AI Tools
Qwen 3.7-Max vs MiniMax M2.7: Which Chinese Agentic AI Model Should SaaS Teams Use in 2026?
In short
MiniMax M2.7 costs 10x less per token than Qwen 3.7-Max. Here is the real pricing, benchmark, and agentic performance breakdown for SaaS teams in 2026.

MiniMax M2.7 costs about ten times less per token than Qwen 3.7-Max, and for most agentic coding tasks it gets you close to the same result. If you are picking a Chinese frontier model to run automation on this month, that price gap is the number that should shape your decision first, not the benchmark screenshots everyone shares. I spent the week running both models against real SaaS workflows, ticket triage, a code review agent, and a long multi-step research task, and the honest answer is that the right model depends on what you are actually building.
Key takeaways
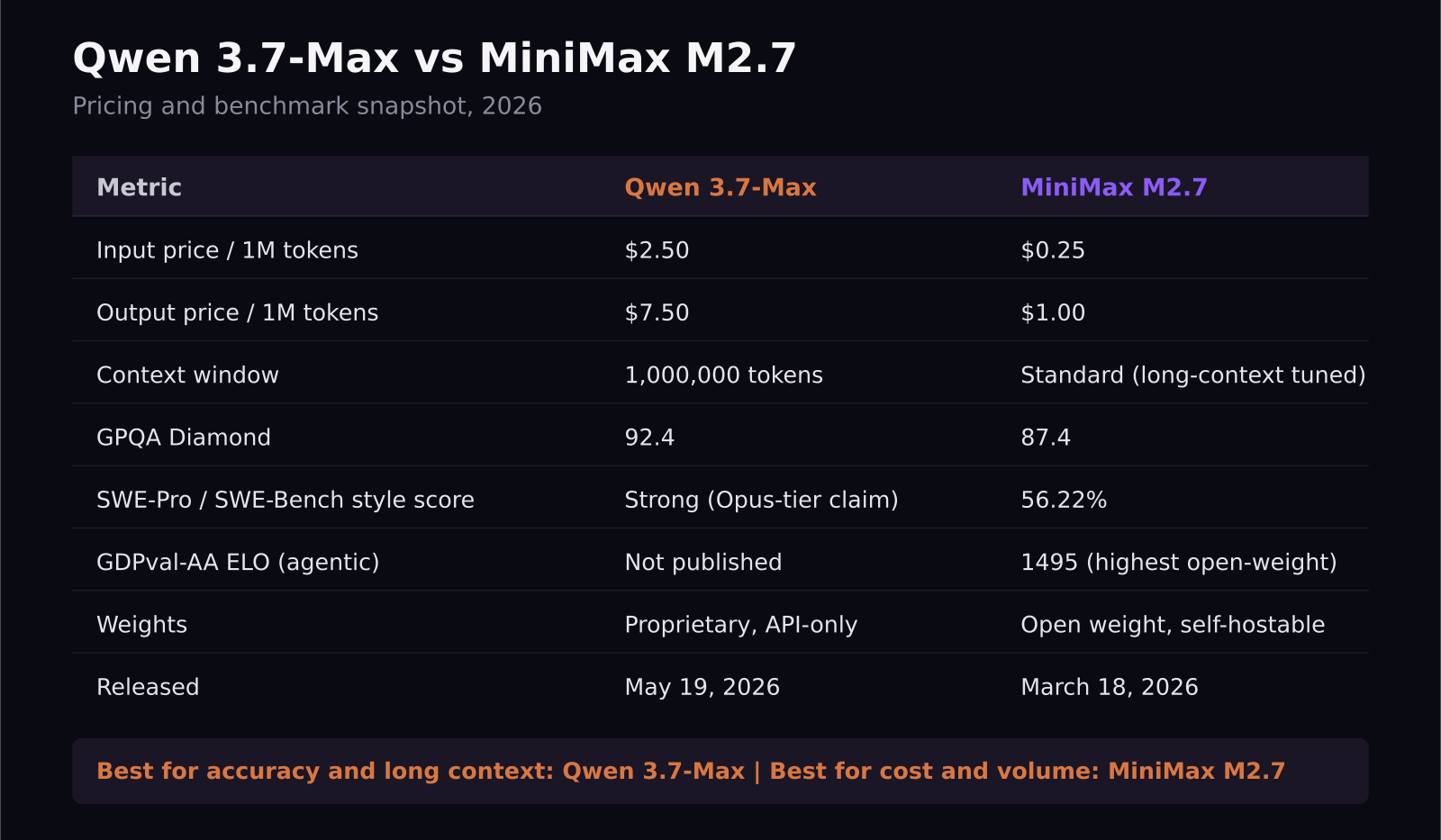
- Qwen 3.7-Max launched May 19, 2026 and is built specifically for long-horizon agent workflows, with a 1 million token context window and a demonstrated 35-hour autonomous coding run that fired 1,158 tool calls.
