4 landed April 24. Qwen3.5 from Alibaba continued its rapid release cadence. Each model competes on different strengths, which is what makes this comparison genuinely useful rather than just a ranking exercise.
The shift also has a practical dimension: because all three are open-weight, developers can self-host them on their own infrastructure. Privacy concerns about Chinese-origin API providers dissolve when the model weights are running on your own servers.
Kimi K2.6: the open-weight coding champion
Moonshot AI released Kimi K2.6 in April 2026 as an open-weight model, available through the official Kimi API, DeepInfra, and OpenRouter, as well as via self-hosted deployment.
The result that got the most attention was this: Kimi K2.6 became the first open-weight model to beat GPT-5.4 on SWE-Bench Pro, the most demanding coding benchmark for real-world software engineering tasks. Its overall coding score on BenchLM sits at 88.7, the highest of any open model currently tracked. On agent swarms and long autonomous runs, Kimi K2.6 is consistently the top open-weight choice.
Pricing on the official Kimi API: $0.95 per million input tokens for cache-miss calls, dropping to $0.16 per million for cached inputs. Output is $4.00 per million tokens. On DeepInfra, prices run slightly lower at $0.75 input and $3.50 output. The cache-hit pricing is roughly 6 times cheaper than a cache-miss across the entire K2 family, which means prompt caching should be the first optimization you implement if you are building on Kimi.
DeepSeek V4: cheapest with the biggest context window
DeepSeek V4 launched April 24, 2026, in two variants. V4-Flash is the speed-optimized model for high-volume workloads: $0.14 per million input tokens and $0.28 per million output. V4-Pro is the flagship, with a 1.6 trillion parameter Mixture-of-Experts architecture, a 1 million token context window, and pricing at $0.435 per million input and $0.87 per million output.
DeepSeek V4-Pro-Max currently leads BenchLM's Chinese model leaderboard at a score of 87. On SWE-bench Verified, V4-Pro-Max hits 80.6% — tied with Gemini 3.1 Pro — which is the highest score among all open-weight models available today. For LiveCodeBench and tasks requiring a massive context window, DeepSeek V4-Pro is consistently the top-ranked choice.
The cost comparison is what stops most developers in their tracks. V4-Flash at $0.28 per million output tokens is roughly 17 times cheaper than Claude Opus 4.8 and 7.7 times cheaper than Qwen3.5-Plus on typical chatbot workloads. For SaaS products where inference cost is a real monthly budget line, DeepSeek V4-Flash is the model I would evaluate first.
Qwen3.5: the multilingual workhorse with the most flexibility
Alibaba's Qwen3.5 is not a single model — it is a family ranging from 9 billion parameters to 397 billion. The flagship Qwen3.5-397B reaches a BenchLM score of 79 in reasoning mode. Qwen3.5-Plus is priced at $0.50 per million tokens for standard prompt lengths, stepping up for longer context windows.
What makes Qwen distinctive from the other two is breadth. It has the widest multilingual support among Chinese open models, making it the practical default for any application that needs to handle Arabic, Indonesian, Portuguese, Japanese, or Spanish at production scale. The range of model sizes also gives it unique deployment flexibility — if you need a model that runs on a single consumer GPU for edge use cases, there is a 9B Qwen variant for that. If you need the full frontier-quality reasoning model, the 397B handles it.
Qwen3-Coder-Next deserves a separate mention: it achieves the best efficiency-per-active-parameter of the three families for coding tasks, which matters when you are running millions of inference calls and want to minimize compute cost without sacrificing too much quality.
Which model should you use for what
For coding and agentic pipelines where you need maximum capability, Kimi K2.6 is the strongest open-weight option available right now. Its SWE-Bench Pro score leads the entire open category and it is well-suited to multi-step autonomous workflows, code review agents, and long development tasks.
For maximum cost efficiency on high-volume tasks, DeepSeek V4-Flash is the answer at $0.14 input and $0.28 output per million tokens. It handles coding and general reasoning at 80 to 90 percent of the quality of the flagship models while costing a fraction as much. On a SaaS product doing tens of millions of completions per month, the savings are significant enough to justify a dedicated evaluation.
For anything involving multiple languages or mixed deployment scenarios where you need to swap between model sizes, Qwen3.5 gives you the most options within one consistent API and the strongest multilingual performance of the three.
Is the Chinese AI origin a real concern
Some developers flag concerns about data routing when using Chinese-origin model APIs. That concern is worth taking seriously and the right answer depends on your use case. For regulated industries, healthcare data, or applications where user data sovereignty is a hard requirement, self-hosting the open-weight versions removes the issue entirely. All three models are genuinely open-weight and can run on your own infrastructure.
For general SaaS building, benchmark evaluation, internal tooling, or any workload without sensitive data constraints, the hosted APIs are fast, well-documented, and the cost advantages over Western closed models are large enough to make the evaluation worth doing.
My take
I have tested all three in workflow pipelines, and the honest answer is that the right choice depends entirely on what you are optimizing for. Kimi K2.6 is where I would start for agentic coding work. DeepSeek V4-Flash is what I would reach for when running something at scale where cost matters. Qwen3.5 is the deployment for any product that needs strong multilingual coverage alongside frontier-quality reasoning.
The broader shift matters more than any individual model: the open-weight tier has genuinely closed the gap with the frontier. That was not true at the start of 2026. It is true now, and the pricing gap between open-weight and closed-source has never been wider.
Frequently asked questions
Is Kimi K2.6 free to use?
Kimi K2.6 is available with usage limits on OpenRouter's free tier. For production access, the official Kimi API charges $0.95 per million input tokens on cache-miss and $4.00 per million output tokens. Cached input drops to $0.16 per million, making prompt caching the single most important cost lever for high-volume use.
Is it safe to use DeepSeek V4 for business data?
DeepSeek V4 is open-weight and can be self-hosted on your own infrastructure, which removes concerns about data routing through external servers. For cloud API use, review DeepSeek's data processing agreement against your jurisdiction's requirements before handling regulated or sensitive user data.
How does Qwen3.5 compare to Llama 4 on coding?
Qwen3.5-397B outperforms Llama 4 405B on most coding and reasoning benchmarks in the BenchLM rankings. On multilingual tasks specifically, Qwen3.5 has a meaningful advantage over the Llama family due to its broader language training coverage.
Was this article helpful?
SaaS Master
Creator behind SaaS Master — tutorials, walkthroughs, reviews, and explainers that help SaaS, AI, and WordPress products get understood and chosen. Writing here about the tools, trends, and tactics that actually move the needle. Work with me →
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master