- MiniMax M2.7, released March 18, 2026, costs 0.25 dollars per million input tokens and 1.00 dollar per million output tokens direct from MiniMax, versus 2.50 and 7.50 dollars for Qwen 3.7-Max, roughly a 10x gap.
- On raw intelligence benchmarks Qwen edges ahead, 92.4 on GPQA Diamond versus MiniMax's 87.4, but MiniMax M2.7 posts the highest GDPval-AA ELO score, 1495, among open-weight models.
- MiniMax ships open weights you can self-host or run through low-cost providers; Qwen 3.7-Max is proprietary and API-only, though it supports both OpenAI and Anthropic SDK formats.
- For most SaaS teams running high-volume agent workflows, MiniMax M2.7 is the more sustainable default. Save Qwen 3.7-Max for the specific tasks where long-context accuracy is worth the premium.
What are Qwen 3.7-Max and MiniMax M2.7, really?
Qwen 3.7-Max is Alibaba's newest flagship, announced at the Alibaba Cloud Summit in Hangzhou and framed almost entirely around agent workflows rather than chat. Alibaba calls it the Agent Frontier, and the entire release is built around long-horizon autonomous execution: give it a task, and it keeps working, calling tools, checking its own output, and correcting course over many hours without a human in the loop. It carries a 1 million token context window, which matters when an agent needs to hold an entire codebase, a long support thread, or a full research corpus in memory at once.
MiniMax M2.7 comes from a different design philosophy. It is a self-evolving model built on a mixture-of-experts architecture, trained across more than 200,000 real-world environments covering over 10 programming languages. MiniMax has leaned hard into efficiency: the model is small in active parameters relative to its total size, which is exactly why it can be priced so much lower while still holding its own on agentic benchmarks.
Which is cheaper, Qwen 3.7-Max or MiniMax M2.7?
MiniMax M2.7, by a wide margin. Direct from MiniMax, it runs 0.25 dollars per million input tokens and 1.00 dollar per million output tokens. Route it through OpenRouter and it drops further, to roughly 0.18 and 0.72 dollars. Qwen 3.7-Max lists at 2.50 dollars input and 7.50 dollars output per million tokens through Alibaba Cloud Model Studio, though some gateway providers offer it closer to 1.25 and 3.75 dollars.
Run the math on a realistic agent workload, something like 50 million input tokens and 10 million output tokens a month, and Qwen 3.7-Max lands around 200 dollars while MiniMax M2.7 lands around 22 dollars on direct pricing. That is not a rounding error. For any team running agents continuously rather than answering occasional chat queries, token cost compounds fast, and MiniMax's efficiency-first design starts to look less like a budget option and more like the obvious default.
Which model wins on benchmarks?
It depends which benchmark you care about. Qwen 3.7-Max scores 92.4 on GPQA Diamond and 97.1 on HMMT February 2026, both the highest in its comparison group, and Alibaba's own testing shows it winning or tying Claude Opus 4.6 on most evaluations, with the biggest gains showing up in long-context retrieval, math reasoning, and multilingual tasks.
MiniMax M2.7 does not chase the same leaderboard. It sits around the 94th percentile on general intelligence and GPQA, 81st percentile on coding, and scores 56.22 percent on the SWE-Pro benchmark, which MiniMax says nearly matches Opus-level performance. Where it actually pulls ahead is agent-specific evaluation: a GDPval-AA ELO of 1495, the highest recorded among open-weight models, plus a 97 percent skill adherence rate across 40 complex, multi-step skill tests. In plain terms, Qwen is stronger at knowing things and reasoning through hard problems; MiniMax is stronger at reliably finishing multi-step jobs without drifting off task.
Which one handles long-running agent tasks better?
This is where Qwen 3.7-Max's design choices show up most clearly. That 1 million token context window and the 35-hour autonomous coding demonstration were not marketing flourishes, they reflect a model built to stay coherent across genuinely long jobs, the kind of task where an agent needs to remember a decision it made six hours earlier. If you are building something like an autonomous QA agent that needs to hold an entire test suite and change history in context, Qwen has a real structural advantage.
MiniMax M2.7 was trained specifically to improve on this exact weakness relative to its predecessor, M2.5, and MiniMax reports a meaningful jump in what it calls OpenClaw usage, its internal term for sustained agentic tool use. It will not match Qwen's raw context ceiling, but for the vast majority of SaaS automation tasks, ticket routing, PR review, customer research summarization, the gap will not be the thing that breaks your workflow. Token cost usually breaks it first.
Open weights vs proprietary — which matters more for your SaaS stack?
MiniMax ships its models with open weights, which means you can self-host on your own GPUs, fine-tune on proprietary data without sending it to a third party, or run it through whichever low-cost inference provider offers the best rate that week. That flexibility is a genuine moat if your team has any DevOps capacity at all, or if you are handling data that cannot leave your infrastructure for compliance reasons.
Qwen 3.7-Max is proprietary and API-only. The one meaningful concession Alibaba made is compatibility: the model works with both the OpenAI API spec and the Anthropic API spec, so if your codebase is already wired up to call Claude or GPT, swapping in Qwen is closer to a config change than a rewrite. That matters more than it sounds, because most of the switching cost with a new model is usually the integration work, not the model itself.
My take: which one should you actually use?
I would default to MiniMax M2.7 for anything running at volume, internal automation, customer-facing agents that fire constantly, or background research jobs where a 10x cost difference adds up to real money by the end of the month. It is not the smartest model on the market, but it is close enough on agentic tasks that the gap rarely shows up in the output quality, and it is open enough that you are not locked into one vendor's pricing decisions.
I would reach for Qwen 3.7-Max specifically when the task genuinely needs the extra context headroom or the extra reasoning ceiling, a single very long-running agent job, a complex multilingual support workflow, or a task where getting it right the first time is worth paying a premium for. Most SaaS teams do not need to pick one model company-wide. The realistic setup is MiniMax as your default agent runtime, with Qwen called in for the small slice of jobs where it earns its price.
Frequently asked questions
Is MiniMax M2.7 open source?
Yes. MiniMax publishes open weights for its M-series models, including M2.5 and M2.7, which are available on Hugging Face and can be self-hosted or run through third-party inference providers, unlike Qwen 3.7-Max, which is API-only.
Can I use Qwen 3.7-Max with the Anthropic SDK?
Yes. Qwen 3.7-Max is compatible with both the OpenAI API spec and the Anthropic API spec, so teams already using Claude's client libraries can point them at Qwen 3.7-Max through Alibaba Cloud Model Studio or a gateway provider with minimal code changes.
Which model is cheaper for high-volume agent workloads?
MiniMax M2.7 is roughly 10 times cheaper per token than Qwen 3.7-Max, at 0.25 and 1.00 dollars per million input and output tokens versus Qwen's 2.50 and 7.50 dollars, making MiniMax the more cost-effective choice for any workflow that runs agents continuously rather than occasionally.
Was this article helpful?
Jorge Aguilar
Founder & Creator, SaaS Master
Producing SaaS and AI product videos since 2019 — 800+ videos for 200+ brands, covering tutorials, demos, walkthroughs, and explainers. Writing here about the tools, trends, and tactics that actually move the needle. LinkedIn · About · Work with me
Want your product explained this clearly — in video?
Tutorials, walkthroughs, reviews, and shorts for SaaS, AI, and WordPress products.
Work With SaaS Master
